

Note 1: This post is part 2 of a three-part series on healthcare, knowledge graphs, and lessons for other industries. Part 1, “What Is a Knowledge Graph — and Why It Matters” is available here.
Note 2: All images by author
In Part 1, we described how structured knowledge enabled healthcare’s progress. This article examines why healthcare, more than any other industry, was able to build that structure at scale.
Healthcare is the most mature industry in the use of knowledge graphs for a few fundamental reasons. At its core, medicine is grounded in empirical science (biology, chemistry, pharmacology) which makes it possible to establish a shared understanding of the types of things that exist, how they interact, and causality. In other words, healthcare lends itself naturally to ontology.
The industry also benefits from a deep culture of shared controlled vocabularies. Scientists and clinicians are natural librarians. By necessity, they meticulously list and categorize everything they can find, from genes to diseases. This emphasis on classification is reinforced by a commitment to empirical, reproducible observation, where data must be comparable across institutions, studies, and time.
Finally, there are structural forces that have accelerated maturity: strict regulation; strong pre-competitive collaboration; sustained public funding; and open data standards. All of these factors incentivize shared standards and reusable knowledge rather than isolated, proprietary models.
Together, these factors created the conditions for healthcare to build durable, shared semantic infrastructure—allowing knowledge to accumulate across institutions, generations, and technologies.
Ontologies
Humans have always tried to understand how the world works. When we observe and report the same thing repeatedly, and agree that it is true, we develop a shared understanding of reality. This process is formalized in science using the scientific method. Scientists develop a hypothesis, conduct an experiment, and evaluate the results empirically. In this way, humans have been developing an implicit medical ontology for thousands of years.
Otzi, the caveman discovered in 1991, who lived 5,300 years ago, was discovered with an antibacterial fungus in his leggings, likely to treat his whipworm infection (Kirsch and Ogas 4). Even cavemen had some understanding that plants could be used to treat ailments.
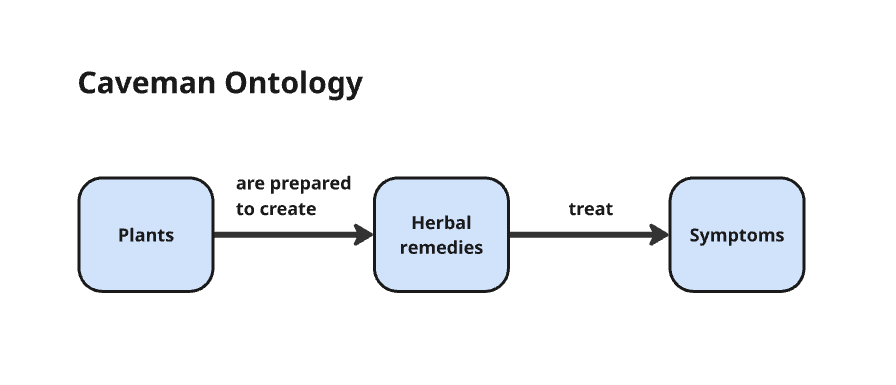
Eventually, scientists realized that it wasn’t the plant itself that was treating the ailment, but compounds inside the plant, and that they could mess with the molecular structure of these compounds in the lab and make them stronger or more effective. This was the beginning of organic chemistry and how Bayer invented Aspirin (by tweaking Willow bark) and Heroin (by tweaking opium from poppies) (Hager 75; Kirsch and Ogas 69). This added a new class to the ontology: compounds. With each new scientific breakthrough, our understanding of the natural world evolved, and we updated our ontology accordingly.
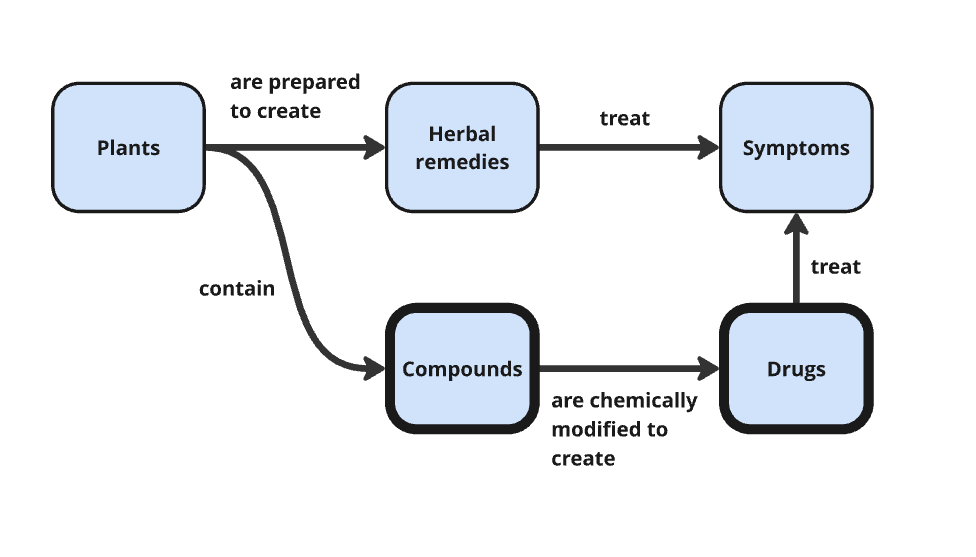
Over time, medicine developed a layered ontology, where each new class did not replace the previous one but extended it. The ontology grew to include pathogens after scientists Fritz Schaudinn and Erich Hoffmann discovered the underlying cause of syphilis was a bacterium called Treponema pallidum. We learned microbes could be found almost everywhere and some of them could kill bacteria, like penicillin, so microbes were added to our theory.
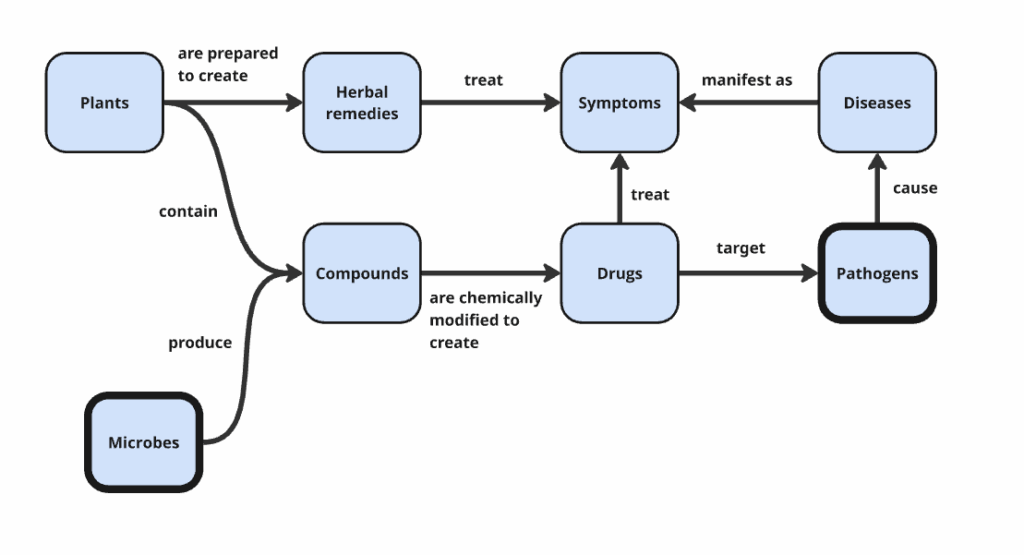
We learned that DNA contains genes, which encode proteins, which interact with biological processes and risk factors. Every major advance in medicine added new classes of things to our shared understanding of reality and forced us to reason about how those classes interact. Long before computers, healthcare had already built a layered ontology. Knowledge graphs did not introduce this way of thinking; they merely gave it a formal, computational substrate.
Today, we have ontologies for anatomy (Uberon), genes (Gene Ontology), chemical compounds (ChEBI) and hundreds of other domains. Repositories such as BioPortal and the OBO Foundry provide access to well over a thousand biomedical ontologies.
Controlled vocabularies
Once a class of things was defined, medicine immediately began naming and cataloging every instance it could find. Scientists are great at cataloging and defining instances of classes. De materia medica, the first pharmacopoeia, was completed in 70 CE. It was a book of about 600 plants and about 1000 medicines. When chemists began working with organic compounds in the lab, they created thousands of new molecules that needed to be cataloged. In response, the first volume of the Beilstein Handbook of Organic Chemistry was released in 1881. This handbook catalogued all known organic compounds, their reactions and properties, and grew to contain millions of entries.
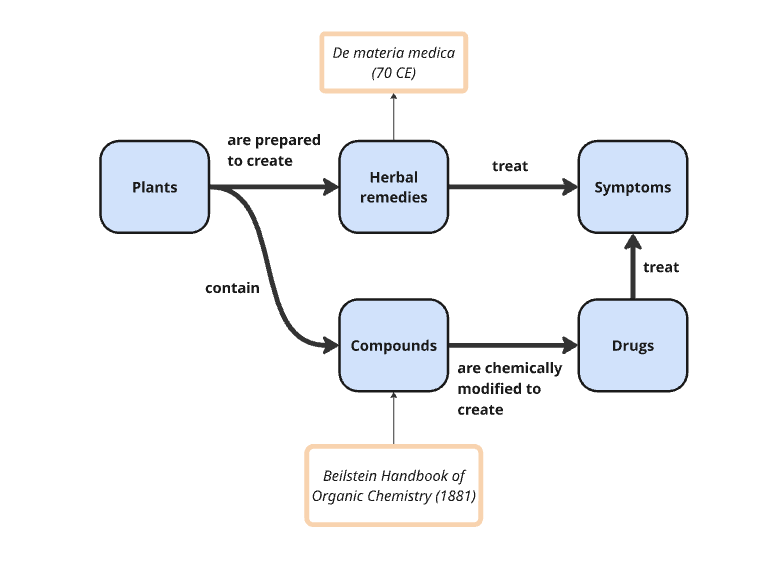
This pattern repeats throughout the history of medicine. Every time our understanding of the natural world improved, and a new class was added to the ontology, scientists began cataloging all of the instances of that class. Following Louis Pasteur’s finding in 1861 that germs cause disease, people began cataloging all the pathogens they could find. In 1923, the first version of Bergey’s Manual of Determinative Bacteriology was published, which contained about a thousand unique bacteria species.
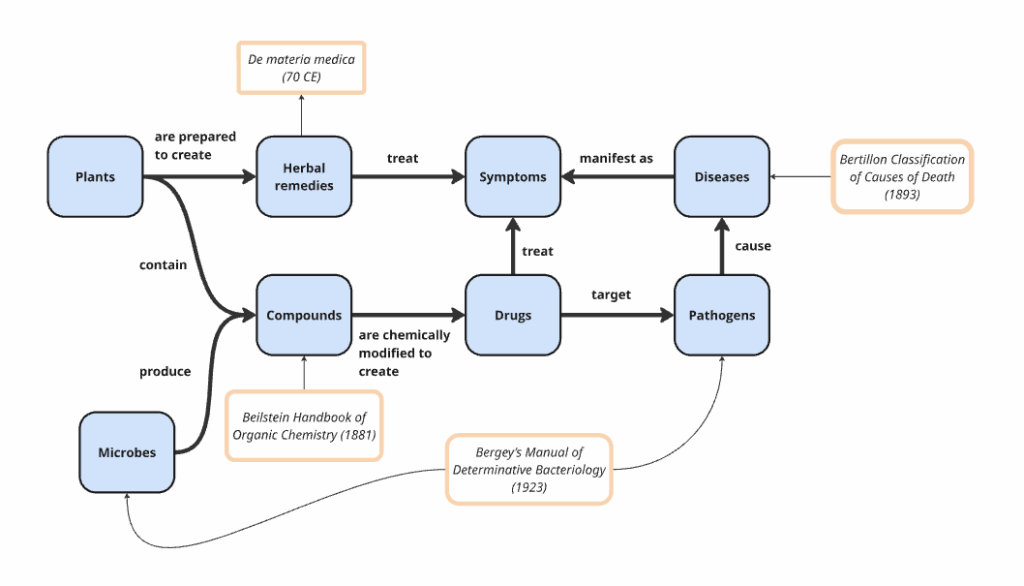
The same pattern repeated with the discovery of genes, proteins, risk factors, and adverse effects. Today, we have rich controlled vocabularies for conditions and procedures (SNOMED CT), diseases (ICD 11), adverse effects (MedDRA), drugs (RxNorm), compounds (CheBI and PubChem), proteins (UniProt), and genes (NCBI Gene). Most large pharma companies work with dozens of these third-party controlled vocabularies.
Somewhat confusingly, ontologies and controlled vocabularies are often blended in practice. Large controlled vocabularies frequently contain instances from multiple classes along with a lightweight semantic model (ontology) that relates them. SNOMED CT, for example, includes instances of diseases, symptoms, procedures, and clinical findings, as well as formally defined relationships such as has intent and due to. In doing so, it combines a controlled vocabulary with ontological structure, effectively functioning as a knowledge graph in its own right.
Regulations
Following a mass poisoning that killed 107 people due to an improperly prepared “elixir” in 1937, the US government gave the Food and Drug Administration (FDA) increased regulatory powers (Kirsch 97). The Federal Food, Drug, and Cosmetic Act of 1938 had requirements on how drugs should be labeled and required that drug manufacturers submit safety data and a statement of “intended use” to the FDA. This helped the US largely avoid the thalidomide tragedy in the late 1950s in Europe, where a tranquilizer was prescribed to pregnant women to treat anxiety, trouble sleeping, and morning sickness—despite not ever being tested on pregnant women. This caused the “largest anthropogenic medical disaster ever”, during which thousands of women suffered miscarriages and more than 10,000 babies were born with severe deformities.
While the US largely avoided this because of FDA reviewer caution, it also exposed gaps in the system. The Kekauver-Harris Amendments to the Federal Food, Drug, and Cosmetic Act in 1962 now required proof that drugs were both safe and effective. The increased strength of the FDA in 1938, and again in 1962, forced healthcare to standardize on the meaning of terms. Drug companies were forced to agree upon indications (what is the drug meant for), conditions (what does the drug treat), adverse effects (what other conditions have been associated with this drug) and clinical outcomes. Increased regulatory pressure also required replicable, well-controlled studies for all claims made about a drug. Regulation did not just demand safer drugs; it demanded shared meaning.
Observational data
These regulatory changes did not just affect approval processes; they fundamentally reshaped how medical observations were generated, structured, and compared. To make clinical evidence comparable, reviewable, and replicable, data standards for clinical trials became codified through organizations like the Clinical Data Interchange Standards Consortium (CDISC). CDISC defines how clinical observations, endpoints, and populations must be represented for regulatory review. Likewise, the FDA turned the shared terminologies cataloged in controlled vocabularies from best practice to mandatory.
Pre-competitive collaboration
One of the enabling factors that has led healthcare to dominate in knowledge graphs is pre-competitive collaboration. A lot of the work of healthcare is grounded in natural sciences like biology and chemistry that are treated as a public good. Companies still compete on products, but most consider a large portion of their research “pre-competitive.” Organizations like the Pistoia Alliance facilitate this collaboration by providing neutral forums to align on shared semantics and infrastructure (see data standards section below).
Public funding
Public funding has been essential to building healthcare’s knowledge infrastructure. Governments and public research institutions have invested heavily in the creation and maintenance of ontologies, controlled vocabularies, and large-scale observational data that no single company could afford building alone. Agencies such as the National Institutes of Health (NIH) fund many of these assets as public goods, leaving healthcare with a rich, open knowledge base ready to be connected and reasoned over using knowledge graphs.
Data standards
Healthcare also embraced open data standards early, ensuring shared knowledge could be represented and reused across systems and vendors. Standards from the World Wide Web Consortium (W3C) made medical knowledge machine-readable and interoperable, allowing semantic models to be shared independently of any single system or vendor. By anchoring meaning in open standards rather than proprietary schemas, healthcare enabled knowledge graphs to function as shared, long-lived infrastructure rather than isolated implementations. Standards ensured that meaning could survive system upgrades, vendor changes, and decades of technological churn.
Conclusion
None of these factors alone explains healthcare’s maturity; it is their interaction over decades—ontology shaping vocabularies, regulation enforcing evidence, funding sustaining shared infrastructure, and standards enabling reuse—that made knowledge graphs inevitable rather than optional. Long before modern AI, healthcare invested in agreeing on what things mean and how observations should be interpreted. In the final part of this series, we’ll explore why most other industries lack these conditions—and what they can realistically borrow from healthcare’s path.
About the author: Steve Hedden is the Head of Product Management at TopQuadrant, where he leads the strategy for EDG, a platform for knowledge graph and metadata management. His work focuses on bridging enterprise data governance and AI through ontologies, taxonomies, and semantic technologies. Steve writes and speaks regularly about knowledge graphs, and the evolving role of semantics in AI systems.
Bibliography
Hager, Thomas. Ten Drugs: How Plants, Powders, and Pills Have Shaped the History of Medicine. Harry N. Abrams, 2019.
Isaacson, Walter. The Code Breaker: Jennifer Doudna, Gene Editing, and the Future of the Human Race. Simon & Schuster, 2021.
Kirsch, Donald R., and Ogi Ogas. The Drug Hunters: The Improbable Quest to Discover New Medicines. Arcade, 2017.