

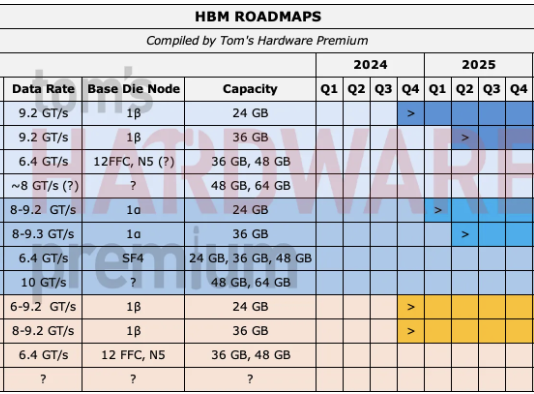
Tom’s Hardware Premium Roadmaps
(Image credit: Future)
DeepSeek has released a new technical paper, which details a new method for how new AI models might rely on a queryable database of information committed to system memory. Named “Engram”, the conditional memory-based technique achieves demonstrably higher performance in long-context queries by committing sequences of data to static memory. This eases the reliance on reasoning for AI models, allowing the GPUs to only handle more complex tasks, increasing performance, and reducing the reliance on high-bandwidth memory (HBM).
Released on the company’s GitHub page, Engram hopes to address how the company might be able to curb the reliance on more complex memory types and instead commit a knowledge library to a more common system memory standard, such as CXL.
You may like
Reducing the reliance on HBM
The ongoing reliance on high-bandwidth memory for AI accelerators is something that even Chinese silicon, such as Huawei’s Ascend series, cannot escape. Each stack of HBM uses more memory dies, and with demand skyrocketing, easing any AI model’s reliance on the GPU’s direct high-bandwidth memory would be significant, especially considering the ongoing memory supply squeeze.
Engram would enable static memory to be held separately from an LLM’s compute power, allowing the GPU’s rapid HBM to dedicate itself to reasoning, therefore enabling more performant Engram-based AI models, compared to a standard Mixture of Experts (MoE) model.
As detailed in the paper, an Engram-based model scaled to nearly 27 billion parameters can beat out a standard MoE model in long-context training and eliminates computational waste generated by having to reason out facts, by allowing them to be externally stored.
A standard MoE model might have to reconstruct these pieces of data every time it’s referenced in a query, which is called conditional computation. The model will then call on its expert parameters to assemble and reason the data every time, even when it only focuses the query on certain parts or experts, named sparse computation.
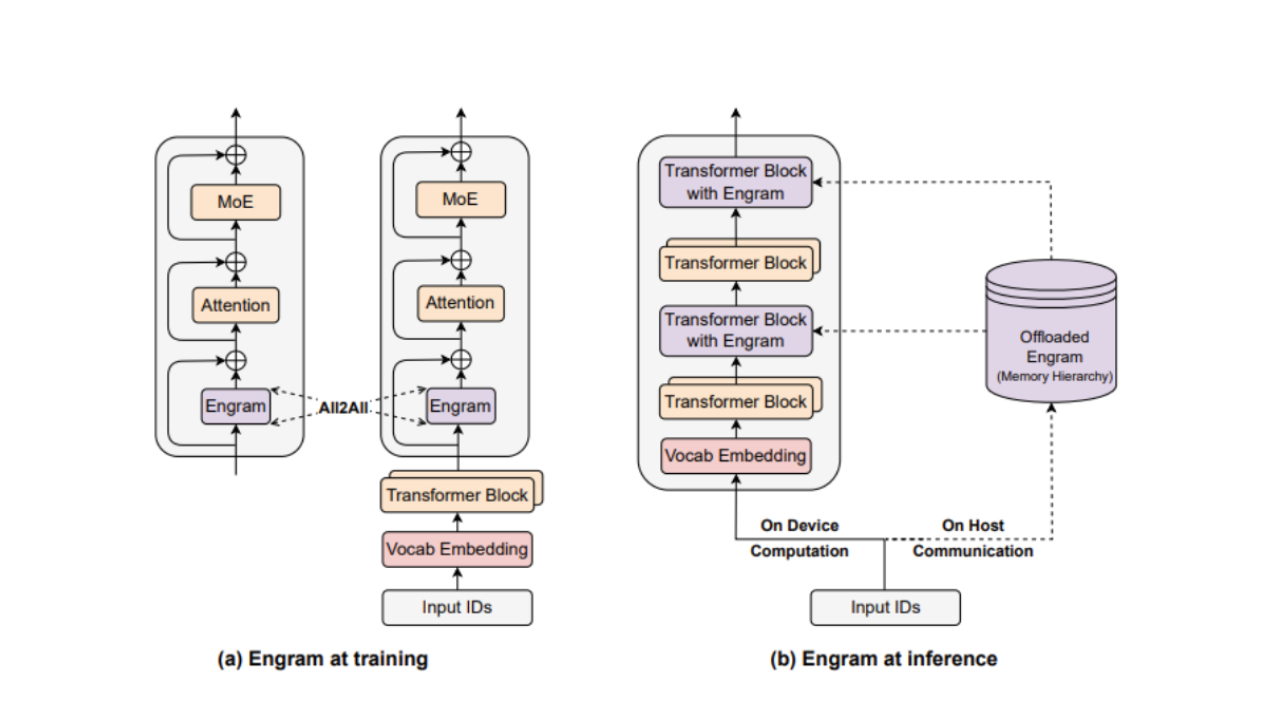
How Engram embeds itself into training and inference workloads (Image credit: Deepseek)
The Engram paper adds that placing conditional memory would allow the model to merely ask: “Do I already have this data?”, rather than having to access the parts of the model that deal with reasoning.
“This process essentially amounts to an expensive runtime reconstruction of a static lookup table, wasting valuable sequential depth on trivial operations that could otherwise be allocated to higher-level reasoning,” the paper reads.
How Engram is different to KVCache
Engram takes static patterns and lists its knowledge index into a parsable piece of conditional memory with a store of information, relieving the AI model from the burden of having to reason through context repeatedly. While Nvidia’s KVCache, announced at CES 2026, offloads context data to NVMe memory with BlueField-4, this acts as more of a short-term solution, allowing the model to remember things that you have recently said or added within context, and is, for all intents and purposes, disposable after you move on to the next query or conversation.
You may like
KVCache, while persistent within the history of your conversations or queries, does not draw on an existing base of pre-calculated data, and is not persistent in the same way that Engram-based LLMs could be, if the paper is to be believed. To put it simply, KVCache can be likened to storing your handwritten notes, whereas Engram is a record of the whole encyclopedia.

(Image credit: Nvidia)Hashing and gating
This is enabled through tokenizer compression, which compresses equivalent tokens (such as the same word with different forms of capitalization) as the same, canonical concept. This allowed Deepseek to reduce the vocabulary size for the conditional memory module by 23%, and allows for rapid parsing of information in context.
As there is an impossibly large number of phrases or combinations of words within a certain context, they employ a methodology named Hashing, which allows the model to apply a number to a series of words. Engram adds to this, with what it calls Multi-Head Hashing, where you can put several hashes onto multiple numbers, for that single phrase to avoid erroneously adding the wrong context. For example, Universal might be a single entry, distinct from Universal Studios, with Multi-Head Hashing employed to ensure no mistakes or database errors.
This is then passed on to Engram’s context-aware gating, which then confirms that the term matches the context of the sentence it’s being used in, before being deployed into an output.
The perfect allocation ratio
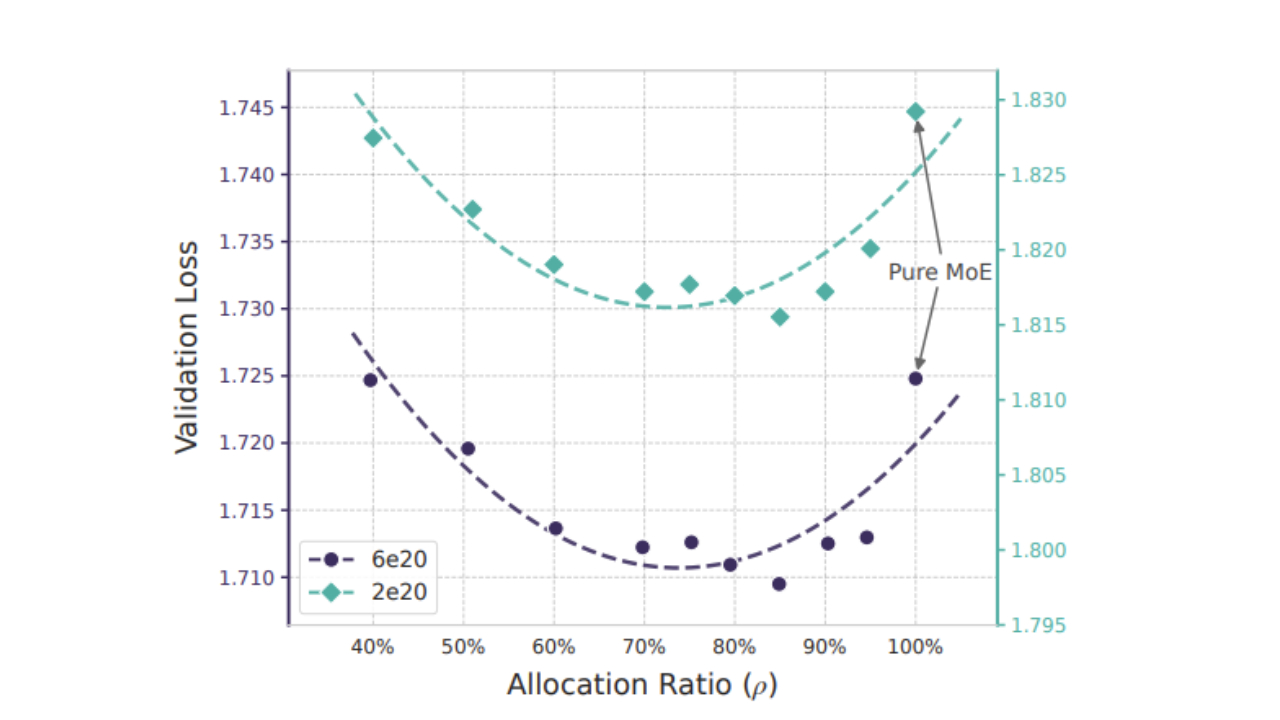
(Image credit: Deepseek)
To examine how Engram-based LLMs might work in large-scale deployments, Deepseek detailed how it might achieve the best allocation between embeddings of Engram and MoE parameters within an AI model.
The outcome was a U-curve, which proved that memory and compute (or reasoning) can be considered mathematically distinct forms of intelligence within AI models. This resulted in a sweetspot for MoE and Engram embeddings.
“Remarkably, the Engram model achieves comparable performance to the pure MoE baseline (𝜌 = 100%) even when the MoE allocation is reduced to just 𝜌 ≈ 40% (i.e., a total of 46 experts for the 5.7B model and 43 experts for the 9.9B model). Furthermore, the pure MoE baseline proves suboptimal: reallocating roughly 20%–25% of the sparse parameter budget to Engram yields the best performance.”
Deepseek itself remarks on how both Engram-dominated and MoE-dominated models falter, whereas a ratio that yields 20-25% of the overall parameter budget of the model to Engram achieves the best results.
What if Engram’s memory was infinite?
Deepseek ran another experiment in parallel, which it names the “Infinite Memory Regime.” This effectively keeps the computational budget fixed, so the model doesn’t get more expensive to run, and attaches a near infinite number of conditional memory parameters to be deployed using Engram.
What they found was that since Engram is distinct from the overall compute budget (since it’s effectively a long-term storage bank, which taps into the overall model), Deepseek discovered that performance scales linearly with memory size. Meaning that if a model continued to add to its conditional memory banks, its performance would only continue to improve, without having to increase the overall compute budget.

(Image credit: Future)
This could have significant implications for the wider AI industry if performance and results are not singularly bound by compute, but to long-term “Engram” memory banks. If the performance benefits are indeed as good as the paper outlines, the memory squeeze would no longer be singularly based on the deployment of HBM, but all forms of memory that could be deployed within data centers, either through CXL or other methods of interconnection.
The results speak for themselves
Deepseek deployed an Engram-27B parameter model and a standard 27B MoE model in parallel to determine the performance benefits of computational memory within AI models, and the results were exemplary. Within knowledge-intensive tasks, Engram was 3.4 to 4 points better than its MoE equivalent, and it was even better at reasoning, with a 3.7 to 5 point uplift when compared to its MoE “reasoning-only” sibling. Similar results were also achieved in coding and mathematics-based tests.
However, the big win for Engram was in long-context tasks, increasing accuracy within the NIAH (Needle in a Haystack) benchmark to 97%, which is a leap from the MoE model’s score of 84.2%. This is a large difference in reliability between the models, and could point toward AI’s long-context and coherence issues eventually becoming a thing of the past, if Engram were to be deployed in a commercial AI model, especially if the demands for long-context AI queries increase.
Will Deepseek V4 be based on Engram?
Engram has significant implications for the AI industry, especially as the paper details how this specific methodology is no longer bound by HBM, but instead longer-term storage. System DRAM can now be utilized to significantly improve the quality of Engram-based LLM outputs, meaning that the much more expensive HBM will only be used for computationally heavy queries.

(Image credit: DeepSeek)
Of course, if Engram were to take off, it may worsen the ongoing DRAM supply crisis, as AI hyperscalers adopting the methodology would then flock to system DRAM, instead of solely focusing on putting all of their memory ICs in production into HBM for GPUs.
“We envision conditional memory functions as an indispensable modeling primitive for next-generation sparse models,” Deepseek said, hinting at a possible V4 deploying Engram in a new AI model. With the company rumored to announce a new AI model within the next few weeks, don’t be surprised if it implements Engram within it.
While the results are impressive on paper, Engram’s impact has yet to be determined in real-world deployment. But, if everything the paper says holds in a real-world context, the company could be onto a new ‘Deepseek moment.’