


Over at the official blog of the Wikipedia community, Marshall Miller untangled a recent mystery. “Around May 2025, we began observing unusually high amounts of apparently human traffic,” he wrote. Higher traffic would generally be good news for a volunteer-sourced platform that aspires to reach as many people as possible, but it would also be surprising: The rise of chatbots and the AI-ification of Google Search have left many big websites with fewer visitors. Maybe Wikipedia, like Reddit, is an exception?
Nope! It was just bots:
This [rise] led us to investigate and update our bot detection systems. We then used the new logic to reclassify our traffic data for March–August 2025, and found that much of the unusually high traffic for the period of May and June was coming from bots that were built to evade detection … after making this revision, we are seeing declines in human pageviews on Wikipedia over the past few months, amounting to a decrease of roughly 8% as compared to the same months in 2024.
To be clearer about what this means, these bots aren’t just vaguely inauthentic users or some incidental side effect of the general spamminess of the internet. In many cases, they’re bots working on behalf of AI firms, going undercover as humans to scrape Wikipedia for training or summarization. Miller got right to the point. “We welcome new ways for people to gain knowledge,” he wrote. “However, LLMs, AI chatbots, search engines, and social platforms that use Wikipedia content must encourage more visitors to Wikipedia.” Fewer real visits means fewer contributors and donors, and it’s easy to see how such a situation could send one of the great experiments of the web into a death spiral.
Arguments like this are intuitive and easy to make, and you’ll hear them beyond the ecosystem of the web: AI models ingest a lot of material, often without clear permission, and then offer it back to consumers in a form that’s often directly competitive with the people or companies that provided it in the first place. Wikipedia’s authority here is bolstered by how it isn’t trying to make money — it’s run by a foundation, not an established commercial entity that feels threatened by a new one — but also by its unique position. It was founded as a stand-alone reference resource before settling ambivalently into a new role: A site that people mostly just found through Google but in greater numbers than ever. With the rise of LLMs, Wikipedia became important in a new way as a uniquely large, diverse, well-curated data set about the world; in return, AI platforms are now effectively keeping users away from Wikipedia even as they explicitly use and reference its materials.
Here’s an example: Let’s say you’re reading this article and become curious about Wikipedia itself — its early history, the wildly divergent opinions of its original founders, its funding, etc. Unless you’ve been paying attention to this stuff for decades, it may feel as if it’s always been there. Surely, there’s more to it than that, right? So you ask Google, perhaps as a shortcut for getting to a Wikipedia page, and Google uses AI to generate a blurb that looks like this:
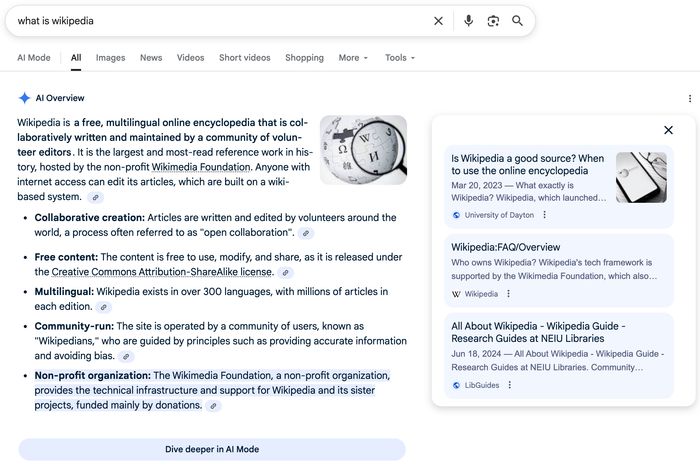
This is an AI Overview that summarizes, among other things, Wikipedia. Formally, it’s pretty close to an encyclopedia article. With a few formatting differences — notice the bullet-point AI-ese — it hits a lot of the same points as Wikipedia’s article about itself. It’s a bit shorter than the top section of the official article and contains far fewer details. It’s fine! But it’s a summary of a summary.
The next option you encounter still isn’t Wikipedia’s article — that shows up further down. It’s a prompt to “Dive deeper in AI Mode.” If you do that, you see this:

It’s another summary, this time with a bit of commentary. (Also: If Wikipedia is “generally not considered a reliable source itself because it is a tertiary source that synthesizes information from other places,” then what does that make a chatbot?) There are links in the form of footnotes, but as Miller’s post suggests, people aren’t really clicking them.
Google’s treatment of Wikipedia’s autobiography is about as pure an example as you’ll see of AI companies’ effective relationship to the web (and maybe much of the world) around them as they build strange, complicated, but often compelling products and deploy them to hundreds of millions of people. To these companies, it’s a resource to be consumed, processed, and then turned into a product that attempts to render everything before it is obsolete — or at least to bury it under a heaping pile of its own output.
Sign Up for John Herrman column alerts
Get an email alert as soon as a new article publishes.
Vox Media, LLC Terms and Privacy Notice