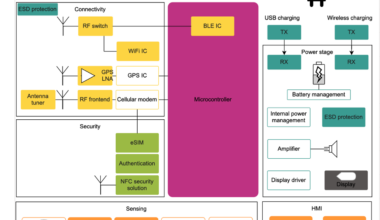
German healthtech Gardia zips €8.5M to equip seniors with AI fall-detection wristbands — TFN
Falls remain one of the most serious threats to older adults, often resulting in long recovery periods, reduced…

Browsing Category