

 NVIDIA Rubin CPX Shot
NVIDIA Rubin CPX Shot
If that title seems strange, then wait until you see what NVIDIA is launching. It is a bit of a paradigm shift that actually makes sense, but it is a big shift from homogeneous GPU racks and clusters. With the NVIDIA Rubin CPX, NVIDIA is adding multiple GDDR7 memory GPUs alongside its 2026 Rubin HBM GPUs in the same NVL144 racks. Effectively, the big HBM Rubin GPUs are being equipped with GDDR7 Rubin CPX GPUs as co-processors.
NVIDIA Rubin CPX is the 128GB GDDR7 Rubin GPU
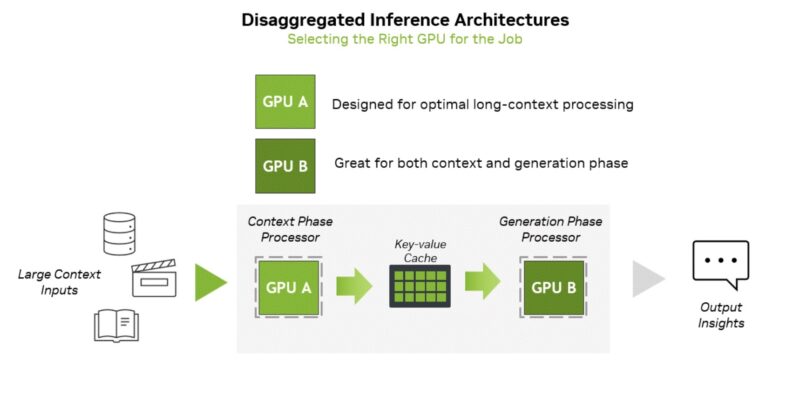
The basic observation of the CPX is that today’s LLMs have different stages: Pre-fill and decode. NVIDIA is using this in terms of a Context Phase and a Generation Phase. Transitioning between the two requires moving the key-value or KV cache. Generally, the Context phase (Pre-fill) is compute-limited while the Generation phase is more memory-limited. Since we are in the era of building clusters with hundreds of thousands of GPUs and moving to millions, there is enough workload and scale to start splitting these tasks among two more optimized architectures, rather than just running them through GPUs with massive HBM pools.
 NVIDIA Context And Generation September 2025
NVIDIA Context And Generation September 2025
What is more, that Context or Pre-fill phase is becoming a bigger challenge especially with very long context windows and video. This is the opportunity that NVIDIA is addressing with the Rubin CX.
The Rubin CX has 30PFLOPS of NVFP4 performance along with 128GB of GDDR7. NVIDIA is claiming three times the exponent operations of the GB300. Since one of the key drivers is also video workloads, there are four NVENC/ NVDEC engines.
Here is the exciting part, these are also designed for heterogeneous racks. Here we can see a Vera Rubin NVL144 CPX compute tray. There are four Rubin packages and two Vera Arm CPUs. Then there are eight Rubin CPX packages (NVIDIA says these are monolithic die.) Finally, there are eight NVIDIA ConnectX-9 which should be something like 1.6Tbps NICs (ConnectX-7 is 400G, ConnectX-8 is 800G.) That would mean 12.8Tbps of networking coming off each compute tray or the throughput of an entire Broadcom Tomahawk 3 switch/ one fourth of a current NVIDIA Spectrum-4 SN5610 switches that we see in current generation AI clusters, and that just happened to arrive in the STH lab for our massive networking push.
 NVIDIA Vera Rubin NVL144 CPX
NVIDIA Vera Rubin NVL144 CPX
So with this one would get 144 Rubin standard packages, then 144 Rubin CPX in a rack. NVIDIA said there would be other options like a sidecar. Perhaps the more interesting part is that NVIDIA is using its prowess with making a big monolithic GDDR GPU, something that AMD and Intel have done less of as they focus more on volume segments. It will be interesting to see where the Rubin CPX finds itself outside of the NVL144 racks.
Since the NVIDIA Rubin NVL144 CPX racks are designed to with a lot of future technology, they are targeted more for the end of 2026, so this is over a year away.
Final Words
At STH, we have both an 8-GPU HGX B200 system setup, we have just reviewed three AMD Instinct MI325X systems, and have done multiple pieces on L40S/ RTX Pro 6000 Blackwell/ H200 NVL card systems recently. We also have a lot of platforms ranging from the Apple Mac Studio M3 Ultra 512GB (a VERY good box) to several AMD Ryzen AI Max+ 395 128GB systems and even the recent Jetson AGX Thor 128GB machine. The idea of building a co-processor around lower-cost memory makes a lot of sense. NVIDIA also has the ability to provide the software stack to make this happen in practice.
Perhaps the other neat insight is that we have companies focused on different types of AI inference accelerators. One has to wonder if this pushes other architectures to come about outside of NVIDIA as they look to challenge NVIDIA’s 2026/ 2027 plans.