
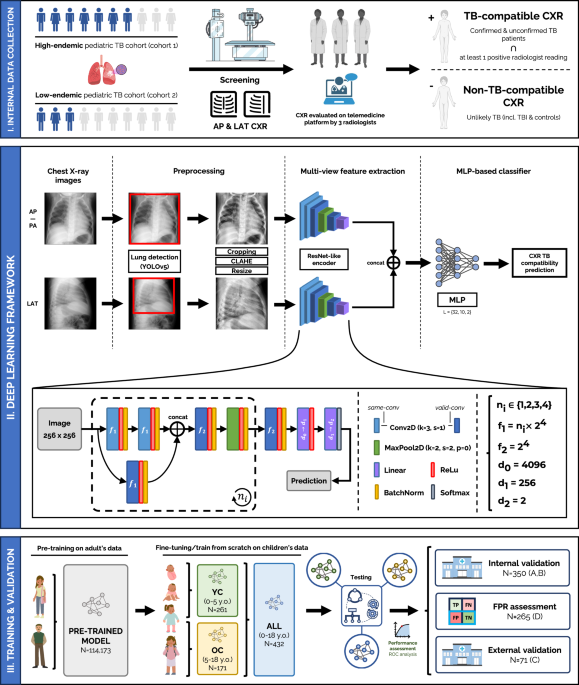
Multi-view deep learning framework for pediatric TB-compatible CXR detection
The framework proposed (see Fig. 1-II) is a multi-view pipeline which consists of two main branches: one for AP/PA CXRs and another for LAT CXRs, which are later combined to deliver a classification result to score if the case is compatible with pediatric TB. Each branch is responsible for the automatic feature extraction of information compatible with pediatric TB findings in the lung and mediastinal regions within its corresponding CXR view. Both CXR images are preprocessed and fed into an efficient ResNet-like architecture (same architecture, different weights for each branch), which will output two different feature vectors, one for each view, and which will be later concatenated and linearly combined in a multi-layer perceptron (MLP), delivering a TB classification prediction for that specific case. The framework allows a flexible configuration of either AP/PA CXRs as the sole input or multi-view AP/PA and LAT input. Thus, if the LAT view is not available, a prediction based only on the AP/PA view will be delivered.
Fig. 1: Proposed multi-view deep learning-based framework for pediatric TB classification.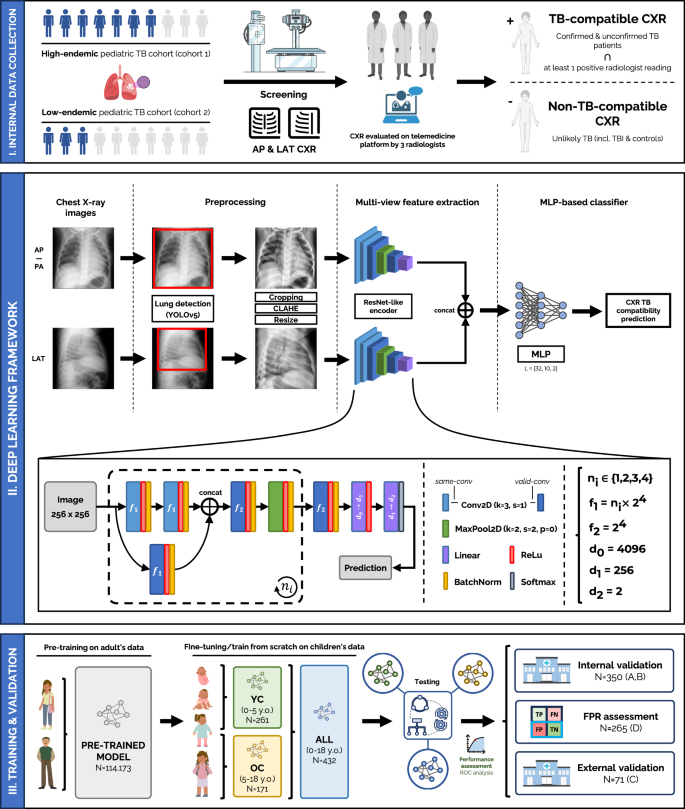
(I) Collection procedure of internal data from cohort 1 (high-endemic) and cohort 2 (low-endemic), and TB reference standard definition. (II) Deep learning architecture and pipeline used, employing a ResNet-like encoder to extract features from both CXR views, frontal (AP/PA) and lateral (LAT), that are concatenated and fed into an MLP-based classifier to deliver a TB-compatible-CXR prediction result. Details on the architecture are included in the figure. (III) Training and validation procedure for the all-age and age-specific models, through internal and external validation. Created in BioRender. Capellán-Martín, D. (2025) https://BioRender.com/qxebfh7.
The reference standard for TB-compatible CXR considered both the radiological readings and the case definition. Therefore, patients with confirmed or unconfirmed TB with at least one radiological feature suggestive of TB were labeled as TB-compatible CXRs, whereas patients deemed TB infection or unlikely TB (according to international consensus definitions43: patients where bacteriological confirmation is not obtained and the criteria for “unconfirmed tuberculosis” are not met) were labeled as non-TB-compatible CXRs (see Table 1). This avoids training the models with TB-positive patients without radiological evidence (e.g., confirmed TB patients without a TB-compatible CXR), as it could lead to potential biases.
Table 1 Details on the reference standard used across cohort: definitions for TB-compatible and non-TB-compatible patients
To ensure our model learns features that are not overly specific to a single healthcare setting or population, we integrated datasets from both high- and low-resource environments. This approach aims to enhance model robustness and reduce context-specific biases that may arise when training solely on data from a single region. Pediatric TB diagnosis is highly variable across settings, influenced by differences in radiographic quality, disease burden, and clinical presentation. Including data from a high-resource setting helps expose the model to higher-quality imaging and broader diagnostic standards, while data from a low-resource, high-burden setting ensures relevance in areas where TB remains a major public health challenge. Importantly, we included an external validation cohort from a low-burden region to evaluate the model’s generalizability in contexts where TB is less prevalent but still clinically relevant. Across all cohorts, sites adhered to international pediatric TB diagnostic guidelines and included both microbiologically confirmed and clinically diagnosed cases, ensuring consistency in case definitions while capturing the clinical variability seen in practice.
We used four CXR datasets from three pediatric TB cohorts (N = 918): three datasets for training and internal evaluation, and one for external evaluation. The first two datasets (A and B) used for training and internal evaluation come from: dataset A) Manhiça Health Research Centre (CISM, Mozambique), referred to as cohort 17,18, with 218 participants; dataset B) the Spanish Pediatric TB Research Network (pTBred, Spain), referred to as cohort 244,45, with 565 participants. These two datasets comprised 783 participants with frontal (AP/PA) and lateral (LAT) CXRs. However, LAT images were not available for all patients. These data were used to train the models from scratch or to fine-tune the pre-trained models, and to perform internal evaluation on independent test subsets unseen by the model. For further evaluation, we used two additional datasets: dataset D, coming from cohort 1, with 265 unlikely TB patients to assess the model’s false positive rate (FPR); and dataset C, coming from Children’s National Hospital (CNH-TB-PEDs, DC, USA), referred to as cohort 3, with 71 participants, which served as an external evaluation dataset, with children ≤18 years diagnosed with TB (microbiological confirmation) and non-TB patients referred to the emergency department for respiratory diseases. Figure 2 shows the case selection process and data split of these three pediatric cohorts and corresponding datasets (A,B,C and D). Across these cohorts, there were confirmed TB patients without CXR TB compatibility (N = 5, 34, and 9 for cohorts 1, 2, and 3, respectively). For further information about the datasets used in this study, as well as the reference standards used, please refer to Datasets and Reference Standard.
Fig. 2: Diagram of data distribution and cohort splits for model fine-tuning, or training from scratch, and evaluation.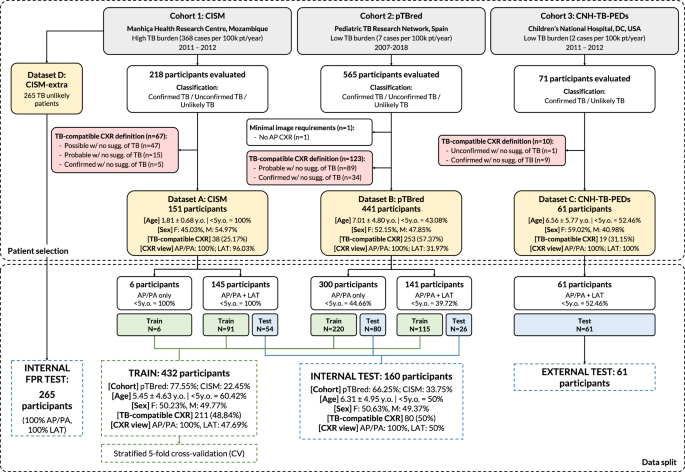
The proposed multi-view deep-learning pipeline was trained and validated on four pediatric TB datasets (N = 918) coming from 3 cohorts, using TB compatibility as the reference standard for CXRs. Datasets A and B (from cohorts 1 and 2, respectively) were used for model training from scratch or fine-tuning and internal validation, while dataset D (unlikely TB patients from cohort 1) was used to assess the FPR of the solution. The external evaluation was conducted on dataset C (from cohort 3). F, female; M, male; y.o., years old.
To comprehensively assess pTBLightNet, we conducted evaluations across several key aspects: model training, age-specific performance, the role of the lateral views in enhancing diagnostic accuracy, and model performance on external datasets.
We first compared two model training strategies: one pre-trained on large-scale, publicly available adult CXR datasets covering a broad spectrum of thoracic diseases (N = 114,173), and another trained from scratch. The pre-training dataset was not TB-specific but included diverse control and diseased patients, enabling the model to learn general radiologic patterns. The pre-trained model was then fine-tuned on pediatric TB data. Both versions were evaluated on internal test data from datasets A and B to assess their effectiveness in identifying TB-compatible CXRs in children. This comparison aimed to determine whether pre-training on adult CXRs could enhance performance in the pediatric TB detection task.
To further assess the impact of patient age distribution on the pediatric TB CXR compatibility detection performance of our framework, we trained several models (see Fig. 1-C) on different age groups: an all-age model (ALL), trained on all the available training data (N = 432), i.e., all age groups included; an age-specific model with all the training data from younger children (YC, < 5 years, N = 261), and an age-specific model with all the training data from older children (OC, 5-18 years, N = 171). All these models were evaluated on the independent internal test sets from cohorts A and B, for all age groups (N = 160), YC (N = 80) and OC (N = 80).
Additionally, we investigated the impact of incorporating LAT CXRs alongside frontal views to improve CXR based diagnostic accuracy, particularly for young children. This multi-view approach was tested to determine whether the additional anatomical information from LAT views could enhance pediatric TB classification.
Finally, we evaluated the performance of the proposed framework on two additional datasets, C and D, aiming to assess the model’s false positive rate and its effectiveness on a completely independent dataset, respectively.
Model training approaches: from scratch vs. fine-tuning
We assessed two model training approaches — training from scratch and fine-tuning a pre-trained model — using an all-age model (also referred to as ALL) trained on all available data across age groups. Here, a total of 432 patients from datasets A and B were used to train an AP/PA model (see Fig. 2 for further information on the training data). The results when validating on the independent internal test set are included in Table 2. Pre-training on adult multi-disease CXRs (N = 114,173) offered a substantial improvement on the pediatric TB detection task, with AUC scores of 0.903 when testing on all age groups (N = 160), 0.893 when testing on the YC subset (N = 80), and 0.913 when testing on the OC subset (N = 80). The mean improvements in AUC when pre-training the models, referred to as (P) in Table 2, were 7.56%, 7.37% and 7.75%, respectively, when compared to trained from scratch approaches (S). Further details on the performance and scores of the model are included in the Supplementary Note 1 (Supplementary Fig. 1).
Table 2 Performance results of all models on different age groupsAge-specific models: YC and OC
We studied whether age-specific models would positively impact TB-compatible-CXR classification performance. To this end, we trained models with data distributed in different age groups. Training data were clearly reduced (N = 261 for YC, N = 171 for OC), but more homogeneous in terms of age distribution. Results from validating both the model trained with YC and OC’s data on the corresponding testing subsets from datasets A and B, as well as out-of-distribution (OOD) cross-testing on opposite age groups, are displayed in Table 2.
The model trained on YC data achieved lower yet comparable performance to the all-age model when tested on YC, with 39.58% less training data (N = 261). On the other hand, the model trained on OC data achieved greater performance than the all-age model when testing on the OC group, using 60.42% less training data (N = 171). When performing OOD cross-testing, i.e., testing on other age groups in which the models were not trained on, we notice a decrease in performance. Finally, generalized mean improvements were observed when pre-training the models, with increments of 4.7% and 7.6% in AUC when testing the YC and OC models, respectively, on their corresponding age groups. These results suggest that age-specific models may be more convenient for age-specific cohorts. Further details on the performance and scores of these age-specific models are included in the Supplementary Note 2 (Supplementary Figs. 2 and 3).
Lateral view: impact on pediatric TB-compatible CXR detection
In clinical practice, lateral CXRs are used to deliver a more accurate diagnosis when screening for pediatric TB, particularly in young children under 5 years of age. Consequently, data were split in a way that younger children aged < 5 years from the independent test set (datasets A and B, from cohorts 1 and 2, respectively) had always both frontal and lateral CXRs.
To evaluate the contribution of lateral CXRs to pediatric TB classification according to the proposed framework (see Fig. 1), we conducted experiments comparing the performance on the independent test set using AP/PA images alone versus using both AP/PA and LAT images as input data to the pipeline.
The results for the all-age and YC models are shown in Table 3. The OC model was not trained on LAT images, as the clinical relevance of lateral CXRs primarily pertains to younger children, making training data for this subgroup and CXR view scarcely available. The results obtained show a slight improvement in AUC when both views are used, with increases of 0.6% and 2% in the all-age and age-specific YC models, respectively. These improvements mirror clinical practice, where LAT CXRs are especially valuable for TB screening in younger children.
Table 3 Performance results from single- and multi-view approaches using both the all-age and YC modelsValidation on additional cohorts
To further validate our models, we conducted experiments on two additional independent datasets: an external dataset from a low TB endemic area (dataset C, cohort 3) and an internal dataset from a high TB endemic area (dataset D, cohort 1).
Validation on an independent external cohort from a low TB endemic area
We tested our all-age model on dataset C, coming from an external low TB endemic area cohort collected in-house at Children’s National Hospital, Washington, DC, USA (cohort 3), which includes participants aged 0 to 18 years. This experiment aimed to assess model generalizability by testing on a completely external and independent cohort. The results obtained are presented in Table 4. Given the availability of the lateral view for all patients, the multi-view strategy was also evaluated. These results suggest that our solution generalizes fairly well to new external data, particularly when lateral CXRs are included in the pipeline (AUC = 0.682), leading to a 10.6% improvement in the AUC score compared to the pre-trained AP/PA model alone. The non-pre-trained AP/PA model performed poorly. These results corroborate our previous findings and indicate that both pre-training and the incorporation of LAT CXRs are effective in improving TB classification results. It is worth noting that performance differences are observed when comparing to internal testing results, which may be partly explained by the natural variability between high- and low-endemic settings, including differences in population characteristics, cohort recruitment strategies and imaging protocols.
Table 4 External validation results from single- and multi-view approaches using the all-age modelValidation on an independent internal dataset from a high TB endemic area
Finally, we conducted an experiment to evaluate our models’ performance on dataset D, i.e., extra unlikely TB patients from cohort 1 (CISM). This cohort consisted of presumed TB patients finally ruled out as unlikely TB patients, i.e., patients in which TB diagnosis was discarded but they could potentially present other pathologies and some signs in their CXRs. The aim of this experiment was to assess the FPR of our solution when predicting on non-TB-compatible children CXRs. The data used in this experiment comprised 265 non-TB-compatible CXRS of participants aged between 0 and 3 years, and both the all-age and YC models were evaluated.
Both models performed fairly well on this independent set, with the all-age model achieving an accuracy of 0.864 and the YC model achieving an accuracy of 0.951, outperforming the all-age model. This difference in performance may be influenced by the age distributions of the training data. Metrics such as F1 or AUC were not computed in this experiment as the independent cohort included only one class (non-TB-compatible CXRs).
ROC analysis & AI explainability
In order to further assess the performance of our solution, Fig. 3 displays how each of the models performs compared to different references, namely CXR TB compatibility, microbiological confirmation, expert reader criteria, and case definition. In general, a similar trend is observed independently of the reference standard chosen, although CXR TB compatibility was used for training our solution and it is therefore considered the main reference standard. For the evaluation with respect to the case definition reference standard, excluded cases based on CXR TB compatibility criteria (red boxes in Fig. 2) in the selection process were recovered from cohorts 1 and 2 (N = 190 cases recovered).
Fig. 3: Performance evaluation of the framework on independent internal test data.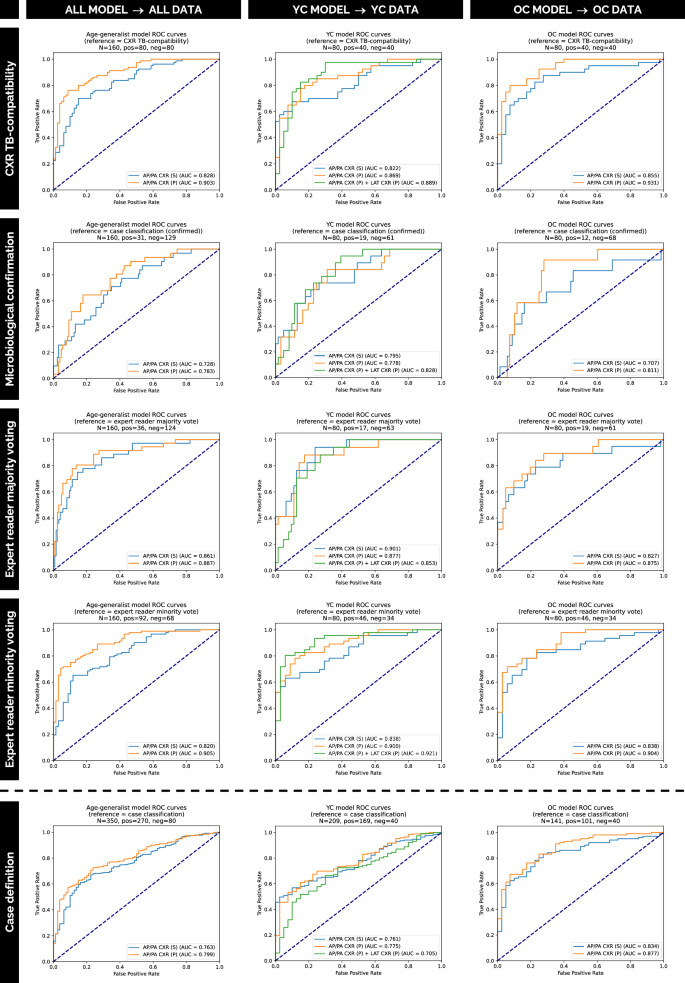
ROC curves show the performance of our solution on independent internal test sets from datasets A and B (cohorts 1 and 2). Models with (P) and without (S) pre-training are compared against multiple reference standards: CXR TB compatibility, microbiological confirmation, expert reader criteria (majority/minority voting), and case definition. For case definition reference standard evaluation, cases previously excluded by CXR TB compatibility criteria (N = 190) were reincorporated. Source data are provided as a Source Data file.
Figure 4 similarly displays the performance with respect to the different references for the independent external dataset from a low TB endemic area cohort (dataset C, cohort 3).
Fig. 4: Performance evaluation of the framework on independent external data.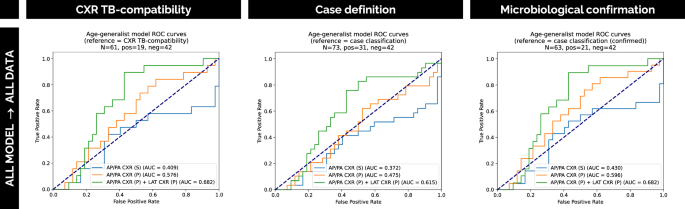
ROC curves illustrate the performance of our solution on the independent external dataset C from cohort 3. The curves compare models using one or two views, with (P) and without (S) pre-training, evaluated against multiple reference standards: CXR TB compatibility, case definition and microbiological confirmation. Source data are provided as a Source Data file.
Explainable AI (XAI), a group of techniques that makes AI model decisions more understandable, enhances transparency in medical diagnostics, improving trust and clinical validation46. Techniques such as Grad-CAM enhances deep learning interpretability by highlighting crucial regions in images that are involved in the classification outcome47. In pediatric TB, Grad-CAMs can be used to highlight regions of interest in CXRs (both AP/PA and LAT views) influencing the prediction. This helps clinicians understand and trust AI decisions, ensuring focus on clinically relevant areas.
To ensure this level of transparency and to qualitatively assess whether the model’s predictions were grounded in clinically meaningful radiographic features, we extracted Grad-CAMs from both AP/PA and LAT views with the all-age model. Figure 5 presents examples of Grad-CAMs from true positive (TP) and false positive (FP) cases from the independent internal test dataset, showing highlighted regions of interest in both AP/PA and LAT views, when attempting to predict TB from CXRs. Also, Fig. 5 presents specific examples of miliary pattern, cavitary lesions, pleural effusion and lymphadenopathies.
Fig. 5: Grad-CAM analysis of TB compatibility prediction in representative CXR cases from datasets A and B (cohorts 1 and 2).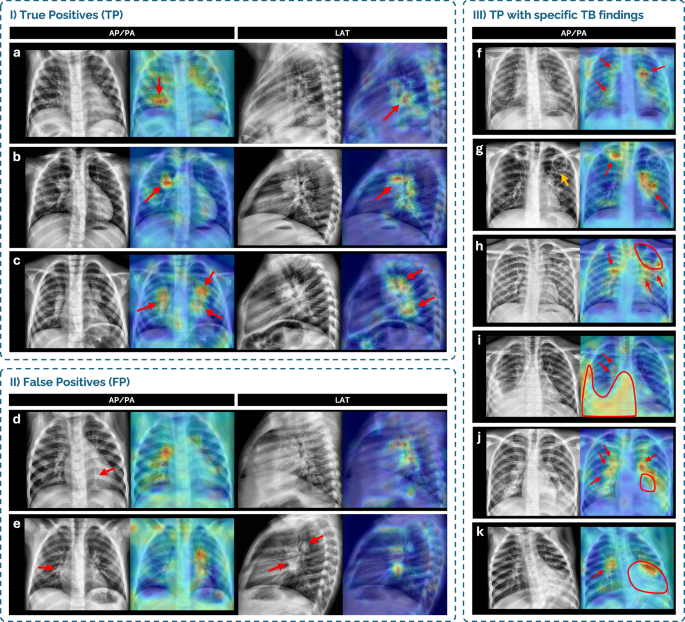
Grad-CAMs highlight regions of interest in AP/PA and LAT chest X-ray (CXR) views for selected cases grouped by prediction type and radiological finding. (I) True positive (TP) cases: a 2-year-old male (cohort 1) with a linear air space opacity in the right lower lobe, correctly detected; b 3-year-old male (cohort 2) with enlarged right hilar lymphadenopathy, correctly detected; c 3-year-old male (cohort 2) with enlarged bilateral hilar lymphadenopathy, correctly detected. (II) False positive (FP) cases: d 1-year-old female (cohort 1), classified as unlikely TB, showing a suspicious linear opacity consistent with subsegmental atelectasis (red arrow) in the retrocardiac area, not detected. Grad-CAM highlight is not consistent with a true finding; e 3-year-old female control (cohort 2), with presumed enlarged lymph nodes on both projections, partially detected although misclassified. (III) TP cases with specific TB findings: f 5-year-old male (cohort 2) with diffuse miliary pattern and enlarged hilar lymph nodes, correctly highlighted; g 13-year-old male (cohort 2) with two upper lobe cavitary lesions—Grad-CAM misses a left upper lobe cavity (orange arrow) but highlights left hilar lymph nodes and a right upper lobe cavity; h 16-year-old male (cohort 2) with a large left upper lobe cavity, partially detected, and enlarged bilateral hilar lymph nodes, detected; i 9-year-old male with a large right lower lobe opacity with pleural effusion, and enlarged hilar lymph nodes, all highlighted; j 14-year-old female (cohort 2) with bilateral enlarged hilar lymph nodes (correctly highlighted) and a large left lower lobe opacity with cavitation (partially highlighted); k 1-year-old female (cohort 1) with enlarged right hilar lymph nodes and a large left lower lobe opacity with cavitation, with Grad-CAM highlighting the lymphadenopathies but partially the opacity.