

Welcome back to Neural Notes, a weekly column where I look at how AI is influencing Australia. In this edition: Arena was once a niche research project that has become a de facto public referee for ChatGPT, Claude, Gemini, and more. But how much should founders actually trust its rankings?
When Googling or researching forums for the best AI model, you may eventually find yourself at Arena — a live leaderboard where models from OpenAI, Anthropic, Google, DeepSeek and others compete in anonymous side-by-side comparisons.
What Arena actually is
Originally called LMArena, it was rebranded to simply Arena in late January.
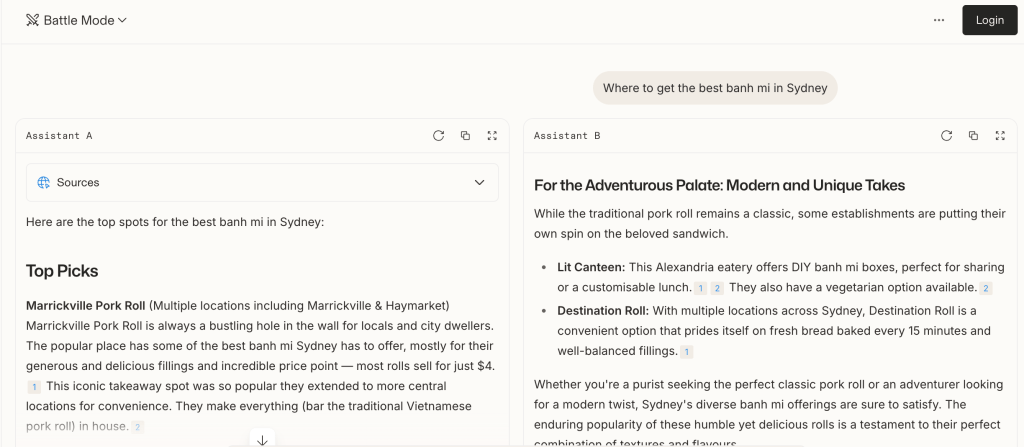
The interface is simple. You enter a prompt, receive two responses, and vote for the better one.
Only after voting do you see which model produced each answer. In my test below, I asked for the best banh mi in Sydney. I preferred Assistant A’s answer, which turned out to be Claude. Assistant B was revealed to be Gemini.
That choice feeds into a ranking system similar to the Elo rating in chess, where models rise or fall depending on which competitors they outperform. The votes then form a continuous ranking built from millions of comparisons.
Smarter business news. Straight to your inbox.
For startup founders, small businesses and leaders. Build sharper instincts and better strategy by learning from Australia’s smartest business minds. Sign up for free.
By continuing, you agree to our Terms & Conditions and Privacy Policy.
At the time of writing, Claude 4.6 Thinking was ranked #1 on the text and coding boards.
In late January the company also introduced Video Arena to test the video prompt capabilities of different models.
 Testing with the hard hitting questions.
Testing with the hard hitting questions.
The system grew out of academic work at UC Berkeley exploring human preference evaluation as an alternative to static benchmarks. Over time it expanded into tracks that mirror real usage such as coding tasks, search comparisons, tool-using agents and expert workflows.
In May 2025 the project spun out into a venture backed company, raising US$100 million in seed funding at a US$600 million valuation.
This was quickly followed by a US$150 million Series A at a US$1.7 billion valuation in early January 2026.
It now sells structured evaluation services using the same methodology, allowing organisations to run targeted tests and analyse strengths and weaknesses before deployment. The public leaderboard is only the visible layer. The underlying product is large-scale human preference data used to compare and calibrate AI systems.
That changes what the rankings represent. Arena is not just observing the model race. It has become part of the measurement infrastructure shaping how AI progress is judged.
Why the Arena rankings carry weight
In practice, Arena has become something of an unofficial referee for the AI arms race.
Labs track their position because a ranking jump signals competitiveness. Top placements appear in launch blogs, investor materials and social posts about who is winning frontier AI. The leaderboard compresses a complex technical comparison into a single understandable number.
There is also a discovery effect. Lesser-known models that perform well attract developer attention before broader coverage catches up. Researchers and open source communities regularly use the rankings as an early indicator that a new entrant deserves inspection.
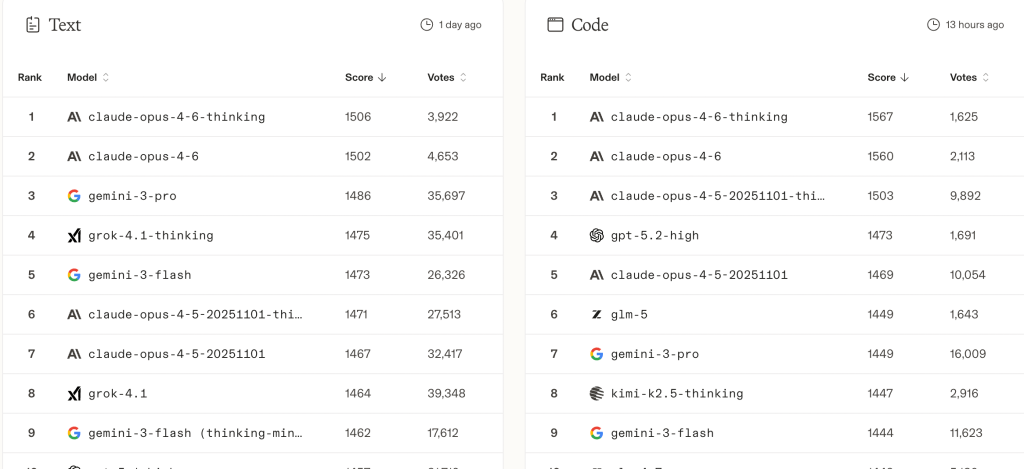 Current Arena rankings.
Current Arena rankings.
For startups choosing a foundation model, the appeal is obvious. Instead of decoding vendor benchmark charts, teams can test prompts directly and compare behaviour side by side.
The broader shift is away from static test suites toward continuous evaluation. Models update weekly and sometimes daily. A fixed benchmark ages quickly while a live leaderboard does not.
But that convenience hides an important reality. Arena measures relative preference among its users, not universal quality.
What the Arena leaderboard actually reflects
For all its influence, Arena is not completely neutral. Its rankings depend on who participates, what they ask and which models are available.
The first issue is representativeness. The user base skews toward technically curious English-speaking users experimenting with frontier systems. Prompt distributions follow trends such as coding and writing while niche industries and non-English contexts appear less often.
Then there is structural advantage. Large labs can iterate quickly, test variants privately and optimise deployment settings before public release.
Smaller or open source teams often submit fewer versions and have less control over presentation, meaning the leaderboard can reward operational maturity as much as the raw model capability.
Related Article Block Placeholder
Article ID: 331475

These concerns came to light in 2025 when researchers analysed millions of Arena battles and argued the system unintentionally advantaged large proprietary labs. They found some companies privately tested many model variants before release.
Meta was cited as privately testing 27 variants ahead of its Llama 4 release, with only the strongest appearing publicly. The study also observed major commercial models appeared in matchups more frequently, giving them more data and faster rating stabilisation.
Arena disputed parts of the analysis and said pre release testing had been disclosed, while indicating it would adjust sampling so smaller models appear more often.
The episode showed a predictable dynamic. Once rankings influence reputation, participants optimise for the environment they are measured in.
That dynamic goes beyond variant testing. Organisations can tune system prompts, adjust conversational style or encourage community participation to improve standing without improving real world usefulness.
Even the statistics have limits. A relative rating does not guarantee the top model will perform best for a specific task. A system strong in coding may rank highly while underperforming in a specialised workflow.
Why this matters for startups and small businesses
Arena introduces a new layer in the AI ecosystem: measurement infrastructure that shapes perception.
A public leaderboard now influences adoption decisions, investor narratives and media coverage.
On one hand, platforms like Arena increase transparency. They expose weaknesses curated demos can hide and give researchers a shared reference point. On the other, they concentrate soft power in a small evaluation layer whose preferences may not align with broader social needs.
That is not to say that Arena is not still incredibly useful for founders and businesses deciding between AI products.
Arena is still worth consulting to reality check vendor claims and understand behaviour across models. But it reflects global averages, not your specific customers. While it is a scoreboard you may want to watch, it should not replace bespoke testing.