
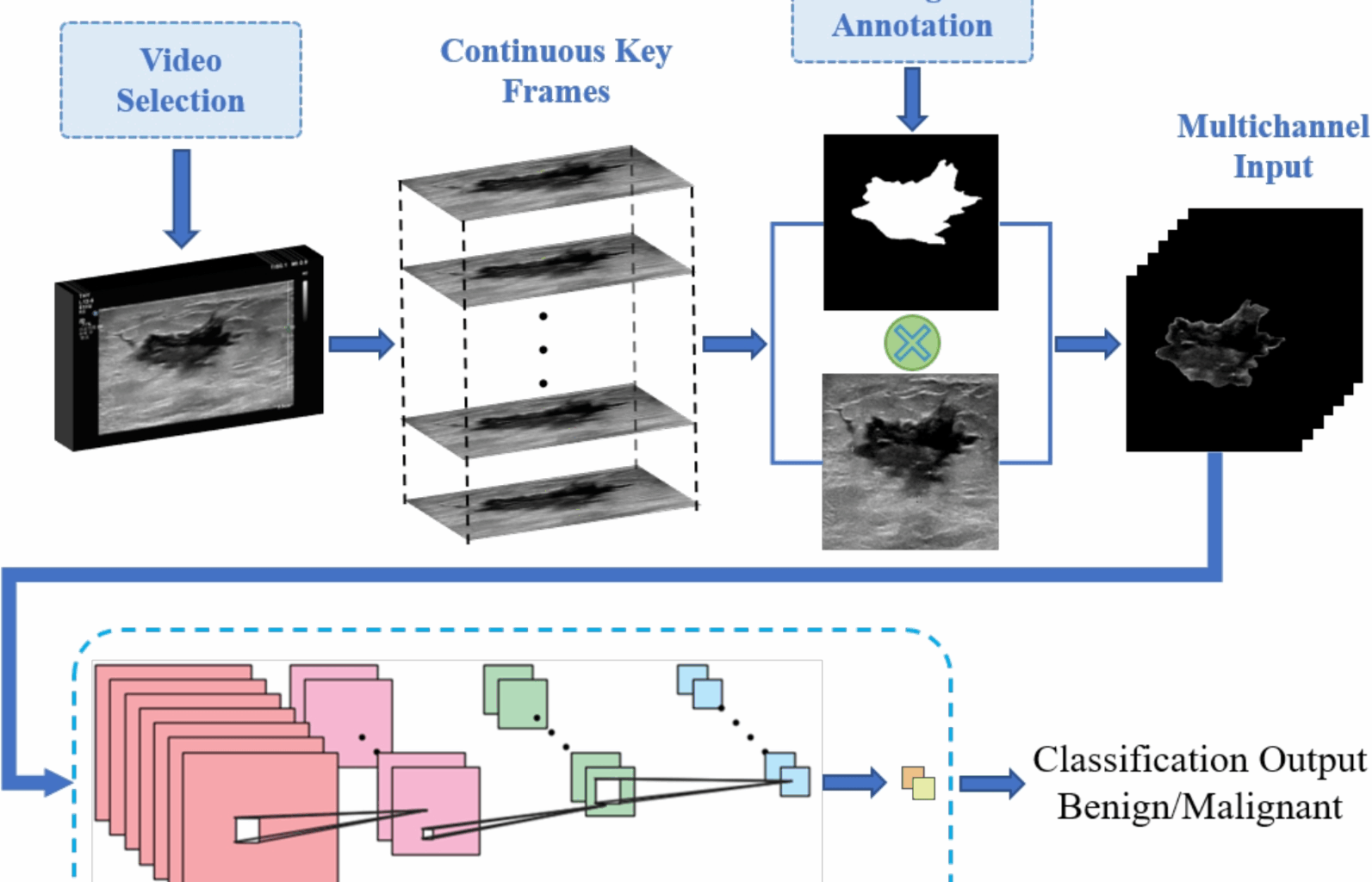
Leveraging temporal information for enhanced breast lesion differentiation
The main objectives of our study are to explore a new approach that leverages both spatial and temporal lesion features to enhance differentiation performance, without increasing computational burdens. Additionally, we aim to thoroughly assess the significance of the critical features embedded in successive frames of dynamic breast ultrasound videos in achieving more accurate breast lesion analysis outcomes. To this end, we conducted a series of experiments involving both single static image input and multi-channel input. For the multi-channel input experiments, two different cases were considered. In case 1, the multi-channel input consists of a concatenation of three static ultrasound images, while in case 2, the multi-channel input comprises seven static ultrasound images. The decision to begin with a single image channel was made to establish a baseline, enabling us to evaluate the model’s performance when only spatial information from a single frame is utilized. This also provided a reference point for the incremental effect of adding temporal information.
In case 1, the use of three consecutive frames allows the model to capture a small yet meaningful temporal window, providing insight into the lesion’s behavior over time. This setup was chosen to evaluate the impact of adding minimal temporal information while maintaining computational efficiency. In case 2, seven consecutive frames are used to provide a more comprehensive temporal representation, offering the model a broader view of lesion dynamics. This configuration was tested to explore whether the inclusion of a larger temporal context significantly improves classification performance. The lesion differentiation results obtained from these experiments are presented below.
Figure 3 illustrates the classification results, represented by AUC metrics, achieved by our proposed method using different backbone network models on two distinct datasets. For internal validation (Fig. 3a), it can be seen that adopting multi-channel input technique leads to significant performance improvement for all five DL backbone models. Specifically, the three-channel input produced better differentiation outcomes compared to the single image input, and this performance was further enhanced when the seven-channel input was used. Transitioning from single image input to three-channel input resulted in AUC value increases ranging from 1.9% to 5.3%, demonstrating the benefit of incorporating additional image frames for richer feature extraction. Even more substantial gains were observed when moving from single image input to seven-channel input, where AUC improvements ranged from 2% to 8.6%. Notably, DenseNet and NextViT exhibited the most substantial performance improvements, with AUC values increasing by 8.6% and 5.2%, respectively. The performance comparison among the considered DL backbone models reveals that DenseNet is the most effective for the proposed lesion differentiation framework, achieving an AUC value of 91.7%.
Fig. 3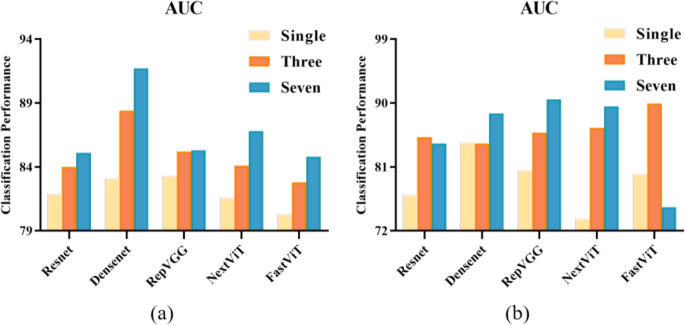
Quantitative evaluation of the classification performance on two distinct datasets. a AUC results on the BUS-Data1’s test set, b AUC results on the external validation set BUS-Data2
Furthermore, Fig. 3b illustrates the results of our external validation using the optimal weights, evaluating the generalizability of our proposed method across different datasets. It can be clearly seen that, compared to single image differentiation outcomes, utilizing multi-channel input enables the capture of a broader range of spatial and temporal features, contributing to more robust and accurate breast lesion differentiation. The most notable improvements were observed in NextViT and FastViT, with AUC values increasing by 15.8% and 9.9%, respectively.
Figure 4 presents the Receiver Operating Characteristic (ROC) curves for the five models evaluated on the internal validation set using a multi-channel input of seven image frames. The curves illustrate the trade-off between the true positive rate (TPR) and false positive rate (FPR) for each model. It can be seen that DenseNet exhibits the most favorable ROC curve, with a near-ideal shape and the highest AUC, indicating superior classification performance. RepVGG and NextViT follow closely, with strong performance but with slightly more pronounced trade-offs between sensitivity and specificity. ResNet, FastViT, and NextViT also perform well, but their curves show greater deviation from the ideal, reflecting some compromises between sensitivity and specificity. These curves show improved trade-offs between the false positive rate and true positive rate for all five models as more temporal information is incorporated, further validating the effectiveness of our proposed multi-channel input strategy.
Fig. 4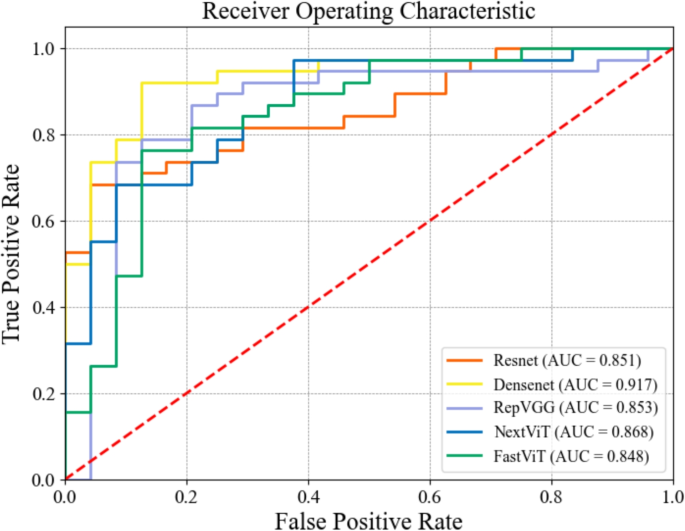
Receiver Operating Characteristic (ROC) curves for the five models using multi-channel input of seven image frames on the internal validation set
Tables 2 and 3 display the classification performance results for the internal validation set and external validation set, respectively. It can be observed that for all five deep learning models, the accuracy, precision, recall, and F1 values significantly improve with the adoption of multi-channel input. Specifically, improvements in precision and recall range from 1.11% to 9.86% and 2.63% to 23.68%, respectively, indicating better overall performance in lesion classification. The greatest improvement on the external validation set was recorded by RepVGG model, achieving an increase in precision and recall of 9.86% and 23.68%, respectively. For the external validation set, improvements in precision and recall range from 0.86% to 9.63% and 4% to 32%, respectively. The most notable performance gain was observed in NextViT model, which demonstrated a 9.63% and 32% increase in precision and recall, respectively. It is important to note that for ResNet, although precision slightly decreased with multi-channel input, the overall classification performance improved, as evidenced by a better F1 score. This indicates that the model was able to achieve a more balanced performance, effectively reducing both false positives and false negatives, despite the slight decline in precision.
Table 2 Differentiation results for the internal validation set (%)Table 3 Differentiation results for the external validation set (%)
Overall, the lesion differentiation results presented above, which encompass various experimental scenarios and different DL backbone models, show that the adoption of the multi-channel input technique significantly enhances the models learning capability and robustness. This leads to improved accuracy in breast lesion analysis, highlighting the effectiveness of leveraging both spatial and temporal features for more reliable lesion differentiation. Moreover, significant improvements are observed in precision, recall, and F1 scores, underscoring the potential of multi-channel input in reducing both false positive and false negative rates. This demonstrates that our proposed framework not only enhances accuracy but also ensures the effectiveness and reliability in detecting malignant samples, thereby guaranteeing the stability of the classification results.
Simultaneous processing of multiple image frames: multi-channel input vs test-time ensemble approach
To further validate the effectiveness of multi-channel input over single image input, additional experiments were conducted where the models were trained using single image inputs and ensemble learning was applied during testing. Specifically, during the testing phase, the trained model processed multiple image frames from a patient, and the results were aggregated using a voting mechanism. The lesion differentiation results on the internal validation set are recorded in Fig. 5. It is observed that for most DL models, the adoption of the multi-channel input strategy led to higher classification metrics compared to the ensemble approach. Furthermore, in some cases, particularly when fewer consecutive video frames were used, the ensemble approach even underperformed relative to single-image input. This suggests that the multi-channel input approach is more effective at leveraging temporal information to enhance lesion differentiation performance in DL models compared to the test-time ensemble approach.
Fig. 5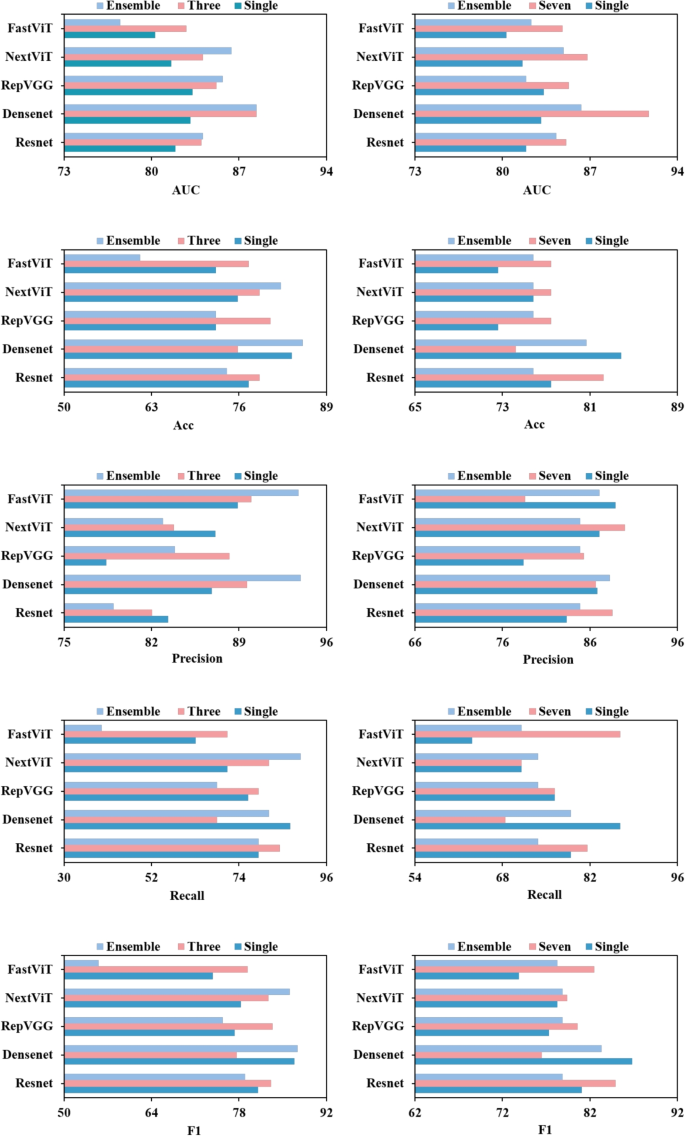
Comparison of the lesion differentiation performance between test-time ensemble approach and multi-channel input strategy. From left to right, the first and second columns represent the comparative results for three and seven image frames, respectively
Comparative analysis of computational efficiency: 2D multi-channel vs 3D approaches
Generally, 3D models come with higher computational costs compared to 2D models, which can make their use challenging in resource-constrained environments. However, 3D models typically outperform 2D models by leveraging the temporal information present in sequential image frames. In contrast, our proposed framework focuses on effectively utilizing temporal information without relying on 3D models, thus mitigating the high computational demands. To highlight the computational efficiency of our approach relative to 3D methods, we conducted comparative experiments using both 2D and 3D models. The classification performance considering seven image frames on the internal validation set is presented in Table 4, while the computational performance of the models is reported in Table 5, with metrics including FLOPs and the number of parameters.
Table 4 Differentiation results (%) for 2D multi-channel and 3D models on the internal validation set (best performance bolded)Table 5 Performance comparison for different models (2D multi-channel and 3D)
It can be seen that, for most DL models, employing our proposed multi-channel input strategy results in better classification performance compared to training with 3D models, while significantly reducing the computational burden. For instance, compared to the 3D model, 2D RepVGG demonstrates improvements of 9.68% in accuracy and 12.79% in precision, along with reductions of 47.1% in FLOPs and 64.3% in the number of parameters. For NextViT, although the AUC value of the multi-channel input increases by only 1.9%, and in some metrics even shows a slight decrease, there is a significant reduction in computational cost: FLOPs decrease by 46.4%, and the number of parameters drops by 13.2%. This reduction means that, in the 2D version, the computational load per inference is nearly halved, resulting in a substantial improvement in processing speed and response time. Therefore, our multi-channel input approach, leveraging 2D models, offers a more computationally efficient solution and tends to outperform 3D models in classification performance.
Limitations and future works
Our experimental analyses indicate that the proposed multi-channel input technique shows strong potential to enhance the performance of DL frameworks in automated breast lesion differentiation. However, additional aspects require further exploration to fully optimize this system.
First, the selection of key frames and delineation of breast lesions were manually performed by radiologists. These steps are not only tedious and time-consuming but also susceptible to subjectivity and inter-observer variability. Future efforts should focus on developing specialized DL techniques for automated key frame selection and lesion delineation to standardize and streamline the workflow, enhancing both efficiency and reproducibility.
Second, although the proposed framework was validated on multicenter data, the datasets used were relatively small, which may limit its generalizability across a broader range of clinical settings. Expanding the dataset with a broader range of imaging conditions and patient demographics could help address this limitation. Additionally, leveraging deep generative models to create synthetic data could further augment the dataset, enhancing model robustness and supporting better generalization across varied clinical environments.
Third, while the proposed framework achieved substantial performance gains, it relied exclusively on single-modality data, even though clinical practice often employs multimodal data for more accurate and efficient diagnosis. Integrating B-mode ultrasound with complementary modalities, such as Color Doppler and shear wave elastography, along with pertinent clinical information, could be an important direction for future exploration. This multimodal approach could not only enhance diagnostic precision but also improve the framework’s adaptability and utility in real-world clinical applications, making it more robust and clinically relevant.