


The new model, called VSSFlow, leverages a creative architecture to generate sounds and speech with a single unified system, with state-of-the-art results. Watch (and hear) some demos below.
The problem
Currently, most video-to-sound models (that is, models that are trained to generate sounds from silent videos) aren’t that great at generating speech. Likewise, most text-to-speech models fail at generating non-speech sounds, since they’re designed for a different purpose.
In addition, prior attempts to unify both tasks are often built around the assumption that joint training degrades performance, leading to setups that teach speech and sound in separate stages, adding complexity to the pipeline.
Given this scenario, three Apple researchers, alongside six researchers from Renmin University of China, developed VSSFlow, a new AI model that can generate both sound effects and speech from silent video in a single system.
Not only that, but the architecture they developed works in a way that speech training improves sound training, and vice versa, rather than interfering with one another.
The solution
In a nutshell, VSSFlow leverages multiple concepts of generative AI, including converting transcripts into phoneme sequences of tokens, and learning to reconstruct sound from noise with flow-matching, which we covered here, essentially training the model to efficiently start from random noise and end up with the desired signal.
All of that is embedded in a 10-layer architecture that blends the video and transcript signals directly into the audio generation process, allowing the model to handle both sound effects and speech within a single system.
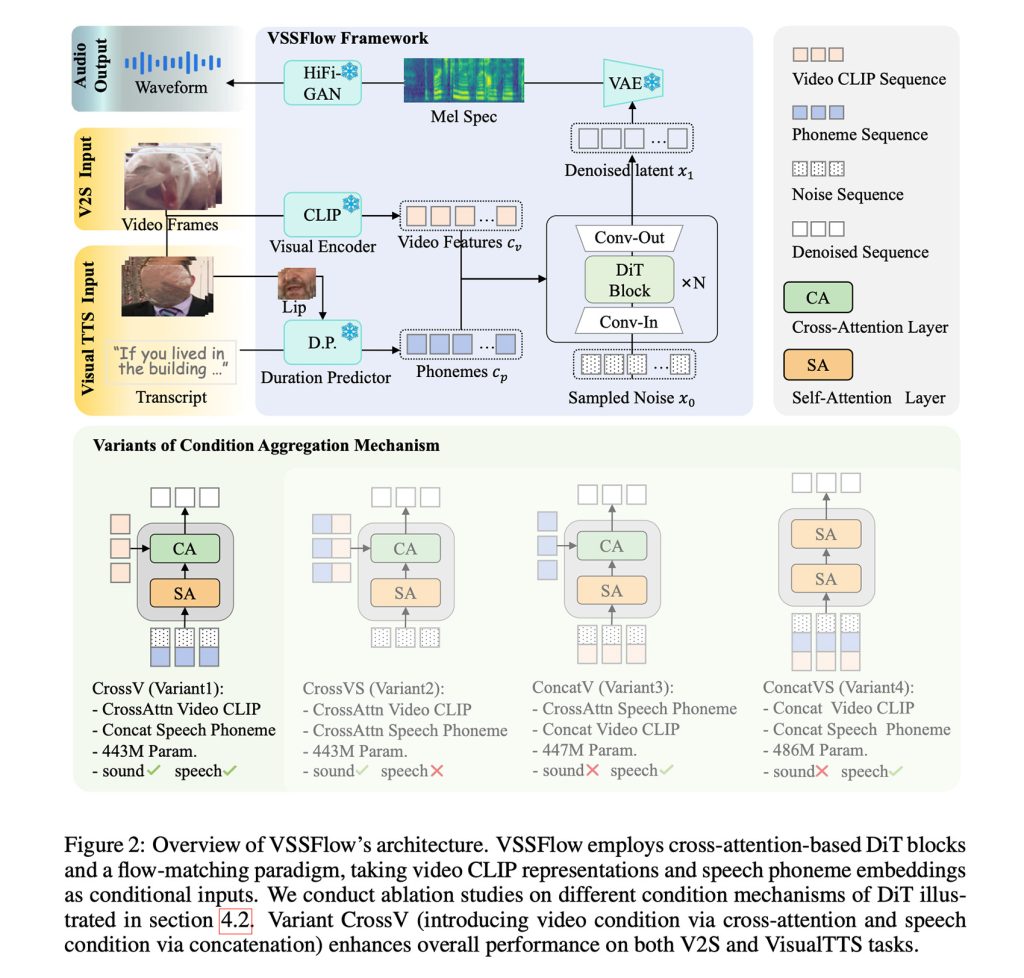
Perhaps more interestingly, the researchers note that jointly training on speech and sound actually improved performance on both tasks, rather than causing the two to compete or degrade the overall performance of either task.
To train VSSFlow, the researchers fed the model a mix of silent videos paired with environmental sounds (V2S), silent talking videos paired with transcripts (VisualTTS), and text-to-speech data (TTS), letting it learn both sound effects and spoken dialogue together in a single end-to-end training process.
Importantly, they noted that out of the box, VSSFlow wasn’t able to automatically generate background sound and spoken dialogue at the same time in a single output.
To achieve that, they fine-tuned their already-trained model on a large set of synthetic examples in which speech and environmental sounds were mixed together, so the model would learn what both should sound like simultaneously.
Putting VSSFlow to work
To generate sound and speech from a silent video, the model starts from random noise and uses visual cues sampled from the video at 10 frames per second to shape ambient sounds. At the same time, a transcript of what’s being said provides precise guidance for the generated voice.
When tested against task-specific models built only for sound effects or only for speech, VSSFlow delivered competitive results across both tasks, leading on several key metrics despite using a single unified system.
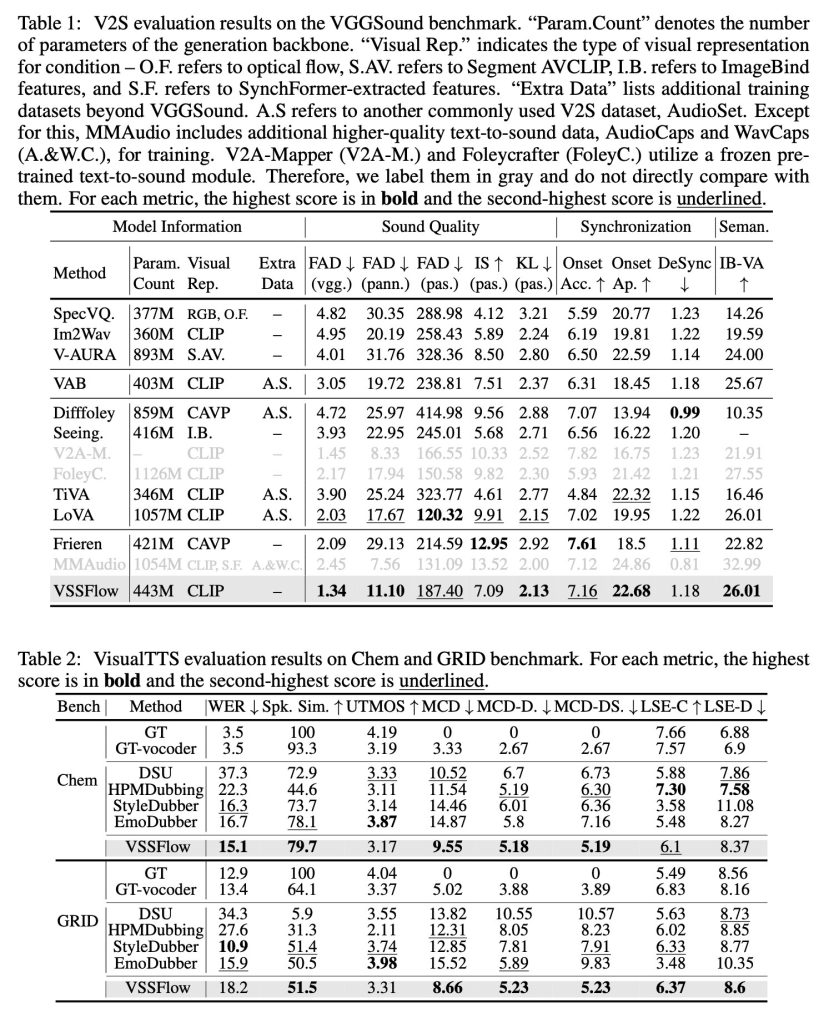
The researchers published multiple demos of sound, speech, and joint-generation (from Veo3 videos) results, as well as comparisons between VSSFlow and multiple alternative models. You can watch a few of the results below, but make sure to head over to the demos page to see them all.
And here is something really cool: the researchers open-sourced VSSFlow’s code on GitHub, and are working to open the model’s weights as well. Additionally, they are working on providing an inference demo.
As for what may come next, the researchers said:
This work presents a unified flow model integrating video-to-sound (V2S) and visual text-to-speech (VisualTTS) tasks, establishing a new paradigm for video-conditioned sound and speech generation. Our framework demonstrates an effective condition aggregation mechanism for incorporating speech and video conditions into the DiT architecture. Besides, we reveal a mutual boosting effect of sound-speech joint learning through analysis, highlighting the value of a unified generation model. For future research, there are several directions that merit further exploration. First, the scarcity of high-quality video-speech-sound data limits the development of unified generative models. Additionally, developing better representation methods for sound and speech, which can preserve speech details while maintaining compact dimensions, is a critical future challenge.
To learn more about the study, titled “VSSFlow: Unifying Video-conditioned Sound and Speech Generation via Joint Learning,” follow this link.
Accessory deals on Amazon
![]()
![]()
FTC: We use income earning auto affiliate links. More.