

Tom’s Hardware Premium Roadmaps
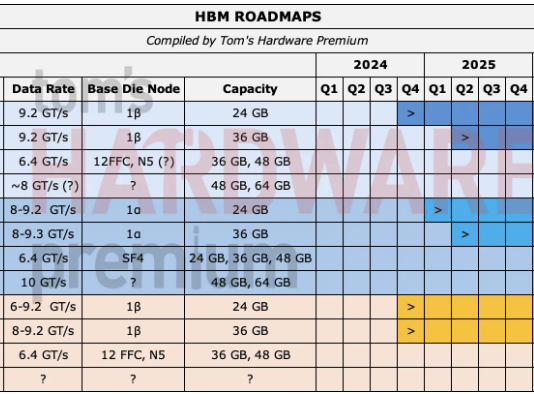
(Image credit: Future)
During a CES 2026 Q&A in Las Vegas, Nvidia CEO Jensen Huang was thrown a bit of a curveball. With SRAM-heavy accelerators, cheaper memory, and open weight AI models gaining traction, could Nvidia eventually ease its dependence on expensive HBM and the margins that come along with it?
Why SRAM looks attractive
Let’s take a step back for a moment and consider what Huang is getting at here. The industry, by and large, is actively searching for ways to make AI cheaper. SRAM accelerators, GDDR inference, and open weight models are all being pitched as pressure valves on Nvidia’s most expensive components, and Huang’s remarks are a reminder that while these ideas work in isolation, they collide with reality once they’re exposed to production-scale AI systems.
You may like
Huang did not dispute the performance advantages of SRAM-centric designs. In fact, he was explicit about their speed. “For some workloads, it could be insanely fast,” he said, noting that SRAM access avoids the latency penalties of even the fastest external memory. “SRAM’s a lot faster than going off to even HBM memories.”
This is why SRAM-heavy accelerators look so compelling in benchmarks and controlled demos. Designs that favor on-chip SRAM can deliver high throughput in constrained scenarios, but they run up against capacity limits in production AI workloads because SRAM cannot match the bandwidth-density balance provided by HBM, which is why most modern AI accelerators continue to pair compute with high-bandwidth DRAM packages.
But, Huang repeatedly returned to scale and variation as the breaking point. SRAM capacity simply does not grow fast enough to accommodate modern models once they leave the lab. Even within a single deployment, models can exceed on-chip memory as they add context length, routing logic, or additional modalities.
The moment a model spills beyond SRAM, the efficiency advantage collapses. At that point, the system either stalls or requires external memory, at which point the specialized design loses its edge. Huang’s argument was grounded in how production AI systems evolve after deployment. “If I keep everything on SRAM, then of course I don’t need HBM memory,” he said, adding that “…the problem is the size of my model that I can keep inside these SRAMs is like 100 times smaller.”

(Image credit: Tom’s Hardware)Workloads that refuse to stay still
Some of Huang’s more revealing comments came when he described how modern AI workloads behave in the wild. “Workloads are changing shape all the time,” he said. “Sometimes you have MOEs. (Mixture of Experts). Sometimes you have multimodality stuff. Sometimes you’ve got diffusion models. Sometimes you have autoregressive models. Sometimes you have SSMs. (Sequential Server Management)”
Each of those architectures stresses hardware differently. Some are memory-bound, while others push interconnect bandwidth. Some demand low latency, while others tolerate batching and delay. “These models are all slightly different in shape and size,” Huang summed it up bluntly. More importantly, those pressures shift dynamically. “Sometimes they move the pressure on the NVLink. Sometimes they move the pressure on HBM memory. Sometimes they move the pressure on all three,” he said.
This is the core argument supporting Nvidia’s case for flexibility. A platform optimized narrowly for one memory pattern or execution model risks leaving expensive silicon idle when the workload changes. In shared data centers, where utilization across weeks and months determines whether it’s economically viable, that is a serious liability.
You may like
“You might be able to take one particular workload and push it to the extreme,” Huang said. “But that 10% of the workload, or even 5% of the workload, if it’s not being used, then all of a sudden that part of the data center could have been used for something else.” In other words, Huang is arguing that peak efficiency on a single task matters less than consistent usefulness across many.
Open models still run into memory limits
(Image credit: Tom’s Hardware)
The original question also touched on open AI models and whether they might reduce Nvidia’s leverage over the AI stack. The suggestion was that open models, combined with SRAM-heavy designs and cheaper memory, could reduce reliance on Nvidia’s most expensive GPUs and improve margins across the stack.
While Huang has praised open models publicly and Nvidia has released its own open weights and datasets, his CES remarks made clear that openness does not eliminate infrastructure constraints. Training and serving competitive models still require enormous compute and memory resources, regardless of licensing. Open weights do not eliminate the need for large memory pools, fast interconnects, or flexible execution engines; they just change who owns the model.
This is important because many open models are evolving rapidly and, as they incorporate larger context windows, more experts, and multimodal inputs, their memory footprints will grow. Huang’s emphasis on flexibility applies here as well; supporting open models at scale does not reduce the importance of HBM or general-purpose GPUs. In many cases, it increases it.
The implication is that open source AI and alternative memory strategies are not existential threats to Nvidia’s platform. They are additional variables that increase workload diversity. That diversity, in Nvidia’s view, strengthens the case for hardware that can adapt rather than specialize.
Why Nvidia keeps choosing HBM

(Image credit: SK hynix)
Ultimately, Huang’s CES comments amount to a clear statement of priorities. Nvidia is willing to accept higher bill of materials costs, reliance on scarce HBM, and complex system designs because they preserve optionality. That optionality protects customers from being locked into a narrow performance envelope and protects Nvidia from sudden shifts in model architecture that could devalue a more rigid accelerator lineup.
This stance also helps explain why Nvidia is less aggressive than some rivals in pushing single-purpose inference chips or extreme SRAM-heavy designs. Those approaches can win benchmarks and attract attention, but they assume a level of workload predictability that the current AI ecosystem no longer offers.
Huang’s argument is not that specialized hardware has no place. Rather, it is that in shared data centers, flexibility remains the dominant economic factor. As long as AI research continues to explore new architectures and hybrid pipelines, that logic is unlikely to change.
For now, Huang seems confident that customers will continue to pay for that flexibility, even as they complain about the cost of HBM and the price of GPUs. His remarks suggest the company sees no contradiction there. That view may be challenged if AI models stabilize or fragment into predictable tiers, but, right now, Huang made it clear that Nvidia does not believe that moment has arrived yet.