
Our findings showed that GPT-4-generated materials for both NIPT and BRCA cases remained difficult to read according to established readability thresholds for patient-facing information22,23. However, when evaluated using the same metrics, they were, in some cases, easier to read than the human-generated materials. The model did not hallucinate across its outputs. Our analysis showed notable differences in how respondents evaluated the materials, particularly those generated by GPT-4. These inconsistencies raise key questions about the model’s reliability and potential role in the IC process. Part of this variation could also reflect the inherent variability in both human- and GPT-4-generated IC materials. That is, human-generated text can be shaped based on the author’s background, communication style, and institutional norms. This can significantly limit its standardization as a benchmark. Similarly, GPT-4-generated outputs are subject to variability mainly due to the probabilistic nature of the model per se, meaning outputs can differ across sessions even with identical prompts. This dual variability should be considered when interpreting these types of findings, as it reflects the real-world variation that occurs in both clinical communication and LLM-generated text. Acknowledging this dual variability strengthens the transparency of our methodological approach and contextualizes the inconsistencies observed in both content coverage and evaluation.
GPT-4 struggled to generate NIPT and BRCA materials at the readability levels recommended by leading health organizations24,25 when no specific instructions were provided. Readability varied widely, particularly in GPT-4-generated material. These results align with previous research in general medical fields7,26,27,28,29,30 but contrast with studies where ChatGPT-3.5 and GPT-4 were explicitly instructed to simplify consent forms7,10,11. Since GPT-4 was not given pre-written text to simplify, it may have generated material at a higher reading level than expected. GPT-4 Zero-shot learning resulted in slightly harder-to-read material than GPT-4 RAG in both English and Italian, partially aligning with Lai et al.31, who found that GPT-4 zero-shot learning underperforms across different languages. GPT-4 generated the most readable texts in Greek. However, this is possibly due to limitations in existing readability assessment tools (e.g., SMOG) that are not optimized for Greek’s morphology and semantic density. Overall, GPT-4’s readability scores closely matched those of human-generated IC material, suggesting that its default text generation mimics human writing unless explicitly instructed otherwise.
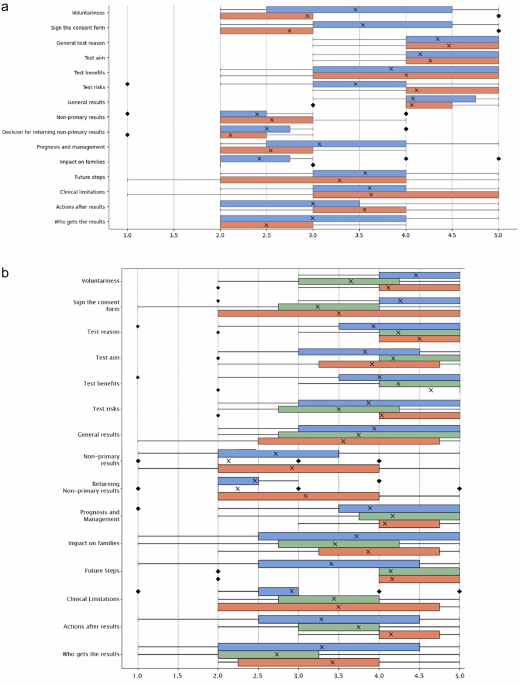
GPT-4-generated materials included some IC components but omitted others, with variation across languages. In German, GPT-4-RAG-generated material outperformed human-written materials, likely due to RAG’s ability to retrieve structured knowledge from reliable sources32,33. This is particularly relevant for BRCA testing, where rising demand34,35 may have expanded databases, improving RAG’s accuracy. However, GPT-4-RAG struggled with non-primary results, yielding lower scores in this area. These findings align with research showing ChatGPT’s difficulty in addressing complex genetics-related questions36 further highlighting its limitations in capturing nuanced IC components regardless of the prompting technique used. GPT-4’s challenges in these components may stem from the distinction between an IC form and an IC process. As a model trained on large text corpora, GPT-4 may be more suited to generating static IC forms that follow standardized formats, such as those commonly used in medical settings where risks, benefits, and procedures are relatively consistent and widely documented. Moreover, as previously noted, most studies evaluating LLMs for IC have focused on surgical settings. These studies7,11 typically involve feeding the model existing IC forms, often sourced from large medical centers11, and prompting it to simplify the content. This may contribute to GPT-4’s stronger performance with such materials, as it aligns closely with both its training data and the structure of the evaluation tasks. In contrast, genomic testing often requires more individualized, context-sensitive information, raising concerns about GPT-4’s ability to generate consent materials that go beyond the scope of standard form templates.
Additionally, GPT-4 underperformed in Greek, highlighting language biases in AI development. Similar disparities have been observed in Japanese17 and Spanish18 compared to English. This supports the assumption that less commonly spoken languages receive weaker AI performance across domains17,18,37,38. Language-based disparities in healthcare have been linked to reduced primary care utilization and poorer health outcomes37,38, raising concerns about the potential for AI-driven inequities in medical information accessibility.
Participants’ preference for human-generated materials for both NIPT and BRCA was modest. This trend was more pronounced for BRCA, where GPT-4-RAG-generated material was frequently misidentified as human-written. This suggests that RAG may not only improve informational content but also enhance tone, structure, and style in ways that closely resemble human-generated materials. This, however, also implies that users need to provide relevant information, which can be more challenging for those new to the task or those with limited time. Nevertheless, it overall indicates that prompting should be viewed not merely as a technical step to produce an output, but as a critical design decision that can significantly influence both content quality and audience reception.
While participants preferred the human-generated material, the relatively small differences in ratings and the difficulty distinguishing GPT-4-generated from human text suggest that, in some contexts, GPT-4 may already be producing content that meets user expectations at least at the level of surface communication. This reinforces our approach to evaluating materials not only in terms of readability, but also in terms of content completeness and clinical relevance. Finally, the variation in participants’ ability to identify GPT-4-generated text in NIPT compared to BRCA further suggests that topic complexity or familiarity may influence how GPT-4-generated materials are interpreted. These findings challenge the assumption that human authorship is inherently superior across different contexts39. However, they also align with existing literature that demonstrates human difficulty in distinguishing between ChatGPT-generated medical manuscripts and those written by humans. This has important implications for the medical community, particularly regarding the circulation of inaccurate material and the risk of increased public distrust40.
This study has several limitations. First, we deliberately sought evaluations from healthcare providers. While this ensured expert assessments, it excluded patients, the primary end-users of IC material. This is a critical limitation, as patient feedback is essential to evaluate whether GPT-4-generated content is clear, relevant, and accessible to its intended audience. Future studies should incorporate patient-centered evaluation. For example, small-scale cognitive interviews or think-aloud sessions could help assess how patients interpret and engage with GenAI-generated IC materials. We are currently conducting a separate study using a think-aloud protocol with patients, which directly builds on this limitation by exploring how patients engage with GenAI-generated IC materials.
Second, our analysis focused on two genetic tests (NIPT and BRCA), limiting the generalizability of these findings to other genetic contexts. However, we observed key patterns, including the omission of certain IC components without explicit prompting, elevated readability levels, and variable expert confidence in patient-facing material quality. These challenges are not unique to NIPT or BRCA and may similarly affect GPT-4-generated materials in other contexts, including carrier screening or whole-genome sequencing, suggesting broader relevance. Future research should assess whether these patterns persist across additional testing scenarios.
Third, our small sample size (N = 25) and uneven distribution across languages pose constraints, and readers should consider the findings preliminary. Specifically, the sample size limits the ability to capture the full range of variation in GPT-4-generated material and provider assessments, thereby reducing the generalizability of the results. Also, the uneven representation of languages limits our ability to draw robust conclusions about language-specific patterns or to generalize across linguistic and cultural contexts. Some findings, therefore, may reflect features unique to specific language groups rather than broader trends in language use. Also, convenience sampling may have attracted individuals with a stronger interest in IC processes or genetic education, introducing selection bias. This could have influenced how participants engaged with the materials, possibly resulting in evaluations that are not fully representative of the broader clinical community. Moreover, the small sample size limits the ability to explore variation across professional roles, language groups, and test types. As a result, generalizability is limited, and the findings should be interpreted with caution. Future studies should use larger and more diverse samples to capture broader perspectives.
Another limitation of this study is the exclusive use of the GPT-4 model. We did not include other LLMs, such as Gemini, Copilot, or medical models like Med-PaLM and Med-Mistral, as they were outside the scope of the study. Such LLMs are likely to differ in clinical accuracy, terminology, and style. For instance, the Mistral 8 x 22 B LLM has shown promise in enhancing the readability, understandability, and actionability of IC forms without compromising accuracy or completeness41. While this highlights the potential of domain-specific models, our focus on a general-purpose model like GPT-4 strengthens the relevance of our findings to broader, real-world clinical contexts where fine-tuned models may not be readily accessible. Finally, while we carefully designed our prompts, they did not account for patient-specific factors, such as literacy level, clinical history, gender, or age. Although our approach enabled a controlled comparison between GPT-4- and human-generated IC material, it did not allow for personalized content generation. Future research should explore LLM-generated IC material tailored to individual patient needs through personalized prompts.
To conclude, GPT-4 struggled to produce comprehensive IC material, failing to address all IC components for NIPT and BRCA testing. Similar results were observed across both testing scenarios and all examined languages, including English. Despite these limitations, the model performed well in structured IC components, such as explaining the purpose of the test, its intended benefits, and the general aim for testing. These components often follow standardized formats and appear in publicly available patient-facing health materials. Considering this, GPT-4 may be most effective in generating standardized patient instructions, medical protocols, or discharge summaries rather than IC materials. GPT-4-RAG-generated materials were more often perceived as human-authored, showed better readability than human-written materials in German and zero-shot outputs in English and Italian, and received more consistent evaluations from participants. Although these differences were not statistically significant, they suggest that RAG may offer practical advantages over zero-shot prompting in complex clinical communication tasks, such as IC for genetic testing, particularly in non-English languages. Integrating explicit instructions through RAG may improve model performance by ensuring more complete coverage of IC components. Its performance in German, Italian, and Greek was poorer compared to English. If LLM-generated IC materials favor English-language content, non-English-speaking patients may receive lower-quality health information, further exacerbating existing inequities. Addressing these challenges requires a multifaceted strategy: improving dataset curation, applying multilingual fine-tuning using high-quality, domain-specific texts from underrepresented languages, and designing culturally adapted prompts that reflect local examples, idioms, and healthcare structures. These, along with post-generation validation techniques, should be prioritized as technical, methodological, and ethical imperatives. For now, a hybrid approach, where GPT-4 generates material and clinicians review and refine it, may be more effective for the IC process in genetic testing.