

I am someone who believes that AGI (Artificial General Intelligence) could change the world, but also someone who thinks that LLMs are not the right path there, morally or technically. In an OpEd today in The New York Times, I argue that at least for now, AGI is maybe not the right near-term goal:
The crux of this essay, which draws on positive examples from Waymo and GoogleDeepmind is this:
[LLMs] have always been prone to hallucinations and errors. Those obstacles may be one reason generative A.I. hasn’t led to the skyrocketing in profits and productivity that many in the tech industry predicted. A recent study run by M.I.T.’s NANDA Initiative found that 95 percent of companies that did A.I. pilot studies found little or no return on their investment. A recent financial analysis projects an estimated shortfall of $800 billion in revenue for A.I. companies by the end of 2030.
If the strengths of A.I. are to truly be harnessed, the tech industry should stop focusing so heavily on these one-size-fits-all tools, and instead concentrate on narrow, specialized A.I. tools engineered for particular problems
…
Right now, it feels as if Big Tech is throwing general-purpose A.I. spaghetti at the wall and hoping that nothing truly terrible sticks. As the A.I. pioneer Yoshua Bengio has recently emphasized, advancing generalized A.I. systems that can exhibit greater autonomy isn’t necessarily aligned with human interests. Humanity would be better served by labs devoting more resources on building specialized tools for science, medicine, technology and education.
Hope you have time to read the whole essay; it’s short and sweet, touching on some deep ideas in cognitive science and why they matter so much in the real world, all in a remarkably readable way.
(Shout out to my editor Neel Patel, for helping make the essay read so elegantly!)
§
By coincidence, though, that’s not the only new essay I have out today about AGI. The other one (in which I played just a tiny role) is with AI safety researcher Dan Hendrycks and a large cast of of 30-some eminent researchers, including Yoshua Bengio, in which we try to define AGI.

§
We land on a definition of AGI (“AGI is an AI that can match or exceed the cognitive versatility and proficiency of a well-educated adult”) that is actually extremely close to what I proposed here a few years ago (“any intelligence … that is flexible and general, with resourcefulness and reliability comparable to (or beyond) human intelligence”), based on conversations with the originators of the term, Shane Legg and Ben Goertzel. (Peter Voss, the other coiner of the term, signed on afterwards.)
I don’t agree with every detail of the new paper (that’s not practical when you have over 30 authors), but signed on because I strongly support the paper’s goal of trying better articulate what it means to have a mind with the flexibility and generality of a human mind.
The main alternative — definitions of AGI that are in terms of economic criteria like profits (AGI as being $100 billion in profits) or percentage of jobs displaced— seem to me to be fundamentally misguided. Pure profits is obviously a nonstarter (iPhones have earned Apple hundreds of billions in profits but that doesn’t make them AGI). But even the second is a bit of red herring, mixing together facts about capital and wages with cognition. Fundamentally, efforts to define AGI in economic terms distract from the core cognitive issues about what it means to build a powerful mind.
The new paper, which tries to break down cognition into a wide number of subareas, is a welcome corrective.
In particular it tries to break down cognition into many facets. Cognition is not one thing but many, as Chaz Firestone and Brian Scholl once wrote. This is one attempt to articulate that, and as the paper notes, current techniques capture only a fraction of what ultimately needs to be captured:
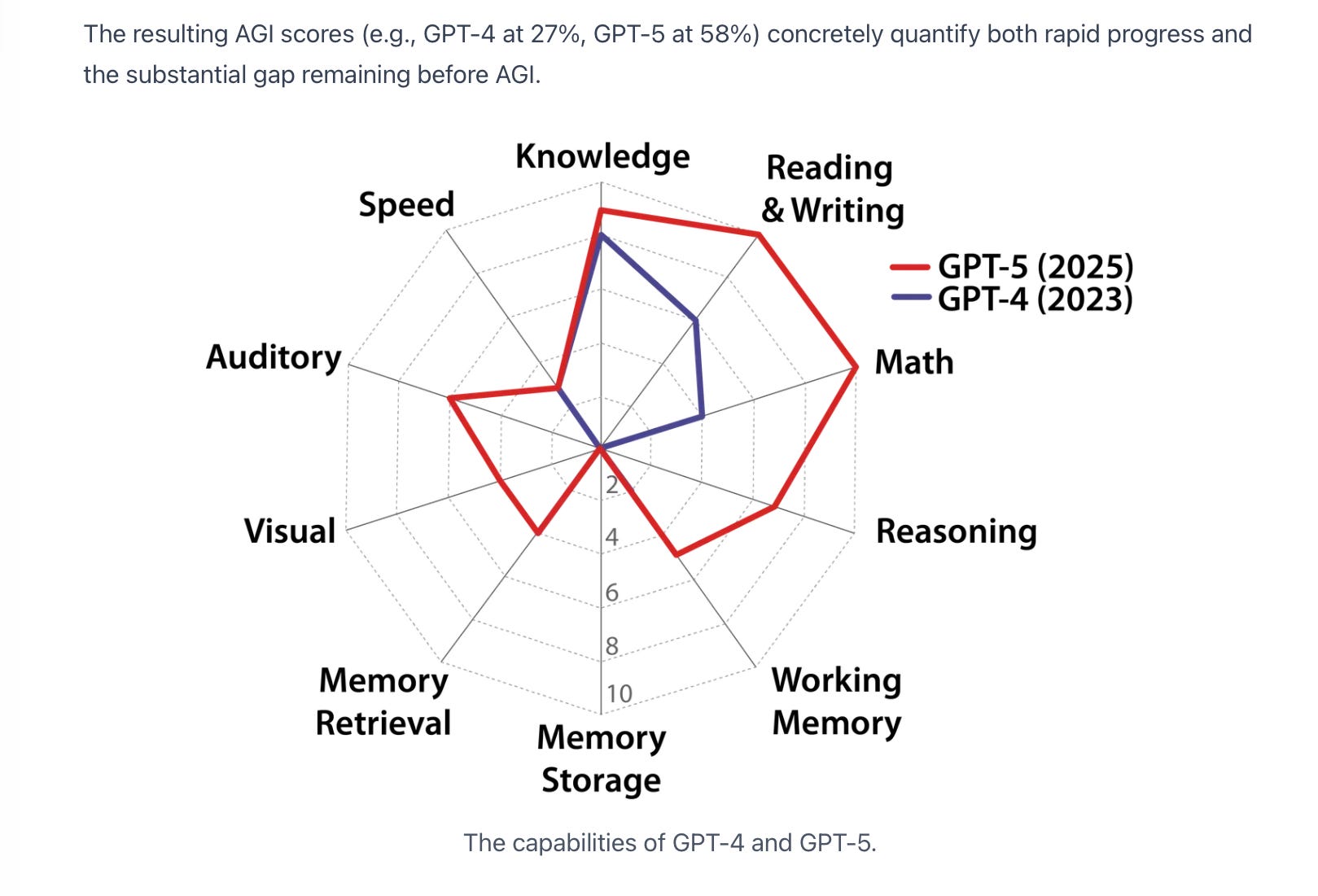
One could argue with this breakdown, but it’s a good opening bid. I expect lots of commentaries to take other cuts on the problem, and I am glad this will open those conversations. (I am personally in no way committed to the particulars.)
The weakness in the paper is that is that is built on a bunch of benchmarks, and we all known benchmarks can be gamed. There are also a number of fairly arbitrary decisions that may not stand the test of time (e.g., how much weight to put on each submeasure in the many tests that are aggregated). The whole thing should be viewed as evolving, with future measures replacing existing ones as researchers devise better benchmarks — and not as a static checklist. Our current understanding of how to assess intelligence is just a moment in time. I hope the paper won’t accidentally enshrine that particular moment in perpetuity.
As such I certainly don’t think our paper should be seen as the last word here, but I think it does a great job launching an important discussion.
Happy reading!