
![]()
If AI is to become pervasive, as the model builders and datacenter builders who are investing enormous sums of money are clearly banking on it to be, then it really goes have to be a global phenomenon. And as such, it will require global-scale computing that looms much larger than anything we have seen during the Dot Com boom in the late 1990s and the Big Data boom in the 2010s.
That, in a nutshell, was the message that Richard Ho, head of hardware at GenAI pioneer OpenAI, delivered during his keynote at the AI Infra Summit in Santa Clara this week. We had hoped that Ho might talk about the rumored “Titan” homegrown inference chip that OpenAI is said to be co-developing with the help of Broadcom, which we discussed last week as part of our analysis of that chip maker’s latest financial results. But alas, no.
However, Ho, like his peers at Meta Platforms and Google, did talk about the large-scale infrastructure that would be required as GenAI models embiggen and require increasing amounts of compute and networking.
That networking is key, and is driven by that compute, which has long since outstripped a Moore’s Law pace and needs not just intra-socket interconnects, but intra-rack and cross-rack links to make a bunch of XPU chiplets work together as one. This is, as we have said before, supercomputing truly going mainstream, even if it is focused on the mutterings of humanity mixed with our digital exhaust instead of simulating a galaxy or a hurricane or a DNA molecule or some such. So we are, as you might imagine, intrigued by what OpenAI might do to try to advance the state of the art in AI processing over the next five to ten years. That Ho has had key compute positions at Arm server upstart Calxeda, Google (steering TPU development as well as video encoders and EdgeTPUs for Pixel phones) as well as doing a stint at silicon photonics pioneer Lightmatter is an indicator of what Ho could bring to bear.
If anyone is going to do better than Nvidia at AI processing these days, they have to create something that is better on multiple vectors than a “Blackwell” or “Rubin” GPU accelerator from Nvidia, and they are going to have to think hard about how the systems using it are stitched together into a whole that drives down the cost of inference. Sam Altman & Co know this, and so does Ho. Which is why our expectations for OpenAI’s homegrown accelerators and its Stargate effort are pretty high.
Ho’s presentation at AI Infra Summit frames the narrative about the technology his team is creating, even if it is not specific about that technology.
It all starts with exponential growth, of course, and this chart Ho showed plots the aggregate compute to train a model on the X axis plotted out against the aggregate score on the Massive Multitask Language Understanding (MMLU) tests:
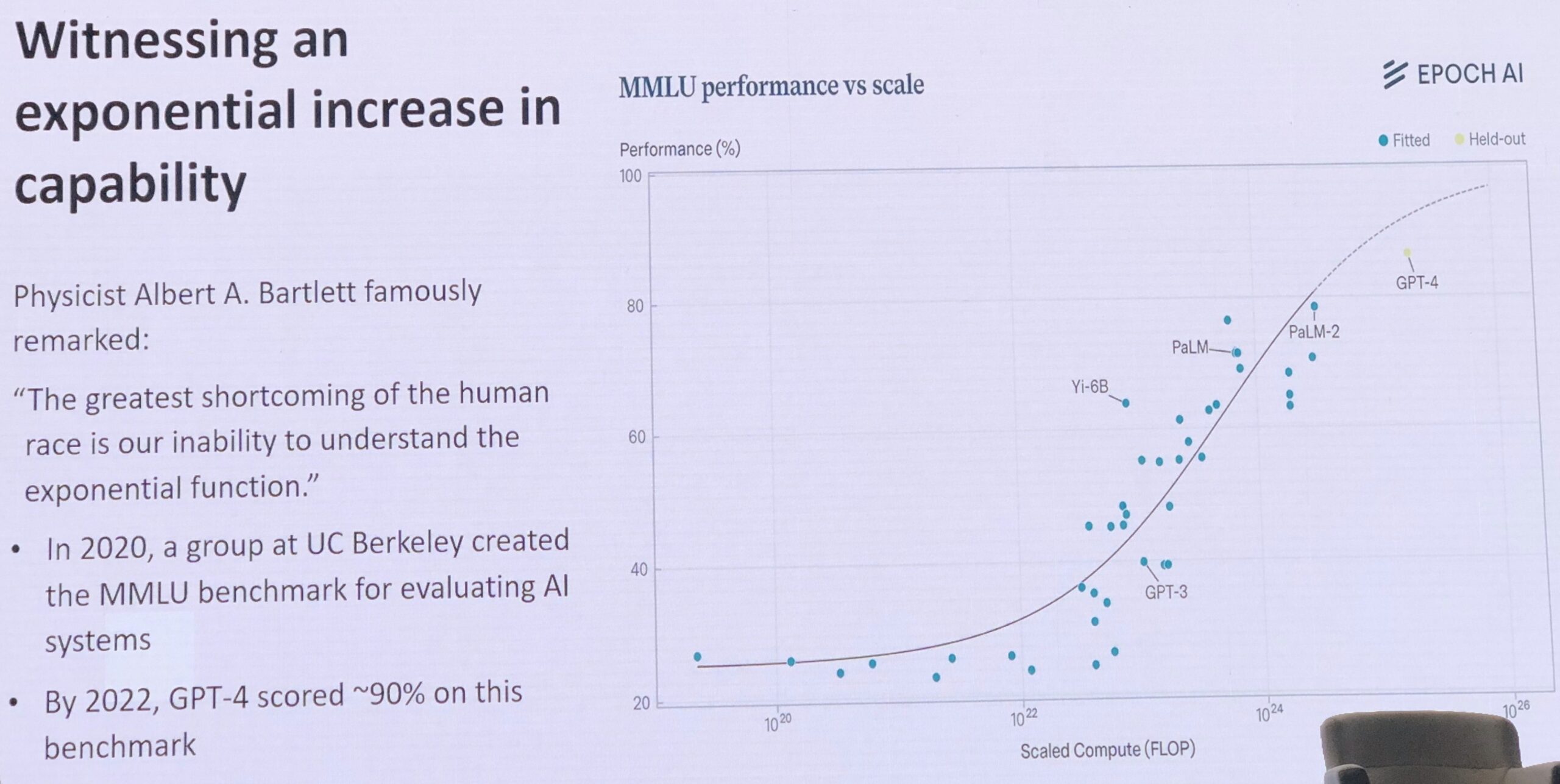
As you can see, the GPT-4 model from OpenAI bent that curve down a bit, and it is interesting that Ho did now show where the GPT 4.5, GPT-5, and o3 models landed on this chart in terms of aggregate flops or what its test scores might be on the MMLU. GPT-5 probably takes somewhere around 1 x 1027 flops and should be asymptotically approaching a 100 percent score on the MMLU test, which means it is no longer a useful test, as Ho pointed out in his talk without being precise in the numbers. (Some contend that the MMLU test is itself flawed and getting much more than 93.5 percent is not possible.) The o3 mixture of experts or chain of thought reasoning model is probably wiggling around 1 x 1026 flops, give or take a bit.
Being a data packrat, we like to gather charts, and this one shown off by Ho was also interesting:
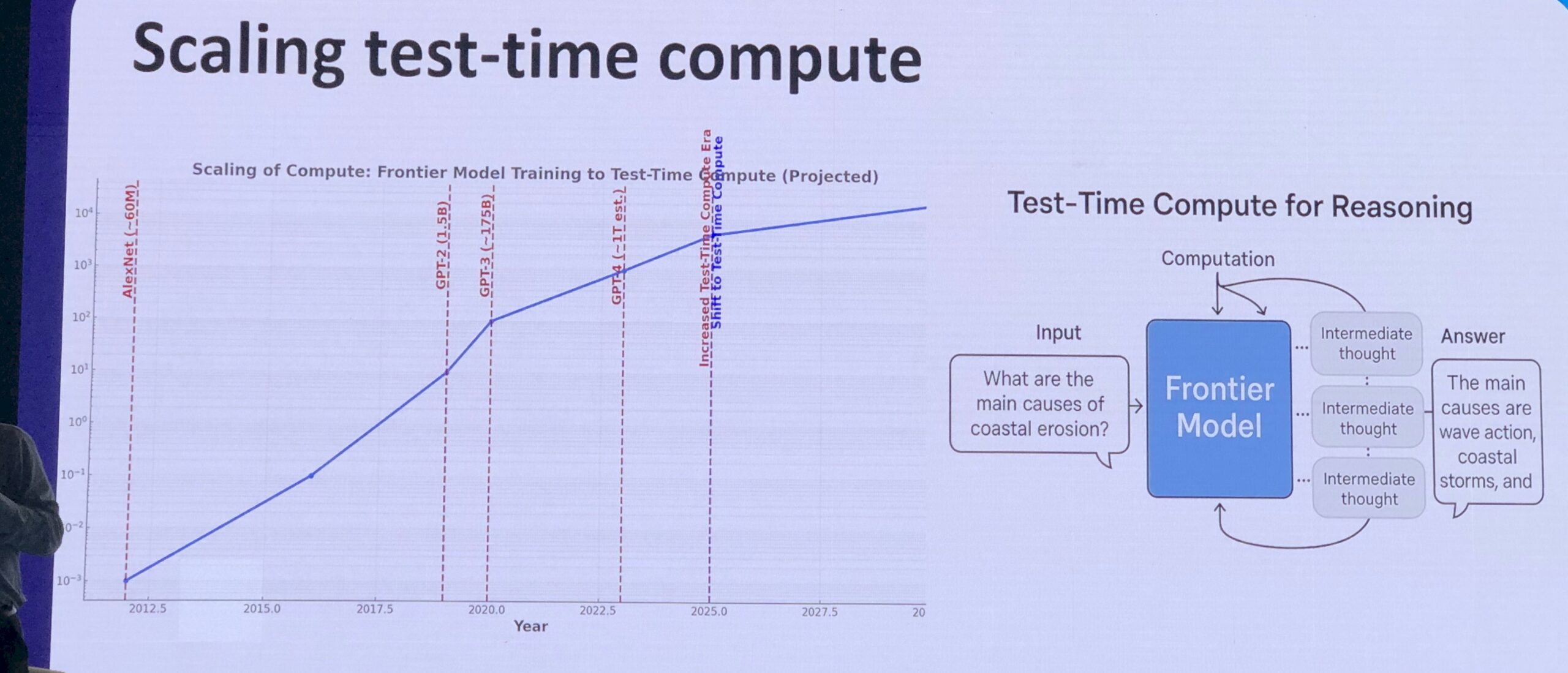
This chart shows the compute over time for image recognition models, starting with AlexNet in 2012 with 60 million parameters to the early GPT-2 frontier model in 2019 with 1.5 billion parameters to GPT-3 with 175 billion parameters to GPT-4 with an “estimated” 1.5 trillion parameters. (Ho knows what this number is, for sure, even if it is not public.)
The Y axis that shows aggregate compute in petaflops is on a log scale, so even though the line flattens between GPT-3 through GPT-4 and out to GPT-5 in 2025 (and reasoning techniques start to get embedded in the mixture of experts models), this is still exponential growth that we are seeing. And this is also true as we look out into 2030 and beyond, if you trust that line Ho extrapolated out from today. We would point out that delivering that compute for even that less steep exponential curves as models go bigger was only economically possible because of ever enshrinkening floating point and integer precision on the math units and data formats used with the models. And even then, training these models has been outrageously expensive and the jury is still out on the return on investment excepting for Nvidia and model builders like OpenAI.

Back in 2009, Luiz André Barroso and Urs Hölzle of Google made a lot of noise with a paper called The Datacenter As A Computer: An Introduction To The Design Of Warehouse-Scale Machines, but Ho is talking about building global-scale computers. And now, as if OpenAI and a few others like Google, Microsoft, and Amazon creating a global scale computer was not enough, the thing is going to run agentic AI workloads that run at computer speed and actually do things as opposed to talk to us at human speeds about what we should know or we should do.
And that, says Ho, is going to have huge implications for the infrastructure and its system architecture.

Here is how Ho put it in his AI Infra Summit keynote:
“One of the biggest evolutions that I am seeing is that we are heading towards an agentic workflow, meaning that most of the work is being done by agents, between many agents,” Ho explained. “And in fact, many agents are long lived, meaning you have a session with an agent. In the old days, you put down your chat with the ChatGPT and then come back to it, it didn’t do anything in between. We are going to move to a state where the agents are actually active – even if you are not typing something in and asking something, because the task might have been a long task or it might be a difficult task, it needs to work in the background. So what does it mean? So long-lived sessions implies the infrastructure is going to need stateful compute and we are going to need memory to support it.”
“We’re going to have to have real-time tools in these – meaning that these agents communicate with each other. Some of them might be looking at a tool, some might be doing a website search. Others are thinking, and others need to talk to each other. We need to have a low-latency interconnect so these things are actually synced and they are actually doing the right thing. And it’s going to be spread out for many days, and the volume is going to be very large. And when we have a lot of these, the tail latencies are going to be super important. If you have an agent that’s out there and it’s got something that’s important for the other agents to know about, and it takes time for that agent to come back, it could actually affect the results.”
There is “a lot of tension” right now in AI system designs when it comes to networking, said Ho, which we think is a wry understatement done exactly correctly for effect.
There are other tensions in the compute, networking, and storage for these future AI systems, and Ho rattled them off without revealing how OpenAI and its partners might solve them:
HBM4 and HBM4E memory capacity and memory bandwidth walls and the use of CXL memory pools to try to alleviate some of the pressure.
2.5D and 3D chip integration to cram components onto areas larger than the chip reticle limit
Co-packaged and near-package optics to overcome the limits of copper interconnects coming off XPUs and switches
Heterogeneity in compute with blends of CPUs, XPUs, and NPUs
Rackscale systems that are well above 100 kilowatts of aggregate power that require direct to chip liquid cooling and may require immersive cooling as power goes up to 600 kilowatts per rack and even 1 megawatt in the not-too-distant future.
Numerous supply chain issues, such as substrate and HBM memory shortages, unequal distribution of EUV tools around the world.
Root of Distrust
One of the big themes at all of the big model builders – and something that is contentious – is called alignment, which has to do with the safety and reliability of the models as they are running in production.
“It has to be built into the hardware,” Ho declared. “Today a lot of safety work is in the software. It assumes that your hardware is secure. It assumes that your hardware will do the right thing. It assumes that you can pull the plug on the hardware. I am not saying that we can’t pull the plug on that hardware, but I am telling you that these things are devious, the models are really devious, and so as a hardware guy, I want to make sure of that.”
To which Ho is proposing that real-time kill switches be integrated into the orchestration fabric of AI clusters. He is also proposing that we have telemetry in the silicon to detect anomalous compute and memory patterns, that we have secure enclaves in CPUs and XPUs and trusted execution paths to enforce alignment policies at the chip level.
“I think we need a new infrastructure for this new age,” Ho concluded in his talk. “We don’t have good benchmarks for agent-aware architectures and hardware, and I think it is important to know about latency walls and latency tails, what is the efficiency and power and things like that. We need to have good observability as a hardware feature, not just as a debug tool, but built in and constantly monitoring our hardware. Networking is a real important thing, and as we head towards optical, it is unclear that the reliability of the network is there today. We need to get there with enough testing of these optical testbeds and these other communication testbeds that show that we actually have the reliability.”
Ho’s presentation also noted that he wants to see partnerships across foundries, packagers, and hyperscalers and cloud builders to coordinate the dual sourcing of critical components. Ho ran out of time to discuss this, but this is an easier thing for OpenAI to ask for than it is for any of those parties to give it.

Sign up to our Newsletter
Featuring highlights, analysis, and stories from the week directly from us to your inbox with nothing in between.
Subscribe now
Related Articles