
Anthropic recently published a postmortem revealing that three distinct infrastructure bugs intermittently degraded the output quality of its Claude models in recent weeks. While the company states it has now resolved those issues and is modifying its internal processes to prevent similar disruptions, the community highlights the challenges of running the service across three hardware platforms.
In August and early September 2025, users of Anthropic’s Claude AI began reporting degraded or inconsistent responses. What initially appeared as normal performance variation turned out to be three distinct infrastructure bugs affecting Claude’s output quality. While none of these issues were caused by heavy load or demand, each bug emerged in the underlying infrastructure, routing logic, or compilation pipelines. The team explains:
We never reduce model quality due to demand, time of day, or server load. The problems our users reported were due to infrastructure bugs alone (…) Each bug produced different symptoms on different platforms at different rates. This created a confusing mix of reports that didn’t point to any single cause.
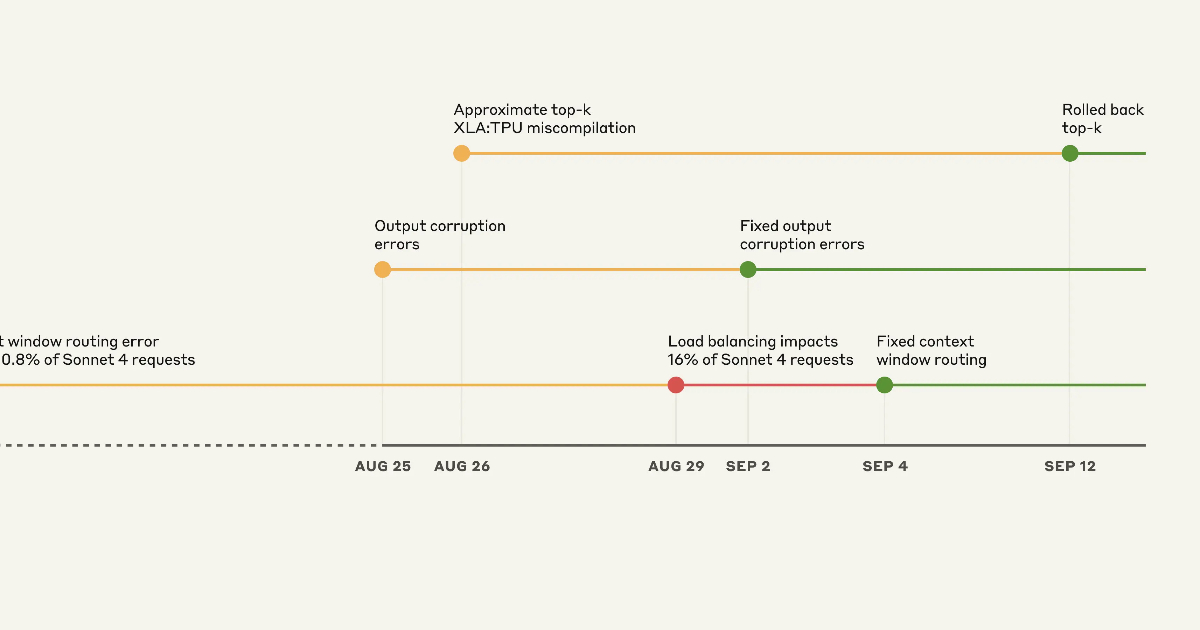
The team described the three overlapping issues: a context window routing error that, at the worst impacted hour on August 31, affected 16% of Sonnet 4 requests; an output corruption caused by a misconfiguration to the Claude API TPU servers that triggered an error during token generation, affecting requests made to Opus 4.1 and Opus 4 on August 25-28 and requests to Sonnet 4 from August 25 to September 2; and finally, an approximate top-k XLA:TPU miscompilation due to a latent bug in the compiler that affected requests to Claude Haiku 3.5 for almost two weeks. Anthropic adds:
We deploy Claude across multiple hardware platforms, namely AWS Trainium, NVIDIA GPUs, and Google TPUs. Each hardware platform has different characteristics and requires specific optimizations. Despite these variations, we have strict equivalence standards for model implementations.

Source: Anthropic blog
Todd Underwood, head of reliability at Anthropic, acknowledges the issues on LinkedIn:
It’s been a rough summer for us, reliability wise. Prior to this set of issues we had previously had capacity and reliability problems throughout much of July and August (…) I’m very sorry for the problems and we’re working hard to bring you the best models at the highest level of quality and availability we can.
Clive Chan, member of technical staff at competing OpenAI, comments:
ML infra is really hard. great job to everyone who worked on the debug and writeup.
As Anthropic’s goal is for different hardware platforms to be transparent to end users and for all users to receive the same quality responses regardless of which platform serves their request, the hardware complexity means that any infrastructure change requires validation across all platforms and configurations. Philipp Schmid, senior AI developer relations engineer at Google DeepMind, writes:
Serving a model at scale is hard. Serving it across three hardware platforms (AWS Trainium, NVIDIA GPUs, Google TPUs) while maintaining strict equivalence is a whole other level. Makes you wonder if the hardware flexibility is truly worth the hit to development speed and customer experience for them.
On Hacker News, Mike Hearn comments:
The most interesting thing about this is the apparent absence of unit tests. The test for the XLA compiler bug just prints the outputs, it’s more like a repro case than a unit test in the sense that it’d be run by a test harness and have coverage tracked. And the action items are simply to lean more aggressively into evals.
Going forward, the artificial intelligence company promises to introduce more sensitive evaluations, add quality evaluations in more places, and develop infrastructure and tooling to better debug community-sourced feedback without sacrificing user privacy.