
Multimodal Large Language Models (MLLMs) currently face a significant challenge, namely the high computational cost associated with processing visual information, as image inputs increase the number of tokens the model must handle. To address this, Long Cui, Weiyun Wang, and Jie Shao, along with colleagues at their respective institutions, introduce Visual Consistency Learning (ViCO), a training strategy that allows MLLMs to dynamically adjust the number of visual tokens used based on an image’s semantic complexity. This innovative approach employs multiple processing pathways, each compressing images to varying degrees, and then selects the most appropriate pathway during processing, reducing computational load by up to 50% without sacrificing performance on tasks requiring perception, reasoning, or Optical Character Recognition. By adapting to semantic content rather than simply image resolution, ViCO represents a substantial step towards more efficient and practical MLLMs, paving the way for broader applications of these powerful models.
Dynamic Resolution Routing For Vision Models
This research introduces ViCO, a new training strategy for large vision-language models, such as the InternVL3. 5 series, designed to improve efficiency without sacrificing performance. ViCO achieves this by dynamically adjusting the resolution, or number of tokens, used to represent different parts of an image. Less important areas are compressed to fewer tokens, while crucial details retain higher resolution, allowing models to process images more quickly and with reduced computational cost. The team demonstrated that ViCO significantly reduces computational demands without substantial performance loss across a variety of multimodal benchmarks.
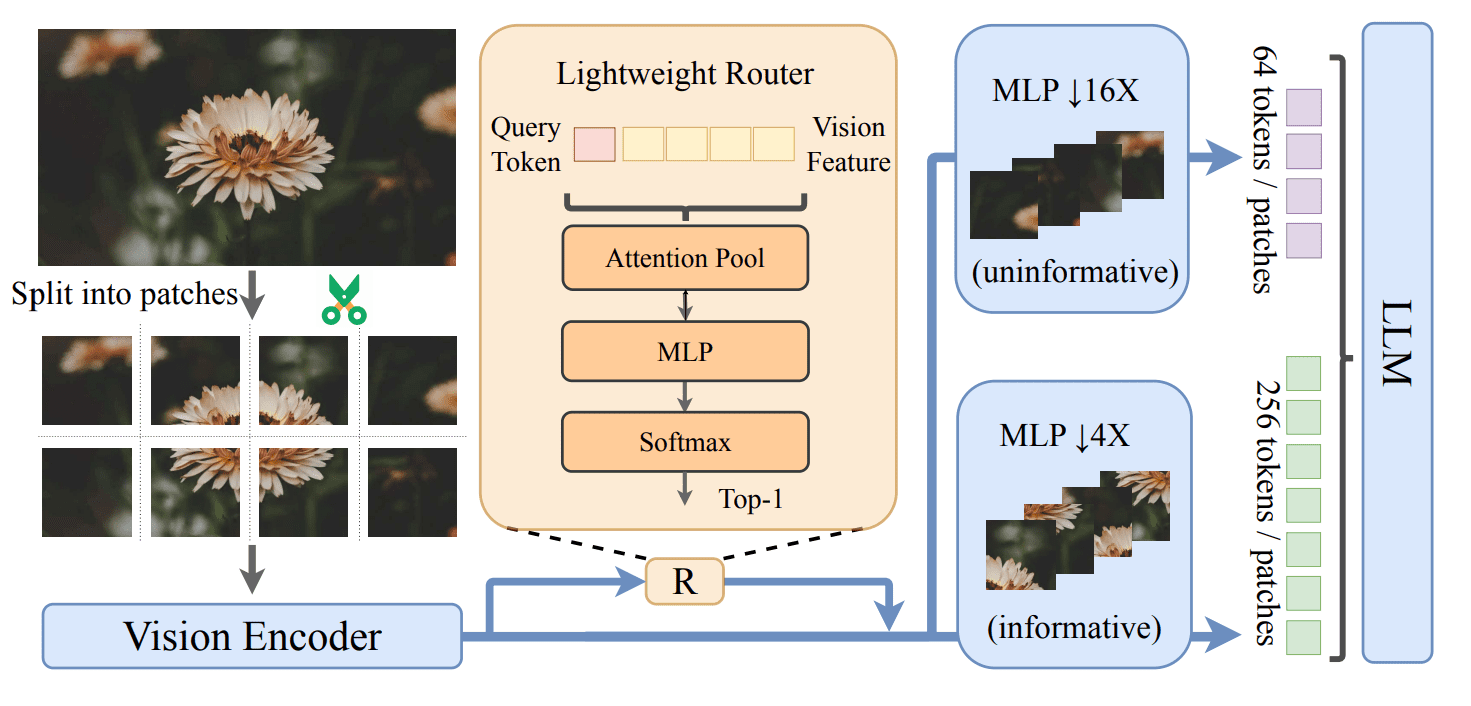
Visualizations reveal how the system intelligently compresses image patches, focusing detail on important areas and simplifying less critical regions, providing insight into the decision-making process of the router. The results demonstrate that ViCO effectively balances computational efficiency with maintained accuracy, offering a promising approach for deploying large vision-language models in resource-constrained environments. This training strategy enables models to represent images with varying complexity using different numbers of visual tokens. The core of this approach employs multiple image compression techniques, effectively downsampling visual tokens based on image content, allowing for more efficient processing without losing crucial information. During training, the team minimized discrepancies in model responses generated using these different compression levels. This consistency training ensures the model maintains accuracy even with highly compressed images, enhancing robustness and performance.
To further refine this process, scientists introduced the Visual Resolution Router, which automatically selects the appropriate compression rate for each image patch. This router analyzes each patch and allocates more tokens to areas containing complex information, while simpler patches receive fewer. Experiments demonstrate that ViCO can reduce the number of visual tokens by up to 50% while maintaining the model’s capabilities in perception, reasoning, and optical character recognition. The core of this work lies in enabling models to represent images with varying numbers of visual tokens, adapting to the semantic complexity within each image. The team introduced a Visual Resolution Router that intelligently allocates tokens to different image patches, assigning more to areas containing complex information and fewer to simpler regions. Experiments demonstrate that ViCO can reduce the number of visual tokens required to process images by up to 50%, while maintaining the model’s ability to accurately perceive, reason, and perform optical character recognition.
This reduction in token count directly translates to improved processing speed, with substantial increases in first token throughput across various model scales within the InternVL3. 5 series. The training process involves two key stages: consistency training, which minimizes differences in model responses when using images with different compression levels, and router training, which utilizes the Visual Resolution Router to automatically select the appropriate compression rate for each image patch. Researchers achieved this by employing multiple image compression ratios during training and introducing an image router that automatically selects the appropriate compression level for each image patch during inference. Experimental results demonstrate that this approach successfully reduces the number of vision tokens required to process images by up to 50%, without compromising the model’s abilities in perception, reasoning, and optical character recognition. Ablation studies further validate the effectiveness of each component of the proposed method, confirming its practical benefits for large-scale multimodal models. The researchers acknowledge that the effectiveness of visual token compression varies with text input length, with shorter inputs benefiting more from higher compression ratios. Future work may explore further optimization of compression strategies and their application to a wider range of multimodal tasks, ultimately contributing to the development of more efficient and scalable multimodal large language models.