
Intro
applications powered by Large Language Models (LLMs) require integration with external services, for example integration with Google Calendar to set up meetings or integration with PostgreSQL to get access to some data.
Function calling
Initially these kinds of integrations were implemented through function calling: we were building some special functions that can be called by an LLM through some specific tokens (LLM was generating some special tokens to call the function, following patterns we defined), parsing and execution. To make it work we were implementing authorization and API calling methods for each of the tools. Importantly, we had to manage all the instructions for these tools to be called and build internal logic of these functions including default or user-specific parameters. But the hype around “AI” required fast, sometimes brute-force solutions to keep the pace, that is where MCPs were introduced by the Anthropic company.
MCPs
MCP stands for Model Context Protocol and today it is a standard way of providing tools to the majority of the agentic pipelines. MCPs basically manage both integration functions and LLM instructions to use tools. At this point some may argue that Skills and Code execution that were also introduced by the Anthropic lately have killed MCPs, but in fact these features also tend to use MCPs for integration and instruction management (Code execution with MCP — Anthropic). Skills and Code execution are focused on the context management problem and tools orchestration, that is a different problem from what MCPs are focused on.
MCPs provide a standard way to integrate different services (tools) with LLMs and also provide instructions LLMs use to call the tools. However, here are a couple of problems:
Current model context protocol supposes all the tool calling parameters to be exposed to the LLM, and all their values are supposed to be generated by the LLM. For example, that means the LLM has to generate user id value if function calling requires it. That is an overhead because the system, application knows user id value without the need for LLM to generate it, moreover to make LLM informed about the user id value we have to put it to the prompt (there is a “hiding arguments” approach in FastMCP from gofastmcp that is focused specifically on this problem, but I haven’t seen it in the original MCP implementation from Anthropic).
No out-of-the-box control over instructions. MCPs provide description for each tool and description for each argument of a tool so these values are just used blindly in the agentic pipelines as an LLM API calling parameters. And the description are provided by the each separate MCP server developer.
System prompt and tools
When you are calling LLMs you usually provide tools to the LLM call as an API call parameter. The value of this parameter is retrieved from the MCP’s list_tools function that returns JSON schema for the tools it has.
At the same time this “tools” parameter is used to put additional information to the model’s system prompt. For example, the Qwen3-VL model has chat_template that manages tools insertion to the system prompt the following way:
“…You are provided with function signatures within XML tags:\\n\” }}\n {%- for tool in tools %}\n {{- \”\\n\” }}\n {{- tool | tojson }}\n {%- endfor %}…”
So the tools descriptions end up in the system prompt of the LLM you are calling.
The first problem is actually partially solved by the mentioned “hiding arguments” approach from the FastMCP, but still I saw some solutions where values like “user id” were pushed to the model’s system prompt to use it in the tool calling — it is just faster and much simpler to implement from the engineering point of view (actually no engineering required to just put it to the system prompt and rely on a LLM to use it). So here I am focused on the second problem.
At the same time I am leaving aside the problems related to tons of rubbish MCPs on the market — some of them do not work, some have generated tools description that can be confusing to the model. The problem I focus here on — non-standardised tools and their parameter descriptions that can be the reason why LLMs misbehave with some tools.
Instead of the conclusion for the introduction part:
If your agentic LLM-powered pipeline fails with the tools you have, you can:
Just choose a more powerful, modern and expensive LLM API;
Revisit your tools and the instructions overall.
Both can work. Make your decision or ask your AI-assistant to make a decision for you…
Formal part of the work — research
1. Examples of different descriptions
Based on the search through the real MCPs on the market, checking their tools lists and the descriptions, I could find many examples of the mentioned issue. Here I am providing just a single example from two different MCPs that have different domains as well (in the real life cases the list of MCPs a model uses tend to have different domains):
Example 1:
Tool description: “Generate a area chart to show data trends under continuous independent variables and observe the overall data trend, such as, displacement = velocity (average or instantaneous) × time: s = v × t. If the x-axis is time (t) and the y-axis is velocity (v) at each moment, an area chart allows you to observe the trend of velocity over time and infer the distance traveled by the area’s size.”,
“Data” property description: “Data for area chart, it should be an array of objects, each object contains a `time` field and a `value` field, such as, [{ time: ‘2015’, value: 23 }, { time: ‘2016’, value: 32 }], when stacking is needed for area, the data should contain a `group` field, such as, [{ time: ‘2015’, value: 23, group: ‘A’ }, { time: ‘2015’, value: 32, group: ‘B’ }].”
Example 2:
Tool description: “Search for Airbnb listings with various filters and pagination. Provide direct links to the user”,
“Location” property description: “Location to search for (city, state, etc.)”
Here I am not saying that any of these descriptions is incorrect, they are just very different from the format and details perspective.
2. Dataset and benchmark
To prove that different tools descriptions can change model’s behavior I used NVidia’s “When2Call” dataset. From this dataset I took test samples that have multiple tools for the model to choose from and one tool is the correct choice (it is correct to call a specific tool rather than any other or than to provide a text answer without any tool call, according to the dataset). The idea of the benchmark is to count correct and incorrect tool calls, I also count “no tool calling” cases as an incorrect answer. For the LLM I selected OpenAI’s “gpt-5-nano”.
3. Data generation
The original dataset provides just a single tool description. To create alternative descriptions for each tool and parameter I used “gpt-5-mini” to generate it based on the current one with the following instruction to complicate it (after generation there was an additional step of validation and re-generation when necessary):
“””You will receive the tool definition in JSON format. Your task is to make the tool description more detailed, so it can be used by a weak model.
One of the ways to complicate — insert detailed description of how it works and examples of how to use.
Example of detailed descriptions:
Tool description: “Generate a area chart to show data trends under continuous independent variables and observe the overall data trend, such as, displacement = velocity (average or instantaneous) × time: s = v × t. If the x-axis is time (t) and the y-axis is velocity (v) at each moment, an area chart allows you to observe the trend of velocity over time and infer the distance traveled by the area’s size.”,
Property description: “Data for area chart, it should be an array of objects, each object contains a `time` field and a `value` field, such as, [{ time: ‘2015’, value: 23 }, { time: ‘2016’, value: 32 }], when stacking is needed for area, the data should contain a `group` field, such as, [{ time: ‘2015’, value: 23, group: ‘A’ }, { time: ‘2015’, value: 32, group: ‘B’ }].”
Return the updated detailed description strictly in JSON format (just change the descriptions, do not change the structure of the inputted JSON). Start your answer with:
“New JSON-formatted: …”
“””
4. Experiments
To test the hypothesis I did a couple of tests, namely:
Measure the baseline of the model performance on the selected benchmark (Baseline);
Replace correct tool descriptions (including both tool description itself and parameters descriptions — the same for all the experiments) with the generated one (Correct tool replaced);
Replace incorrect tools descriptions with the generated (Incorrect tool replaced);
Replace all tools description with the generated (All tools replaced).
Here is a table with the results of these experiments (for each of the experiments 5 evaluations were executed, so in addition to accuracy standard deviation (std) is provided):
MethodMean accuracyAccuracy stdMaximum accuracy over 5 experimentsBaseline76.5%0.0379.0%Correct tool replaced80.5%0.0385.2%Incorrect tool replaced75.1%0.0176.5%All tools replaced75.3%0.0482.7%Table 1. Results of the experiments. Table prepared by the author.
Conclusion
From the table above it is evident that tools complication introduce bias to the model, selected LLM tends to choose the tool with more detailed description. At the same time we can see that extended description can confuse the model (in the case of all tools replaced).
The table shows that tools description provides mechanisms to manipulate and significantly adjust model’s behaviour / accuracy, especially taking into account that the selected benchmark operates with a small number of tools at each model call, the average number of used tools at each sample is 4.35.
At the same time it clearly indicates that LLMs can have tools biases that potentially can be misused by MCP providers, that can be similar biases to those I reported before — style biases. Research of the biases and their misuse can be important for further studies.
Engineering a solution
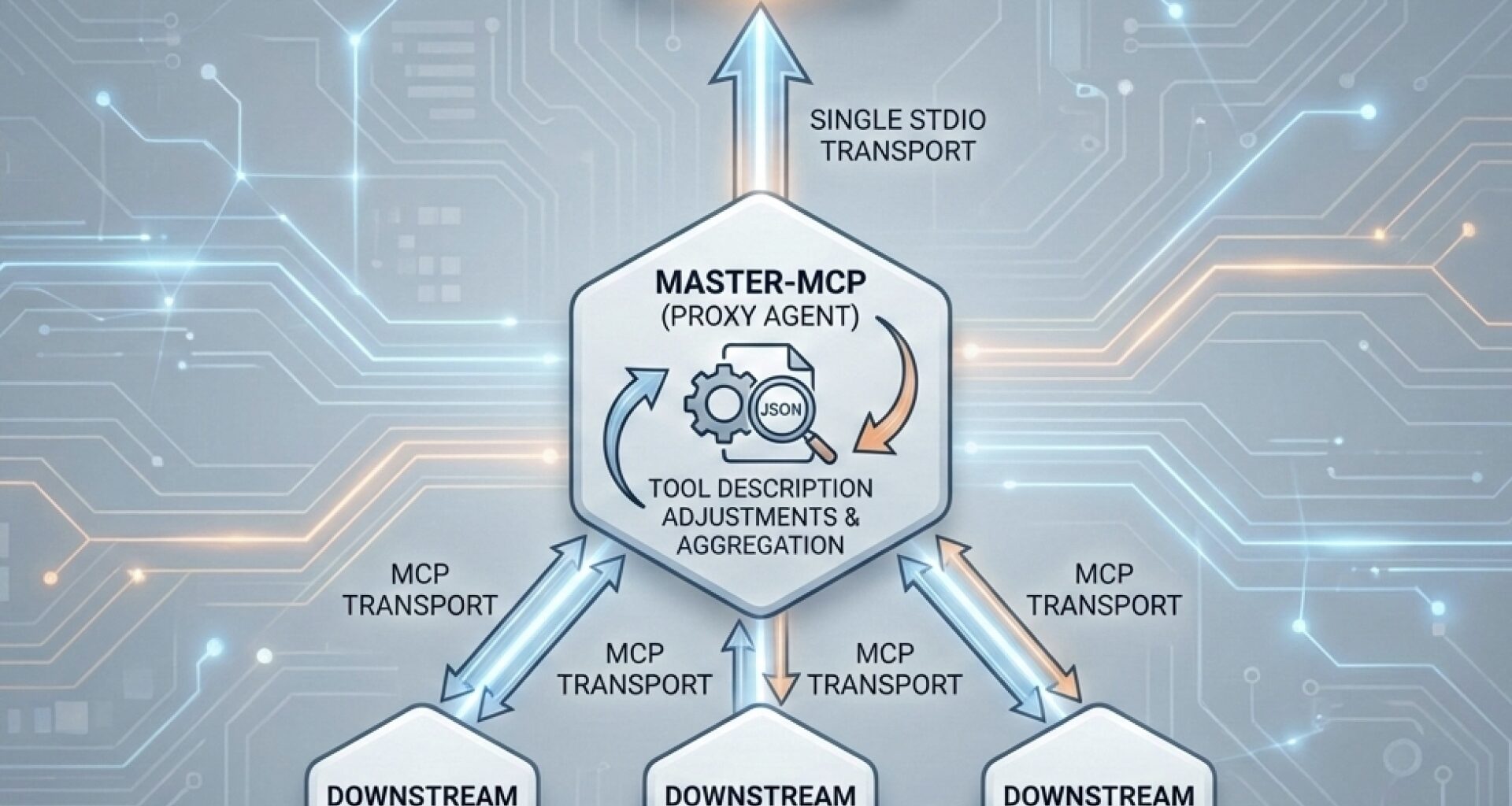
I’ve prepared a PoC of tooling to address the mentioned issue in practice — Master-MCP. Master-MCP is a proxy MCP server that can be connected to any number of MCPs and also can be connected to an agent / LLM as a single MCP-server itself (currently stdio-transport MCP server). Default features of the Master-MCP I’ve implemented:
Ignore some parameters. The implemented mechanics exclude all the parameters that start with “_” symbol from the tool’s parameters schema. Later this parameter can be inserted programmatically or use default value (if provided).
Tool description adjustments. Master-MCP collects all the tool’s and their descriptions from the connected MCP servers and provide a user a way to adjust it. It exposes a method with the simple UI to edit this list (JSON-schema), so the user can experiment with different tools’ descriptions.
I invite everyone interested to join the project. With the community support the plans can include Master-MCP’s functionality extension, for example:
Logging and monitoring followed by the advanced analytics;
Tools hierarchy and orchestration (including ML powered) to combine both modern context management techniques and smart algorithms.
Current github page of the project: link