CComputing Read More Parry Labs, Shield AI Partner on Edge AutonomyOctober 16, 2025 Parry Labs and Shield AI signed a memorandum of understanding to combine advanced autonomy with edge computing technologies…
CComputing Read More IBM CEO On Growing Channel Revenue, Quantum Computing Opportunities, And Why ‘AI Is Not Magic’October 16, 2025 Arvind Krishna, during an interview with CRN, says AI provides the channel with opportunities in customer service, software…
CComputing Read More Why Purpose-Built Defines the Future of IntelligenceOctober 16, 2025 At CoreWeave, our mission is simple: to power the creation and delivery of the intelligence that will drive…
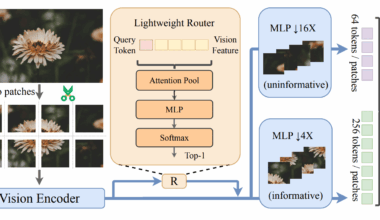
CComputing Read More Vico Training Enables Dynamic High-Resolution Image Representation With Variable Vision Tokens, Minimizing KL Divergence By 50%October 15, 2025 Multimodal Large Language Models (MLLMs) currently face a significant challenge, namely the high computational cost associated with processing…
CComputing Read More What Is One of the Best Quantum Computing Stocks for the Next 10 Years?October 15, 2025 The very first computer to make use of the bizarre and unintuitive properties of quantum mechanics was born…
CComputing Read More IterateON looks at the power of AI and quantum computingOctober 15, 2025 BOULDER, Colo. — Anyone who still questions the power of artificial intelligence to transform commerce and the broader…
CComputing Read More AI-optimized IaaS spend will more than double in 2026October 15, 2025 Listen to the article 3 min This audio is auto-generated. Please let us know if you have feedback.…
CComputing Read More One-query Quantum Algorithms Distinguish Index-Hidden Subgroup Problems With Index 2 Or 3October 15, 2025 The hidden subgroup problem, a cornerstone of quantum algorithm development, often relies on the power of the quantum…
CComputing Read More Brain-Inspired AI Chips Revolutionize Computing, Ushering in an Era of Unprecedented EfficiencyOctober 15, 2025 October 15, 2025 – The landscape of artificial intelligence is undergoing a profound transformation as neuromorphic computing and…
CComputing Read More Q&A: IBM’s Mikel Díez on hybridizing quantum and classical computingOctober 15, 2025 And, one clarification. Back in 2019, when we launched our first quantum computer, with between 5 and 7…
CComputing Read More D-Wave Quantum gains as Swiss Quantum Technology agrees to deploy one of its computers for 10 million eurosOctober 15, 2025 Rigetti Computing tanks amid souring retail sentiment, bearish options bets Rigetti Computing is getting taken to the woodshed…
CComputing Read More Can Supercomputing Be Greener and More Secure?October 15, 2025 Ana Veroneze Solórzano often jokes that she ended up in high-performance computing by accident. What’s not a joke…