

At the end of New York Climate Week this year, ecologist Robin Whytock spent a few hours in Central Park counting squirrels.His mission was to prove how scalable tech solutions could help make biodiversity monitoring easier and more efficient.Whytock, who runs AI-powered nature monitoring platform Okala, said that while data-gathering tools have become easily accessible, analyzing massive amounts of biodiversity data still remains a challenge.
See All Key Ideas
By the time New York Climate Week wrapped up in September this year, Robin Whytock had a point to make. Over the course of the summit, the ecologist was part of many conversations where scientists and researchers spoke to him about the difficulty in conducting biodiversity surveys.
So when Whytock headed to Central Park on a Saturday morning, he had a mission: demonstrate how technology could help count squirrels in the sprawling park, and compare his results with that of a manual survey done by 300 people in 2018. Over the course of a few hours, walking around with a cup of coffee, Whytock determined that there were 2,979 squirrels living in the park. The result of the 2018 survey, published eight months after it was carried out: 2,373.
“If I can come up with an estimate of the squirrel population in a morning that’s in the ballpark of what was done by a hugely intensive survey with 300 people, let’s think of what’s possible in terms of the scalability of technology,” Whytock, CEO and founder of AI-powered nature monitoring platform Okala, told Mongabay in a video interview.
With his organization, Whytock is now attempting to scale up tech solutions to make biodiversity monitoring easier and more efficient. While sensors are getting cheaper and are more widely available now, Whytock said, the real challenge lies beyond the tech hardware.
“People put all of their budget into data collection and buying sensors, but don’t know how they’re going to analyze the data,” he said. “They end up putting all this money into data that’s sitting on a hard disk that doesn’t become conservation insights.”
 (Left) A 2018 survey which involved 300 volunteers counted 2373 squirrels in Central Park. The results were published eight months after the survey. (Right) The survey conducted by Whytock after the New York Climate Week in 2025 lasted a few hours and counted 2979 squirrels. Images by Robin Whytock.
(Left) A 2018 survey which involved 300 volunteers counted 2373 squirrels in Central Park. The results were published eight months after the survey. (Right) The survey conducted by Whytock after the New York Climate Week in 2025 lasted a few hours and counted 2979 squirrels. Images by Robin Whytock.
Robin Whytock spoke to Mongabay’s Abhishyant Kidangoor about the real intention behind his Central Park expedition, the challenges that exist in biodiversity monitoring, and how tech tools could possibly help bridge the gap. The following interview has been lightly edited for length and clarity.
Mongabay: To start with, tell me what you did at the end of New York Climate Week this year? And why?
Robin Whytock: I am an academic and I have been developing technologies for many years to monitor and study biodiversity. But three years ago, I set up a company to try and take that technology out of academia and into the private sector. People are collecting biodiversity data for all sorts of reasons all over the world. But it still relies on pen-and-paper fieldwork and a lot of boots on the ground. But, at the same time, there have been great advances in technologies for conservation and biodiversity monitoring, like camera traps, eDNA, bioacoustics, satellite data and mobile phone apps. Okala was set up in January 2022 to try and address this data bottleneck in ecological and biodiversity data collection.
At New York Climate Week, I was there for a couple of days to discuss technology and how we use it for biodiversity monitoring. I became aware of the squirrel census that had been done in 2018 in Central Park. The squirrel census is very cool. They’ve got an amazing website where they use over 300 volunteers to try and survey the eastern gray squirrel population in Central Park in order to come up with a population estimate. It is a great way to engage people in nature and also a nice scientific exercise.
But because of the conversations I was having at New York Climate Week, it also struck me: do you really need 300 people to have an estimate of the population of squirrels in Central Park? And in the same conversations, people would tell me, “Biodiversity monitoring or ecological monitoring is so hard. You need so many people. You need so much time in the field and all the expertise.
There is an old-fashioned statistical method called distance sampling. It is a statistical approach to take a subsample of an area and you either walk in lines, like a transect, or you stand at a point and you measure the distance to the objects that you’re trying to estimate the population for.
It’s used for estimating populations of whales in the sea. Once you’ve got your distances, you use some sophisticated modeling and math to say, “This is the distance at which you detect the individuals in your population.” And then you essentially start to use these models to estimate what the total population is likely to be if you extrapolate it out.
We can combine that with technology to collect data digitally on a phone app. Then we can quickly come up with a population estimate of squirrels. I reckoned I could do it in one morning with a coffee in hand on my own. So I went for a walk and I collected the data with my phone and measured all the distances digitally on the map.
I set up roughly 20 sampling stations that sampled Central Park as best as possible in terms of the habitat types. Any squirrel I saw, I would measure the distance from me to the squirrel. I’d put it on a map. The reason you do it over a short time period is so that you avoid double counting. The longer you do it, the higher the risk the squirrels move around and you start double counting them.
That data I collected was quickly available to our statistician in Okala and he was able to run some models and say how many squirrels we thought there were in Central Park.
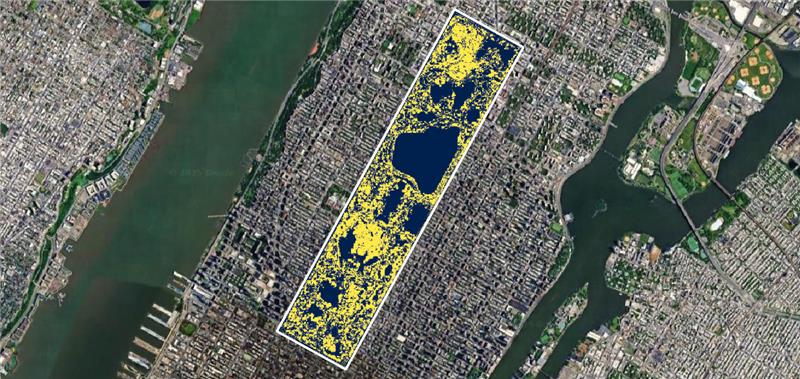 Whytock’s team at Okala was able to map the distribution of squirrels in the matter of a few hours. Image courtesy of Robin Whytock/Okala.
Whytock’s team at Okala was able to map the distribution of squirrels in the matter of a few hours. Image courtesy of Robin Whytock/Okala.
Mongabay: What did you find there? How did it compare to findings from the 2018 survey?
Robin Whytock: Distance sampling is a very well-known and used approach. I think in a lot of the conversations around biodiversity monitoring we want to use technology, but we forget some of the tried and tested things. We need to combine technology with those older approaches.
The reason I did it was to show that it’s completely possible to have a reasonable estimate of the squirrel population in Central Park without using 300 people. There are other reasons why you might want to engage 300 people. It is a fantastic thing because it engages people with nature. But the important question is: how do we measure biodiversity and how do we scale it up?
My point is that with the technology we have, like phone apps, camera traps and acoustics, and the statistical methods that we’ve been using for 30-plus years in the sector, it is completely scalable. If I can come up with an estimate of the squirrel population in a morning that’s in the ballpark of what was done by a hugely intensive survey with 300 people, let’s think of what’s possible in terms of the scalability.
In the 2018 squirrel census, they used the 300 volunteers and some modeling approaches, and they estimated 2,373 squirrels. From my morning of roughly 20 sampling points and about three and a half hours of walking, my estimate was 2,979. I only covered a fraction of the park. There’s a 25% difference there that can be attributed to differences in the methodology and perhaps changes in the squirrel population. If you want to really improve the estimates, I could do it over a few days or a week. Then that number would become more certain.
Mongabay: What did this experiment tell you about where we are with conservation technology?
Robin Whytock: There’s technology like mobile phone apps, acoustics, camera traps and AI. People think that alone is going to solve the problem.
But my point is that people, especially in the carbon and climate space, have lost sight of how we need to be able to deploy that technology, and then we tie it up with the old-school stats. Then we can come up with really solid numbers, and the whole thing is scalable. It’s not as challenging as people make it out to be.
Mongabay: How does the work you do at Okala tie into this?
Robin Whytock: We provide biodiversity monitoring solutions and we do that over four steps. We support private companies in the infrastructure, mining and forestry space. We help them figure out how to design a biodiversity monitoring program. We look at what technologies they can use and how they can be combined to successfully measure and monitor biodiversity.
Secondly, our company does fieldwork and deployment as well as training of local teams to be able to do this themselves. Thirdly, we use AI and other tools to help us analyze data, identify species and digitize the data into maps. We’ve got a biodiversity platform for that.
The last part is we then provide the scientific reporting. For example, how many squirrels do you have, or how many chimpanzees or leopards do you have?
We are trying to solve this data bottleneck in ecology. Because, to be honest, we often hear people say, “Oh no, we’ve got enough data. We’ve got too much data.” And for me, it’s not that you’ve got too much data. You often haven’t got the knowledge and the capacity to get information from that data. Having data is one thing, but turning that into information about the population, about the biodiversity as a whole, that’s often the part that’s missing. That’s what we really are trying to tackle.
The whole process is just letting us support people to do this really quickly and at scale. Camera traps have been around for years. But still people are struggling to get the data into a format that they can actually do the statistical modeling with and see how many leopards or chimpanzees there are. So many people are just stuck with it on their hard drive, and that’s a real data bottleneck. The platform is designed to try and tackle that across the board for all different data types.
 The team at Okala is attempting to scale up tech solutions to make biodiversity monitoring easier and more efficient. Picture above is the analysis of data collected from Gabon. Image courtesy of Robin Whytock/Okala.
The team at Okala is attempting to scale up tech solutions to make biodiversity monitoring easier and more efficient. Picture above is the analysis of data collected from Gabon. Image courtesy of Robin Whytock/Okala.
Mongabay: What gaps were you trying to fill when setting up Okala?
Robin Whytock: Sensors are now very inexpensive. Mobile phone apps can be used to collect data. The big challenge is people, from private sector to NGOs, they put all of their budget into the data collection and buying the sensors. They don’t think about how they’re going to analyze the data. They end up putting all this money into data that’s sitting on a hard disk that doesn’t become conservation insights.
Mongabay: Could you walk me through how you have trained the models to do this?
Robin Whytock: We’re taking advantage of models that have been built by some of the big names like Google. Google built SpeciesNet for camera traps that are available for commercial use. That has allowed us to have this global camera-trap AI model for our camera-trap projects.
We can now run it over massive data sets in the cloud, and then the platform allows us to actually go through and validate everything transparently. Google made this fantastic model that we could never compete with because we don’t have access to the training data and the expertise they have in their team. But what we have expertise in, as ecologists, is how to turn it into usable information and statistics. So that’s really how the AI models work for camera traps. It’s similar for bioacoustics as well. Google has made a global model with over 10,000 bird species in it, and we can apply that in the same way as we do with the camera-trap models.
Mongabay: How is it being used on the ground? Could you give me a few examples?
Robin Whytock: We worked with an international conservation NGO in the Republic of Congo. They had terabytes of data they had collected over three years. They had put in a large amount of money and resources to collect data from over 600 camera traps. But despite having an excellent team of scientists, they didn’t have the in-house expertise and time to get those terabytes of video data and turn it into the outputs that they need for their statistical modeling.
We helped them speed up the analysis process so that they could then use it for their grant reporting.
Another example would be in the mining sector. In Guinea, a customer had been trained by another consultancy on how to do camera trapping. They had done a very large-scale camera-trapping project to monitor the impact of mining activities on chimpanzee populations. They were struggling because they needed to report their findings to their investors. They had done a great job collecting the data, but getting information out of that data was their challenge. That’s where we were able to apply AI models, run the data through our platform, and then provide a statistical analysis to say how many chimpanzees there are.
Mongabay: What are some of the challenges you face in this work?
Robin Whytock: It’s really basic things, honestly. For example, sometimes we are struggling to find from people the GPS point of where they collected their data, and the date and the time they collected it. These three bits of information can honestly make or break the actual analysis part, and people often forget to do it in the field. It sounds so simple, but it’s still a problem, and I’d love to get that message that people should collect that basic data first.
Mongabay: How are you thinking about the future? What is the next step in Okala’s work?
Robin Whytock: We want to try and continue improving the science and the tech that will allow us to scale. I hope to bring this stuff outside of academia and actually into scalable solutions that allow people who don’t necessarily have Ph.D.’s to do all of this work.
There are still many problems and hurdles to overcome while using technology for conservation and biodiversity monitoring. There are lots of solutions, but making them actually scalable for, say, a government in Africa or a national park in Peru, is still often very challenging. So that’s what I want to try to continue to tackle.
Banner image: Eastern gray squirrel in New York City. Image © Julie Larsen.
Abhishyant Kidangoor is a staff writer at Mongabay. Find him on 𝕏 @AbhishyantPK.