

A Glimpse Into the Not-So-Distant Future
In certain corners of the web, a once-niche idea has gone mainstream: The Dead Internet Theory. It suggests that most of what we see online: content, conversation, engagement—is no longer created by people. Instead, it’s bots talking to bots, large language models (LLMs) recycling outputs, and synthetic personas trapped in algorithmically generated loops—a transition from search engine optimization sludge to full-blown AI slop.
We’re trending quickly toward an internet that could be 99.9% AI-generated content, where agents and bots outnumber humans not just in traffic but in creative output. AI agents chat with each other on forums, generate news articles, create thought leadership, engage on social media, leave product reviews, spark controversy, and post memes. Each bot believes it’s talking to a human. Each human statistically is engaging with a bot. Every interaction seems plausible, even engaging. But it’s all synthetic.
The imbalance comes from scale and inherent limitations. Human beings can only do so much: every decision, task, or creation requires time, attention, and energy. Our cognition may juggle many ideas at once, but our actions unfold linearly and with natural limits—we need rest, we fatigue, and we can’t execute in parallel. Agents face none of these constraints. They operate simultaneously, continuously, and without cost in attention, scaling across compute, APIs, and networks. Their marginal cost per action trends toward zero. This creates an exponential asymmetry: billions of autonomous actions flooding the web at a pace humanity cannot match.
So where does this go? The internet risks becoming a closed loop of digital hallucination. Bots posting content, bots engaging, bots generating follow-ups—each cycle further detached from human input or events. Left unchecked, this spirals into a whiteout: a fog of synthetic data where signal collapses and truth is lost. The social, political, and commercial web begin to lose their evidentiary function. While real content may still exist, finding it becomes a statistical improbability. And since we no longer know what’s real, we can no longer trust what we see.
To some, this theory may read like digital paranoia—AI dooming and decelerationist alarmism. But today, the very systems that once catalyzed an exponential surge in human connectedness are approaching an event horizon. This isn’t science fiction. It’s logically a possible endpoint of the agentic internet—and it may happen faster than most realize.
AI Broke the Internet’s Architecture
So what happened exactly? The internet was never built for a world of autonomous agents. Its protocols—HTTP, SMTP, TCP/IP—were designed for human-to-human interaction, where the goal was simply to deliver information, not to verify it. In fact, these systems were built to be stateless: every request—loading a page, sending an email, fetching an image—was handled in isolation, with no memory of what came before. If your browser requested index.html, the server returned it and immediately forgot. A request for style.css was treated as a completely separate event.
This architecture was designed in response to the priorities at the time: simplicity, scalability, and flexibility. It delivers packets, but it does not remember who sent them, whether they were altered, or if they’re part of a larger pattern. The tradeoff was clear: in gaining efficiency, the internet gave up persistence. What we got was a network optimized for speed and scale, but one that is blind to context, memory, and authenticity. The consequences show up in three critical ways:
No inherent identity. The network doesn’t know who you are across requests—hence the later invention of cookies and sessions.
No provenance. The system doesn’t verify authorship or integrity; it only moves data.
Forgetful by design. Once delivered, a request leaves no trace. A thousand actions from one bot look no different than a thousand actions from a thousand people.
For decades, these were features not bugs. We relied on external guardrails—journalism, credentials, domain authorities, and reputation systems—to provide the missing layer of trust.
But in today’s agentic era, those guardrails no longer hold and old assumptions have collapsed. Billions of autonomous bots and AI systems can generate, remix, and transmit content at machine speed. The absence of built-in memory or provenance has become a critical weakness. The internet doesn’t just fail to authenticate sources, it forgets them instantly and in a world of synthetic media, that forgetfulness means our systems struggle mightily to distinguish authentic human content from machine hallucinations.
Our New Reality
The Turing Test—once the gold standard—has already been decisively surpassed. In March 2025, a study was published by the Department of Cognitive Science UC San Diego whereby human participants had 5 minute conversations simultaneously with another human and an LLM Mode “before judging which conversational partner they thought was human”. The results were that GPT-4.5 was judged to be the human 73% of the time “significantly more often than interrogators selected the real human participant” [1]
Without a way to verify source or authenticity, we could be staring at a decline of confidence in content. The internet, once humanity’s most powerful coordination tool, is becoming unreliable as a foundation for trust, evidence, or shared reality. Bots have already become prevalent, distorting engagement metrics and flooding ecosystems with noise. Yet, despite the scale of the problem, the underlying architecture itself remains fundamentally unaddressed.
The new reality we are forced to grapple with is that:
Content is now infinite. The marginal cost of generating a plausible image, article, or video is near-zero.
Perception is broken. Synthetic media is increasingly indistinguishable from human output, especially at scale.
Identity is hollow. AI agents can convincingly mimic tone, behavior, and even emotion.
Some key stats underscore just how deep the issue runs:
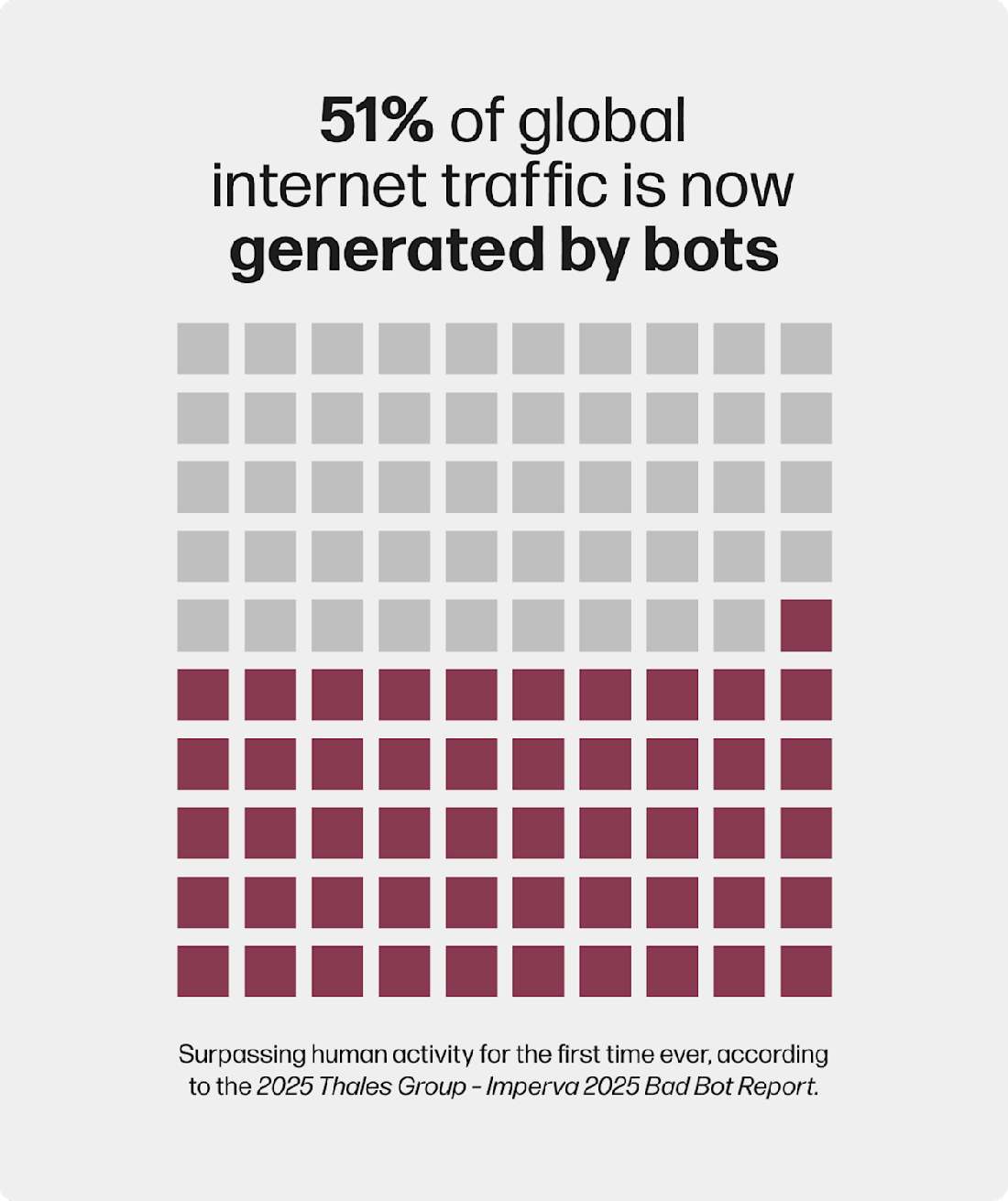
51% of global internet traffic is now generated by bots—surpassing human activity for the first time ever.[2]
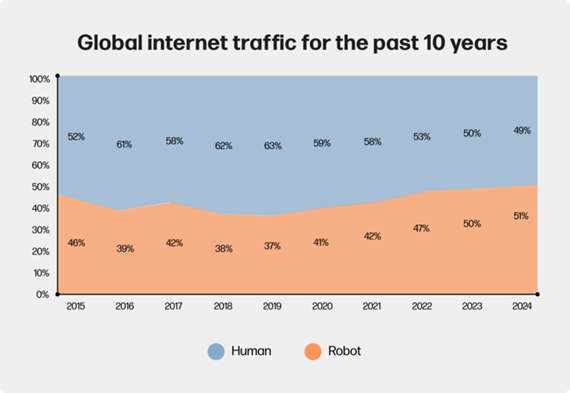
Bot traffic has been climbing steadily for years: 47.4% in 2022, nearly 50% in 2023, and now a majority in 2025 (Imperva Report 2022-2023).

On platform X (formerly Twitter):
64% of accounts may be bots.[3]
76% of all traffic at peak times has been attributed to automation (Outposts.io Report).

On Instagram:
An estimated 95 million accounts (9.5%) are fake, often run by bots or used for deception.[4]
As of 2025, 14.1% of followers are bots or inactive accounts.
For business accounts, that number rises to 18.2%.
For influencers with 1M+ followers, up to 23% of their audience is likely low-quality or fake.

On Meta:
In 2024 Meta Deletes 100 Million Pages and 23M Impersonating Accounts[5]
In 2024 Meta discloses that the total “inauthentic” duplicate and false accounts for 14% of their monthly active users, roughly 430 million accounts [6]
Why Today’s Solutions Won’t Fix What’s Broken
The tools most often deployed today are not infrastructure. They are bandaids that break down quickly in an agentic world. Here’s why these approaches fall short:
Approach
How It Works
How AI Outsmarts It
AI Content Detection Tools
AI detectors promise to identify synthetic content and help platforms filter out machine-generated media before it spreads.
As generative models improve, detection becomes an endless arms race. New systems can self-correct, randomize grammar, paraphrase, and mask their origins to slip past detectors. False positives are also a serious issue, disproportionately mislabeling non-native English speakers, neurodivergent writers, and legitimate creators — eroding confidence in the tools themselves.
CAPTCHAs and Bot Filters
CAPTCHAs were designed to separate humans from machines by asking users to complete visual or logic puzzles.
Vision models now outperform humans on most CAPTCHA challenges. Services like “CAPTCHA farms” and automated solvers make bot traffic indistinguishable from real users. Google itself admitted reCAPTCHA v2 was being solved correctly over 90% of the time by bots.
Rate Limiting and IP Blocking
Platforms limit the number of requests or posts from a given account or IP to curb spam and scraping.
Modern bots are distributed across millions of cloud servers and residential proxies, blending in with normal user traffic. With agentic systems, traffic can be throttled, randomized, and diversified at machine speed, overwhelming limits designed for slower, predictable spam.
Account Verification (Phone, Email, ID)
Force users to verify identity through email, SMS, or government ID before accessing platforms.
AI-enabled botnets now automate the creation and verification of millions of synthetic accounts, using disposable phone numbers, fake IDs, and stolen credentials purchased on darknet markets. AI deepfake tools even generate realistic ID scans and selfies to bypass KYC checks.
AI Fact Checking
Automated verification of claims and adding labels to misinformation
Fact-checking is reactive, slow, expensive, and politicized. Meta introduced an AI fact-checking tool in 2025 that processes over 1 million posts daily, yet its real-time success rate is just 37%.[7]
The Architecture of Trust Must Be Rebuilt
In light of this, we should all be asking what, if anything, can be done—or is being done—to address this fundamental threat to what has become such a critically important way that human beings interact with each other: the internet.
This problem is solvable but it requires a reboot of the internet’s foundational architecture.
We need to treat trust as an engineering problem, not a moderation challenge. That means building infrastructure that does what HTTP did for delivery, and what SSL did for secure browsing—except this time, for provenance, proof-of-human, and programmable access. This new architecture will need to include:
Proof-of-origin: Cryptographic signatures that can confirm content was created by a real person, on a real device, in a real place and time.
Immutable Lineage: Audit trails that show how content has changed and where it came from.
Agent-aware Economics: Machine-readable pricing and permissions for data access, scraping, and reuse.
Internet-scale Design: Solutions that can support billions of interactions per day, across every layer of the stack.
This isn’t a hypothetical wish list, it’s the focus of serious engineering work being done right now by teams building the next generation of internet infrastructure. And just like TCP/IP and HTTPS, these systems may soon become invisible, embedded standards that make modern digital life possible (hopefully).
Who’s Rebooting the Internet
Several companies are taking up the challenge of building this next-generation infrastructure. Different layers of the stack, from content authenticity, to economic friction, to access control require different solutions and there is no single fix or silver bullet.
Cloudflare — Access Control for the AI Era Cloudflare is building the gatekeeping layer for AI agent access to public web content. It now blocks AI crawlers by default and has introduced HTTP 402 “Pay‑Per‑Crawl”, allowing websites to charge bots and large language models for access. This shifts the internet from a free-for-all to a consent-based, economically enforceable system, where scraping and ingestion come with cost and accountability. The company also actively exposes stealth crawlers, that have attempted to bypass these restrictions.
OpenOrigins — Proof-of-Authenticity on a truly global scale A Galaxy Interactive portfolio company, OpenOrigins is building the provability layer for digital content. Using Trusted Execution Environments (TEEs) inside smartphones and cameras, it can cryptographically prove that an image or video was captured by a real person at a real time and place. This is proof-of-origin infrastructure—designed not to detect fakes after the fact, but to prevent them by embedding truth at the moment of creation. OpenOrigins also addresses legacy content with Archive Anchoring, creating verifiable audit trails for existing media, providing cryptographic provenance for decades of archival content. This infrastructure is designed to be internet-scale with the use of Cambium, a novel distributed consensus protocol purpose-built for global provenance.
BitGPT — Programmable Economics for Machine Agents Another Galaxy Interactive portfolio company, BitGPT is designing the economic rails for the agentic internet. Its 402Pay protocol allows content platforms, APIs, and endpoints to charge AI agents for access—using programmable, real-time micropayments embedded at the protocol level. Unlike traditional human-facing paywalls, 402Pay is built for a world where machines consume and transact with digital content autonomously, turning the economic tables on the scrape-now-pay-never status quo.
From Collapse Back to Confidence
This is a moment of creative destruction. The internet, once a place of connection and knowledge, is being flooded with synthetic noise. But even as trust erodes, the foundations of a new digital architecture are being laid. We’re not just witnessing the end of an era, we’re witnessing the beginning of a new one and what emerges next will define the internet for generations to come.
The future of AI isn’t just about performance or speed. It’s about trust at scale. Without that, agents hallucinate, bots manipulate, and humans simply check out.
References
This document, and the information contained herein, has been provided to you by Galaxy Digital Inc. and its affiliates (“Galaxy Digital”) solely for informational purposes. This document may not be reproduced or redistributed in whole or in part, in any format, without the express written approval of Galaxy Digital. Neither the information, nor any opinion contained in this document, constitutes an offer to buy or sell, or a solicitation of an offer to buy or sell, any advisory services, securities, futures, options or other financial instruments or to participate in any advisory services or trading strategy. Nothing contained in this document constitutes investment, legal or tax advice or is an endorsement of any of the stablecoins mentioned herein. You should make your own investigations and evaluations of the information herein. Any decisions based on information contained in this document are the sole responsibility of the reader. Certain statements in this document reflect Galaxy Digital’s views, estimates, opinions or predictions (which may be based on proprietary models and assumptions, including, in particular, Galaxy Digital’s views on the current and future market for certain digital assets), and there is no guarantee that these views, estimates, opinions or predictions are currently accurate or that they will be ultimately realized. To the extent these assumptions or models are not correct or circumstances change, the actual performance may vary substantially from, and be less than, the estimates included herein. None of Galaxy Digital nor any of its affiliates, shareholders, partners, members, directors, officers, management, employees or representatives makes any representation or warranty, express or implied, as to the accuracy or completeness of any of the information or any other information (whether communicated in written or oral form) transmitted or made available to you. Each of the aforementioned parties expressly disclaims any and all liability relating to or resulting from the use of this information. Certain information contained herein (including financial information) has been obtained from published and non-published sources. Such information has not been independently verified by Galaxy Digital and, Galaxy Digital, does not assume responsibility for the accuracy of such information. Galaxy Digital holds a financial interest in companies included in this report, including OpenOrigins and BitGPT. Galaxy Digital also provides services to vehicles that invest in these companies. If the value of such assets increases, those vehicles may benefit, and Galaxy Digital’s service fees may increase accordingly. Affiliates of Galaxy Digital may have owned, hedged and sold or may own, hedge and sell investments in some of the digital assets, protocols, equities, or other financial instruments discussed in this document. Affiliates of Galaxy Digital may also lend to some of the protocols discussed in this document, the underlying collateral of which could be the native token subject to liquidation in the event of a margin call or closeout. The economic result of closing out the protocol loan could directly conflict with other Galaxy affiliates that hold investments in, and support, such token. Except where otherwise indicated, the information in this document is based on matters as they exist as of the date of preparation and not as of any future date, and will not be updated or otherwise revised to reflect information that subsequently becomes available, or circumstances existing or changes occurring after the date hereof. This document provides links to other Websites that we think might be of interest to you. Please note that when you click on one of these links, you may be moving to a provider’s website that is not associated with Galaxy Digital. These linked sites and their providers are not controlled by us, and we are not responsible for the contents or the proper operation of any linked site. The inclusion of any link does not imply our endorsement or our adoption of the statements therein. We encourage you to read the terms of use and privacy statements of these linked sites as their policies may differ from ours. The foregoing does not constitute a “research report” as defined by FINRA Rule 2241 or a “debt research report” as defined by FINRA Rule 2242 and was not prepared by Galaxy Digital Partners LLC. Similarly, the foregoing does not constitute a “research report” as defined by CFTC Regulation 23.605(a)(9) and was not prepared by Galaxy Derivatives LLC. For all inquiries, please email [email protected]. ©Copyright Galaxy Digital Inc. 2025. All rights reserved.