
Earth observation generates data with vastly different levels of detail, ranging from sharp images to broad, low-resolution scans, creating challenges for comprehensive analysis. Nicolas Houdré from Université Paris Cité, Diego Marcos and Hugo Riffaud de Turckheim from UMR TETIS, EVERGREEN, Inria, Univ. Montpellier, and their colleagues address this issue by introducing RAMEN, a new resolution-adjustable multimodal encoder. This innovative system learns to combine data from diverse Earth observation sources, regardless of their original resolution, into a unified and coherent representation. By treating resolution as a controllable parameter, RAMEN allows users to tailor the level of detail in analyses, balancing precision with computational cost, and importantly, it outperforms existing models on standard benchmarks, demonstrating a significant advance in the field of multi-sensor data fusion.
RAMEN Performance Across Varying Resolutions
This document details the performance of RAMEN, a model designed for semantic segmentation, across various datasets and resolutions. Semantic segmentation involves classifying each pixel in an image, and performance is measured using Mean Intersection over Union (mIoU), where higher scores indicate greater accuracy. Researchers evaluated RAMEN at different Ground Sampling Distances (GSDs), which effectively control the resolution of the input imagery, with lower GSD values representing higher resolution. The team compared RAMEN’s performance against other models, including DOFA and TerraMind, considering both accuracy and computational cost.
Results demonstrate a trade-off between resolution and performance, with initial improvements in mIoU as resolution increases. On the CropTypeMapping, South Sudan dataset, RAMEN achieved a peak mIoU of 58. 19% at a GSD of 80, while TerraMind-B achieved the best overall score of 55. 80%. For SpaceNet 7, RAMEN reached 60.
31% mIoU at a GSD of 8, slightly behind DOFA’s leading score of 61. 84%. On the AI4SmallFarms dataset, RAMEN achieved 38. 78% mIoU at a GSD of 10, surpassing TerraMind-B’s best of 28. 12%. These findings highlight the importance of selecting an appropriate GSD, balancing accuracy with computational demands. RAMEN demonstrates competitive performance across different datasets and resolutions, but its effectiveness varies depending on the specific data and desired level of detail.
Resolution-Adjustable Multimodal Earth Observation Encoding
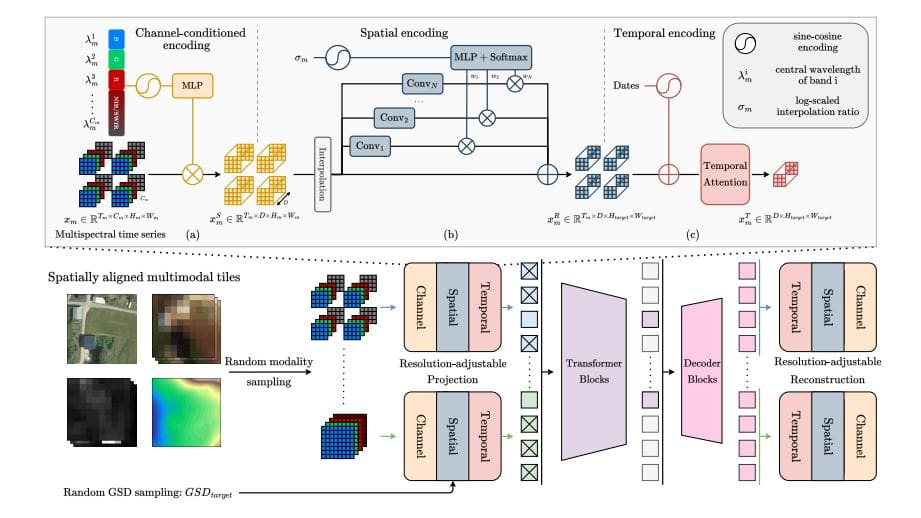
Scientists have developed RAMEN, a novel resolution-adjustable multimodal encoder designed to overcome limitations in processing diverse Earth observation (EO) data. This innovative system learns a shared visual representation across data varying in spatial, spectral, and temporal resolution, enabling coherent analysis within a unified latent space. A key achievement lies in defining spatial resolution as a controllable output parameter, allowing users to directly manage the level of detail and balance precision with computational cost. RAMEN processes modality and resolution as key input features, projecting each into a latent space based on its characteristics.
An adjustable spatial resampler aligns heterogeneous inputs by mapping them to a target GSD, randomly chosen during training to ensure generalization across scales. This prevents bias towards specific resolutions and allows users to define the desired level of detail during analysis. The system also incorporates a temporal attention module to capture dependencies across time. Researchers trained RAMEN on a large-scale multimodal EO corpus using a self-supervised masked image modeling strategy, reconstructing randomly masked regions to ensure robust learning. All learnable parameters are shared across modalities, maximizing adaptability and enabling training on highly diverse datasets. The resulting system outperforms larger state-of-the-art models on the PANGAEA benchmark, demonstrating its effectiveness in various multi-sensor and multi-resolution downstream tasks.
Resolution-Adjustable Multimodal Earth Observation Encoding
Researchers have developed RAMEN, a new approach to processing Earth observation (EO) data that achieves state-of-the-art performance on the PANGAEA benchmark. RAMEN is a resolution-adjustable multimodal encoder, effectively combining data from various sensors and resolutions while allowing users to control the level of detail in the analysis. This is achieved by treating spatial resolution as a controllable output parameter, enabling a direct trade-off between precision and computational cost. The team trained RAMEN on a large-scale corpus of EO data, combining datasets including FLAIR-HUB, WorldStrat, and MMEarth64, encompassing diverse land cover types and sensor configurations.
This extensive training allowed RAMEN to generalize effectively across different sensors and resolutions, a key advantage over existing models. Experiments demonstrate that RAMEN achieves an average mIoU of 60. 03 across eight downstream semantic segmentation tasks, surpassing the previous state-of-the-art model, TerraMindv1-L, which achieved 59. 10 mIoU. Notably, RAMEN achieves this performance with a lighter ViT-Base encoder, indicating improved efficiency.
Further analysis reveals the benefits of RAMEN’s adjustable resolution. By varying the target GSD at inference, the team demonstrated a clear trade-off between spatial precision, computational cost, and task performance. For example, on the HLS BurnScars dataset, RAMEN achieves a mIoU of 360 when using a GSD of 30 meters, showcasing its ability to maintain accuracy even at lower resolutions. These results highlight RAMEN’s potential for a wide range of applications, from land cover mapping and flood detection to wildfire monitoring, offering a flexible and efficient solution for analyzing complex Earth observation data.
Adjustable Resolution Encoding for Earth Observation
Researchers have developed RAMEN, a new resolution-adjustable encoder for Earth observation data, which learns a shared visual representation across diverse data types and resolutions. This model uniquely treats spatial resolution as a controllable parameter, allowing users to adjust the level of detail during analysis and balance precision with computational cost. Through training on masked multimodal Earth observation data, RAMEN demonstrates generalization across different sensors and resolutions, outperforming existing state-of-the-art models on the PANGAEA benchmark. This achievement establishes a scalable foundation for general-purpose Earth observation models capable of adapting to various sensor configurations and application needs. Notably, RAMEN’s ability to handle temporal data without requiring additional fine-tuning surpasses the performance of specialized temporal models.