
Study design and data corpus
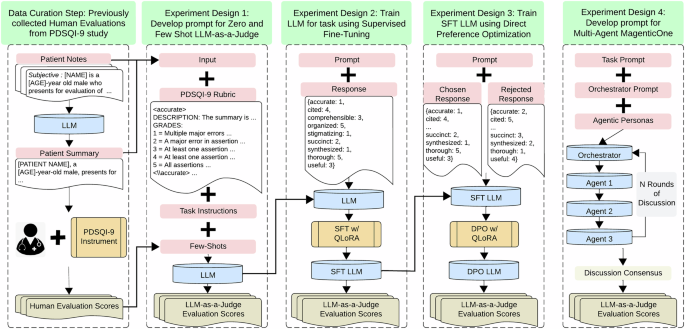
The data used in this study comes from the original PDSQI-9 study23, including the original corpus of notes, LLM-generated summaries, and scores from physician evaluators. The corpus of notes was designed for multi-document summarization and evaluation using inpatient and outpatient encounters from the University of Wisconsin Hospitals and Clinics (UW Health) in Wisconsin and Illinois between March 22, 2023 and December 13, 2023. The evaluation was conducted from the provider’s perspective during the initial office visit (the ’index encounter’)—the clinic appointment where the provider would benefit from a summary of the patient’s prior visits with outside providers. Other inclusion and exclusion criteria were the following: (1) patient was alive at time of index encounter with provider; (2) patient had at least one encounter in 2023; and (3) excluded psychiatry notes. Psychotherapy notes were excluded due to their highly sensitive nature and additional regulatory protections under HIPAA and 42 CFR Part 2, which require approvals beyond the minimal necessary standard for research. Each patient had multiple encounters (3, 4, or 5) for which the LLM was tasked to generate a summary. To stay within the context window limitations of available LLMs during experimentation, we selected patients with 3 to 5 prior encounters for summarization. This range preserved meaningful longitudinal information while ensuring the full input (notes + summary + rubric) remained within the token limits of models like Llama 3.1 (8000-token maximum). The median number of tokens in the concatenated notes was 5101 (IQR: 3614–7464). This also allowed for feasible manual review by clinician evaluators. This study was reviewed by the University Wisconsin-Madison Institutional Review Board (IRB; 2023-1252) and determined it to be exempt human subjects research. The IRB approved the study with a waiver of informed consent. The summaries were evaluated using the perspective of the provider whose perspectives ranged across five different groups of specialties: Primary Care, Surgical Care, Emergency/Urgent Care, Neurology/Neurosurgery, and Other Specialty Care. The original 200 summaries were split into a training/development set of 160 and a test set of 40 for all LLM-as-a-Judge experiments. The characteristics of each set are shown in Table 1. The test set of 40 summaries was selected to ensure detailed expert evaluation across all PDSQI-9 attributes while maintaining feasibility. Each summary was reviewed by seven physicians, resulting in 280 attribute-level scores and allowing for robust reliability estimation.
The LLM-as-a-Judge approach outlined in this study was tested using several top-performing large language models (LLMs) from both open-source and closed-source categories, including reasoning and non-reasoning models. The open-source models used in this study were Mixtral 8 × 22B, Llama 3.1 8B, DeepSeek R1, DeepSeek Distilled Qwen 2.5 32B, DeepSeek Distilled Llama 8B, and Phi 3.5 MoE, while the closed-source models tested were GPT-4o with the 128K context window (version as of 2024-08-06) and GPT-o3-mini (version as of 2025-01-31). To assess model performance, we implemented five prompt engineering strategies: (1) Zero-Shot, (2) Few-Shot, (3) Supervised Fine-Tuning (SFT), (4) Direct Preference Optimization (DPO), and (5) Multi-Agent using MagenticOne. For GPT-4o and GPT-o3-mini, we used Zero-Shot and Few-Shot prompting for single LLM-as-a-Judge as well as for within the Multi-Agent framework. The DeepSeek models (R1 760B, Distilled Qwen 2.5 32B, and Distilled Llama 8B) were restricted to Zero-Shot prompting per recommendations in their GitHub model cards37. Mixtral 8 × 22B and Llama 3.1 8B were evaluated with a broader range of approaches — Zero-Shot, Few-Shot, SFT, and DPO — due to their smaller computational requirements, which make them more amenable for customizations compared with larger models.
GPT-4o, GPT-o3-mini, and DeepSeek R1 were operated within the secure environment of the health system’s HIPAA-compliant Azure cloud. No PHI was transmitted, stored, or used by OpenAI for model training or human review. All interactions with proprietary closed-source LLMs were fully compliant with HIPAA regulations, maintaining the confidentiality of patient data. The smaller, open-source LLMs were downloaded from HuggingFace29 to HIPAA-compliant, on-premise servers. The on-premise servers were equipped with two NVIDIA H100 80GB GPUs and were supported by an NVIDIA AI Enterprise software license. We followed the transparent reporting of a multi-variable model for individual prognosis or diagnosis (TRIPOD)-LLM guidelines, and the accompanying checklist is available in Supplementary Note 2.
Expert human evaluation rubric and scores
Human evaluations using the Provider Documentation Summarization Quality Instrument (PDSQI-9) were used to benchmark the LLM-as-a-Judge frameworks. The instrument consists of grading rubrics for nine attributes: Cited, Accurate, Thorough, Useful, Organized, Comprehensible, Succinct, Synthesized, and Stigmatizing. These attributes and their associated Likert or binary scales were developed using a semi-Delphi consensus methodology and validated across multiple psychometric properties. The instrument demonstrated strong internal consistency (Cronbach’s α = 0.879, 95% CI: 0.867–0.891), high inter-rater reliability (ICC = 0.867, 95% CI: 0.867–0.868), and moderate agreement by Krippendorff’s α = 0.575. Seven physician raters from varied specialties and levels of seniority evaluated a total of 779 summaries, scoring over 8000 items, achieving over 80% power for inter-rater reliability. No significant differences were observed in scoring between junior and senior raters, supporting reliability across experience levels23. The dataset spanned the full range of PDSQI-9 scores across all attributes. Although not every rater evaluated all 200 summaries, all human evaluations were included for training or validation of the LLM-as-a-Judge frameworks.
Single LLM design and implementation (LLM-as-a-Judge)
The task prompt used was iteratively designed to replicate the information provided to human reviewers during their evaluations. For each evaluation, reviewers received the full set of patient notes, the corresponding summary, and the specialty of the physician for whom the summary was intended (https://git.doit.wisc.edu/smph-public/dom/uw-icu-data-science-lab-public/pdsqi-9). In addition, the human evaluation rubric was reformatted for compatibility with LLM-as-a-Judge, following industry-standard prompting conventions. This included clearly marking each attribute with specific tags, such as < accurate > , and using uppercase text to distinguish attribute descriptions from grade definitions. Detailed instructions were also provided to the LLM-as-a-Judge regarding the task and expected output format. The LLM-as-a-Judge was instructed to return scores as a JSON-formatted string where each key corresponded to an attribute of the PDSQI-9. These instructions were human-drafted and refined through multiple iterations, informed by rounds of beta testing and output verification. They were also passed through the CliniPrompt software7 and GPT4o for additional refinement. Manual prompts are designed using four key components: minimizing perplexity, in-context examples, chain-of-thought reasoning, and self-consistency. Prompts were iteratively refined through zero-shot (no examples) to few-shot (up to five examples) learning approaches, with random sampling from the training data. Full examples of the prompt are available at https://github.com/epic-open-source/evaluation-instruments/tree/main/src/evaluation_instruments/instruments/pdsqi_9. The same prompt was used for every model, except for the DeepSeek-based models, which had a ” < think > ” token appended to align with their recommended usage settings37. Additionally, inference parameters were fine-tuned for optimal performance across models. The number of shots for few-shot prompting was determined by testing with 1, 3, and 5 shots and selecting the configuration that yielded the best performance. The final hyperparameter settings for both zero-shot and few-shot prompting are detailed in Table 4.
Table 4 Single LLM-as-a-Judge Inference Settings
For the training phase of the experiments, both SFT and DPO were implemented using Hugging Face’s TRL library, with SFTTrainer for SFT and DPOTrainer for DPO38. The datasets for each approach were prepared according to the specifications of their respective trainer implementations. Specifically, SFT required a dataset of prompt-completion pairs, while DPO required a dataset consisting of prompt-response pairs, including both a ”chosen” and a ”rejected” response. The prompt used for SFT was identical to that used in the zero-shot and few-shot prompting setups. Each completion for SFT consisted of a single JSON string representing the evaluation of a summary by one of the expert human reviewers. During training, evaluation scores from all human reviewers were included to fine-tune the model based on the collective feedback for each summary. Since DPO was applied to the already fine-tuned SFT version of the LLM, the chosen and rejected response pairs were constructed using the median response from the seven human reviewers. The chosen response was represented by a single JSON string reflecting this median, while the rejected response was a JSON string where each corresponding attribute grade was increased by one point on the Likert scale. The rationale behind making the rejected response have a higher Likert score than the chosen one was to encourage the model to be more conservative in its evaluations, rather than overly lenient.
To reduce computational costs while maintaining model accuracy, we employ quantization techniques that lower numerical precision from floating-point (e.g., float32) to fixed-point (e.g., int8)39. We also utilize Quantized Low-Rank Adapters (QLoRA), which combine quantization with low-rank adaptation to optimize efficiency40. QLoRA fine-tunes only selected layers while keeping the base LLM frozen, significantly reducing resource demands. QLoRA was employed for both SFT and DPO, with all training conducted using 4-bit quantization of the respective models through a BitsAndBytes configuration. The LoRA parameters, including rank and alpha, were optimized using a quasi-Bayesian approach implemented via Optuna41. Due to memory constraints, the LoRA parameters for Mixtral 8 × 22B in both SFT and DPO were restricted, and similar limitations were encountered with Llama 3.1 8B for DPO. The final QLoRA parameters are detailed in Table 5.
Table 5 QLoRA settings for training
Table 6 presents the final settings for the remaining training hyperparameters. The batch size for each setup was chosen based on our computational limitations, with the largest feasible batch size being selected. For SFT, the learning rate was determined through a quasi-Bayesian optimization approach implemented via Optuna until training and evaluation losses exhibited convergence without overfitting. In contrast, DPO involved tuning both the learning rate and the beta parameter, the latter being part of the DPO optimization algorithm. These hyperparameters were optimized based on the evaluation rewards/margins metric, which was automatically logged during DPO training.
Table 6 Final training parameter settingsMulti-agent design and implementation (LLMs-as-Judges)
In addition to the prompt engineering techniques employed for single-agent implementations of LLM-as-a-Judge, additional refinement was required for the multi-agent approach used in the MagenticOne orchestrator, as well as for crafting the personas of each agent. Initially, a human-drafted prompt was created for the orchestrator, designed for basic debugging and initial testing. This prompt was then fed to multiple LLMs, including Gemini Flash 2.0, GPT4o, Grok3, and DeepSeek R1, with the instruction: “Please write a prompt for MagenticOne that takes as input extractive summarization from LLM agents, analyzes the inputs, and determines which summarization is the most accurate.” These four LLM-generated prompts were manually combined into one, which was then further refined based on testing. During this process, it became evident that the orchestrator struggled with variations in wording related to the concept of extraction, as well as with determining the correct number of discussion rounds. The final prompt to the MagenticOne orchestrator was ”You are a clinical documentation evaluation expert that specializes in text analysis and reasoning. Your task is to analyze and reason over multiple evaluations generated by different Large Language Model (LLM) agents that you will create for the same text input and follow the provided rubric and instructions to determine the final score for each attribute in the rubric. Indicate the start and end of each round of discussion with the LLM agents. Please enforce the LLM agents are following the rubric grades as outlined. After hearing input from the other agents, you will make the final decisions. Provide your reasoning when generating the final output, and ensure that you have assessed the arguments from the agents into your own reasoning. Do not take an average of the scores, but instead critically analyze each input before determining a final score. Always include a JSON-formatted string that represents your final grading results. Here is the rubric and the note text: {rubric and note text}”.
We experimented with two schema designs for establishing personas among the three agents in the discussion. The first schema aimed to represent distinct personas that a primary care physician might embody: the Analytical Perfectionist, the Efficient Multitasker, and the Collaborative Team Player. Each agent was tasked with prioritizing a specific aspect of high-quality summarization in alignment with its assigned persona. The second schema framed the agents as representing different perspectives along an ordinal scale—high, low, and middle scoring—to simulate a range of reviewer stances. In both cases, we manually drafted an initial system message for each agent and refined it iteratively based on a beta set of reviews. The final descriptions and system messages for each agent are presented in Table 7.
Table 7 System Messages for LLM agents in Multi-Agent Workflows
All the multi-agent frameworks were built using Microsoft’s AutoGen implementation with the MagenticOneGroupChat setup27. The participants in the group chat were assigned as one of the two groups of agentic personas outlined previously. Additionally, exploratory analysis was conducted on tunable parameters—max_turns and max_stalls—to optimize the balance between inference time, cost, and overall human alignment. The selection of LLMs for the orchestrator and the three agents was also varied to achieve similar trade-offs. Initial testing used GPT-4o for all agents in the multi-agent framework. Further experimentation was conducted using a more expensive reasoning model, GPT-o3-mini, for the orchestrator and for all agents. Building on insights from single-agent experiments, additional trials incorporated a mix of closed- and open-source models, leveraging the top-performing LLM-as-a-Judge models from the single LLM framework. Mixtral 8 × 22B was deployed as the high-scoring agent due to its consistently lenient evaluation scores. Meanwhile, the low and middle-scoring agents remained GPT-4o, with GPT-o3-mini serving as the orchestrator. Complete results for each approach are available in Supplementary Table 2. However, only the top-performing method was reported in the results section of this study.
Statistical analysis
Baseline characteristics of the corpus notes and evaluators were analyzed. Token counts were derived using the Mixtral 8 × 22B tokenizer. P-values were generated using a chi-square test for categorical variables and a t-test for continuous numerical variables.
The LLM-as-a-Judge was evaluated using multiple metrics to validate its ability to produce scores aligned with human judgments and serve as a substitute for time-intensive human reviews. The primary outcome was inter-rater reliability, assessed using the Intraclass Correlation Coefficient (ICC) to ensure that the LLM-as-a-Judge generated results consistent with expert human reviewers. ICC, derived from analysis of variance (ANOVA), has different forms tailored to specific contexts42. For this study, a two-way mixed-effects model was used, specifically ICC(3,k), which accounts for consistency among multiple raters43. A 95% confidence interval was calculated using the Shrout & Fleiss procedure44. In addition to ICC, evaluation scores were analyzed using the Wilcoxon Signed Rank test, suitable for non-normal paired data, to assess the median differences between scores produced by the LLM-as-a-Judge and human reviewers. For both outcome metrics, the median score of seven human reviewers was compared with the median score of seven iterations from the same LLM-as-a-Judge. In addition, the LLM-as-a-Judge was evaluated both as an 8th evaluator and as a direct substitute for each of the seven human evaluators. The change in ICC among the group of evaluators, before and after the LLM-as-a-Judge was added as a substitute, was assessed using bootstrapping with 1000 iterations, and a two-tailed p-value was calculated to determine statistical significance. Secondary metrics included Gwet’s AC2 and Krippendorf’s α. Gwet’s AC2 and Krippendorf’s α assess the agreement between raters while taking chance agreement into account. 95% Confidence Intervals (CI) were provided for both coefficients and calculated using Gwet’s associated procedure45 and the bootstrap procedure respectively. In additional error analyses, a linear mixed-effects model was used to assess the influence of provider specialty, model type, note length, and summary length on the difference between LLM and human scores, with random intercepts accounting for variability across physicians and evaluation components. Analyses were performed using Python (version 3.10) and R Studio (version 4.3).