

Introduction
Alzheimer disease (AD) is a neurodegenerative condition involving an insidious decline of semantic and episodic memory alongside other functions []. Its current prevalence, of 55 million, will likely triple by 2050, with cases increasing by 116% in high-income countries and 250% in low- or middle-income countries [-]. This underscores the need for noninvasive, scalable markers that facilitate disease detection and monitoring []. Automated speech and language analysis (ASLA) meets these requisites [-].
In ASLA studies, patients and healthy controls (HCs) are simply required to speak, be it through spontaneous (eg, memory description), semispontaneous (eg, picture description), or nonspontaneous (eg, paragraph reading) tasks []. Thereupon, their recordings and transcripts can be digitally analyzed to identify disease-sensitive features [,]. This approach has been leveraged to detect early-stage cases [,,], support differential diagnosis [], predict dementia onset [], and capture cognitive decline [] and brain atrophy patterns [,]. As ASLA also reduces testing time and costs, it represents a promising framework to foster global equity in dementia assessments []. However, such potential remains unmet, as most studies target features with low interpretability and tests of between-language generalizability are incipient [,]. This casts doubts on the approach’s clinical utility and cross-linguistic validity.
Interpretability is often undermined by 2 analytical strategies. One involves targeting heterogeneous feature sets that mix domains known to be affected (eg, semantics) and often spared (eg, morphosyntax) in AD [,,]. The other relies on black-box models (eg, transformers) operating on hidden layers without clinical significance—eg, deep learning models such as BERT (Bidirectional Encoder Representations from Transformers) or Wav2vec (Meta), which produce high-dimensional representations that do not correspond to well-defined linguistic or acoustic constructs [,]. Both strategies yield variable outcomes that cannot be readily integrated with core clinical knowledge about AD, reducing the framework’s translational potential.
Moreover, over 40% of ASLA research on AD targets English speakers []. This is highly inequitable, as English is spoken by less than 20% of the world’s population [] and AD is most prevalent in non-Anglophone countries [-]. Importantly, several language domains can be affected by this disease in English speakers and spared in users of other languages []. Thus, not all ASLA results from English-speaking cohorts may generalize well to other language groups.
Promisingly, recent developments allow the circumvention of both issues. Robust, interpretable results have been obtained in ASLA studies targeting (1) speech timing features (eg, pause duration) as proxies of lexical search effort [-]; and (2) lexico-semantic features, including word class features (proportion of different lexical categories) [-], semantic granularity (conceptual precision when naming entities) [,], and semantic variability (conceptual distance across successive words) []. Such features can reveal distinct processing demands and strategies in AD, potentially yielding maximal results when combined than when framed in isolation [,].
Also, these features can be tested for cross-cultural validity by training classifiers with data from English-speaking participants and testing them on users of a different language, as recently proposed [] and preliminarily attempted in promising studies and challenges [-]. In particular, a 0-shot approach, involving no cross-linguistic calibration or transfer, creates highly stringent, unbiased conditions for this examination. Conceivably, cross-linguistic generalizability could be higher for speech timing features (as word retrieval effort should increase in AD irrespective of the language) than for lexico-semantic features (which vary widely between English and other languages) [,]. As proposed elsewhere, such features are interpretable because they reflect dysfunctions of semantic memory, a core system affected in early disease stages. This allows results to be understood in relation to well-established neuropsychological models of AD [,].
Against this background, we examined whether interpretable ASLA features yield cross-linguistic AD markers. Using speech timing and lexico-semantic features from a validated task [,,], we first trained classifiers with English-speaking patients and HCs, and then tested them in a within-language and a between-language setting (with English and Spanish speakers as testing folds, respectively). In each case, we ran separate classifiers for timing features, lexico-semantic features, and their combination. Finally, we explored whether the most sensitive features in each setting could predict patients’ cognitive decline, indexed through the Mini-Mental State Examination (MMSE) []. Relative to current literature [-], our approach is unique in its integration of clinically motivated acoustic and linguistic features with unimodal and fusion-based classifiers for 0-shot within- and between-language classification and severity prediction. Adding novelty, our design involves Latino individuals, a large, underserved population with a high prevalence of AD [,].
For the within-language setting, we hypothesized that interpretable features would enable patient identification in both modalities, with the best outcomes resulting from their combination. For the between-language setting, we anticipated better cross-linguistic generalization for timing than for lexico-semantic features. Finally, considering recent findings [,], we anticipated that the most discriminatory features in each setting would reliably predict patients’ MMSE scores. By testing these hypotheses, we seek to further ASLA research on AD with a translational, cross-cultural ethos.
MethodsStudy Design
Our study involved an opportunistic design. Preregistration was not feasible as the protocols’ stimuli, prompts, speech recording settings, and accompanying measures were established before the present investigation was conceived. Still, the analysis plan was established in the National Institutes of Health–approved project R01AG075775 (aim 1c), led by the corresponding author. Moreover, the current study extends and refines a previously reported analytical strategy [], focused on embeddings as opposed to interpretable features. The current study’s methods are diagrammed in .
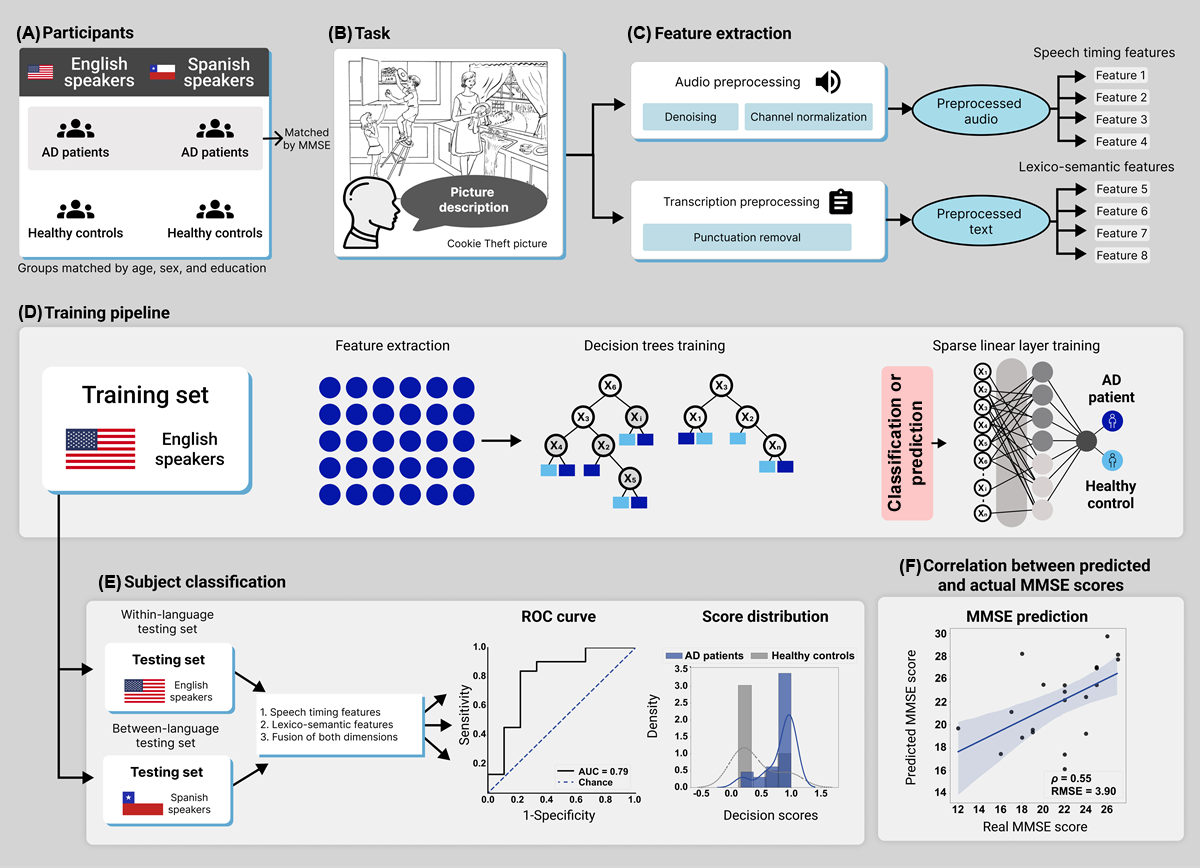 Figure 1. Study design. (A) This study involved English- and Spanish-speaking patients with AD and HCs, matched for sociodemographic variables (with patient groups also matched for MMSE scores). (B) Participants were recorded as they described the Cookie Theft picture. (C) Audios and transcripts were preprocessed with standard procedures before the extraction of speech timing and lexico-semantic features. (D) A machine learning classifier was trained with data from English-speaking patients with AD and HCs through a pipeline with decision trees and sparse linear models. (E) Classification performance was assessed in a within-language setting (with English-speaking patients and HCs) and in a between-language setting (with Spanish-speaking patients and HCs), considering 1=speech timing features, 2=lexico-semantic features, and 3=their combination via early fusion. The results were visualized via ROC curves and score distribution plots. (F) We computed correlations between the patients’ actual MMSE scores and those predicted by each feature set. AD: Alzheimer disease; AUC: area under the curve; HC: healthy control; MMSE: Mini-Mental State Examination; RMSE: root-mean-squared error; ROC: receiver operating characteristic. Participants
Figure 1. Study design. (A) This study involved English- and Spanish-speaking patients with AD and HCs, matched for sociodemographic variables (with patient groups also matched for MMSE scores). (B) Participants were recorded as they described the Cookie Theft picture. (C) Audios and transcripts were preprocessed with standard procedures before the extraction of speech timing and lexico-semantic features. (D) A machine learning classifier was trained with data from English-speaking patients with AD and HCs through a pipeline with decision trees and sparse linear models. (E) Classification performance was assessed in a within-language setting (with English-speaking patients and HCs) and in a between-language setting (with Spanish-speaking patients and HCs), considering 1=speech timing features, 2=lexico-semantic features, and 3=their combination via early fusion. The results were visualized via ROC curves and score distribution plots. (F) We computed correlations between the patients’ actual MMSE scores and those predicted by each feature set. AD: Alzheimer disease; AUC: area under the curve; HC: healthy control; MMSE: Mini-Mental State Examination; RMSE: root-mean-squared error; ROC: receiver operating characteristic. Participants
This study used a cross-sectional design based on a convenience sample. The initial datasets comprised 242 native English speakers for the English dataset and 198 native Spanish speakers for the Spanish dataset. Native English speaker data came from the Pitt corpus [], a widely used resource in ASLA research on AD [], enabling global challenges such as Alzheimer’s Dementia Recognition Through Spontaneous Speech and its variations []. Native Spanish speakers belonged to a Chilean cohort at the Hospital del Salvador’s Memory and Neuropsychiatry Clinic [,]. Fifty-six participants were removed due to faulty recordings or incomplete metadata. Participants from both datasets were selected using custom-made Python code to ensure demographic similarity for subsequent analyses (A), leading to the removal of an additional 173 participants. The final sample involved 211 participants across both datasets, all without any missing data. The English-language dataset (n=117), for the within-language setting, included 58 patients with AD and 59 HCs. The Spanish-language dataset (n=94), for the between-language setting, encompassed 47 patients with AD and 47 HCs [].
All English-speaking participants completed a comprehensive neuropsychiatric evaluation, a semistructured psychiatric interview, and a neuropsychological assessment [,]. As the Pitt corpus’s protocol began before the establishment of NINCDS-ADRDA (National Institute of Neurological and Communicative Disorders and Stroke and the Alzheimer’s Disease and Related Disorders Association) [] and DSM (Diagnostic and Statistical Manual of Mental Disorders) [] criteria, inclusion in the patient group was determined by frank evidence of progressive cognitive and functional decline alongside abnormal MMSE scores (sample’s mean 19.98, SD 4.79). Use of this dataset was strategic to (1) enable direct comparisons between our results and literature benchmarks while (2) guaranteeing that the same task was used in both languages. With regards to the Spanish-language dataset, AD diagnoses were made by expert neurologists following updated, validated procedures based on NINCDS-ADRDA criteria [,]. Outcomes on the MMSE [] revealed abnormal cognitive scores (mean 22.11, SD 3.87) []. The HC group in both datasets consisted of cognitively preserved, functionally independent individuals. No participant had a history of (other) neurological disorders, psychiatric conditions, primary language deficits, or substance abuse, and all of them had normal or corrected-to-normal vision and hearing.
All 4 groups were matched for sex, age, and years of education, and dialect was consistent across participants in each language group (). MMSE scores were not matched between English- and Spanish-speaking patients with AD as dementia cutoffs differ between such populations []. Clinical and cognitive measures for the English and the Spanish datasets were administered following formal procedures of the University of Pittsburgh School of Medicine and harmonized protocols of the Multi-Partner Consortium to Expand Dementia Research in Latin America, respectively. The feasibility and acceptability of the Spanish data overall protocol are verified by its continuous successful application in multiple studies and populations [,,,-] (see below for details). Participants provided written informed consent under the Declaration of Helsinki. The current study was approved by the institutional ethics committee.
Table 1. Participants’ demographic and neuropsychological profiles.
English speakersSpanish speakersStatisticsPairwise comparisons
Patient with ADa (N=58)Healthy controls (N=59)Patients with AD (N=47)Healthy controls (N=47)ValueP valueGroupsEstimateP valueDemographic data
Sex (female:male)35:2336:2324:2333:14χ2=3.62.31bN/AcN/AN/A
Age, mean (SD)65.21 (6.90)66.12 (7.08)70.19 (6.93)64.32 (17.48)F=5.68.02d
ENe AD vs EN HCsf–0.48.97g
ES AD vs ESh HCs2.78.06g
EN AD vs ES AD–2.47.11g
EN HCs vs ES HCs0.90.85g
Years of education, mean (SD)13.79 (2.32)13.46 (2.01)13.31 (4.42)14.53 (3.96)F=3.02.10dN/AN/AN/ANeuropsychological data
MMSEi, mean (SD)19.98 (4.79)N/A22.11 (3.87)N/AN/AN/AEN AD vs ES AD–3.15.02f
aAD: Alzheimer disease.
bP values calculated via the chi-squared test.
cN/A: not applicable.
dP values calculated via independent measures ANOVA, with results showing the interaction between condition (patients and controls) and language (English and Spanish).
eEN: English.
fHC: healthy control.
gP values for pairwise comparisons of significant interaction effects were calculated via independent measures ANOVA with Scheffé correction; crucially, no pairwise comparison was significant despite the significant interaction for age.
hES: Spanish.
iMMSE: Mini-Mental State Examination.
Experimental Task
Speech was elicited through the Cookie Theft picture task (B) from the Boston Diagnostic Aphasia Examination [], as described in previous reports of both datasets [,,,,,,,]. The stimulus is a black-and-white drawing of a mother and her 2 children performing several actions in a kitchen. Participants were asked to view the scene and describe its events and elements in as much detail as possible, in whichever order they preferred. No time limit was imposed. Examiners intervened only if participants needed assistance or stopped talking without mentioning central details. Importantly, this picture has proven useful in capturing speech and language abnormalities in English-speaking [,] and Spanish-speaking [,,] cohorts.
The English recordings were captured in .mp3 format at a sample rate of 44,100 Hz and 16-bit resolution, following a comprehensive protocol overseen by the Alzheimer and Related Dementias Study at the University of Pittsburgh School of Medicine []. The Spanish recordings were obtained in a quiet environment using laptop computers fitted with noise-canceling microphones []. These recordings were captured in .wav format at a sample rate of 44,100 Hz and 16-bit resolution, all managed through Cool Edit Pro 2.0.
Data Preprocessing and Feature ExtractionOverview
Audio recordings and their transcripts were preprocessed and subjected to validated feature extraction procedures, as detailed below (C).
Audio Preprocessing and Extraction of Speech Timing Features
Recordings were preprocessed following a validated pipeline []. Segments including the examiner’s voice were manually removed from the English and the Spanish recordings. The participants’ speech signals were converted to .wav format and then resampled at a rate of 16 kHz through SoX (Sound Exchange) []. The output was then denoised using a recurrent neural network model with complex linear coding [], and manual inspection confirmed the absence of speech artifacts. Microphone-related biases were eliminated via channel and mean cepstral normalization [].
Speech timing features were extracted at the whole-recording and the single-word level ( and ). Whole-recording features were calculated for the following variables: pause ratio, duration ratio, speech segment ratio, speech segment duration ratio, and voice ratio. Duration information was derived from an energy-based voice activity detection (VAD) algorithm to detect the presence of human speech and differentiate it from silence segments (indicating pauses), following these steps: (1) denoising using a recurrent neural network filter [], (2) amplitude normalization, (3) VAD, and (4) segmentation and feature extraction. This pipeline follows validated procedures reported in prior literature []. To this end, the log energy is calculated on 25-ms windows with a 10-ms hop size, the DC (mean value of a signal) level of the energy is subtracted, and the signal is then smoothed by convolving it with a Gaussian window of 10-ms []. Speech segments were detected by identifying frames with log-energy levels above a heuristically defined (yet systematic) threshold by analyzing the average signal energy in silent and speech-labeled segments. In contrast, pauses were determined by frames with log-energy levels below the threshold []. To calculate voice rate, we identified voice segments as those whose fundamental frequency differed from 0 [] and computed the number of voiced segments per second. We note that the primary features used in our analysis are timing-based (eg, pause duration and speech rate), which are minimally affected by MP3 compression artifacts []. Indeed, MP3 compression on suprasegmental acoustic measures (eg, fundamental frequency, pitch range, and level) shows minimal measurement errors, typically below 2%, on compression bitrates in the 56-320 kbps range []. Although spectral distortions introduced by compression may influence certain acoustic features, our preprocessing pipeline includes noise-reduction and normalization steps that help mitigate these effects []. Importantly, denoising and energy-based pause detection improve performance metrics such as word error rate and character error rate [], indicating that such preprocessing enhances reliability without artificially distorting pause-related features. Word-level features consisted of (normalized) word duration and (normalized) word count. Audio segments and their corresponding transcription units were time-aligned [] as in previous works [,]. The single-word features were computed taking into account (1) syllables, (2) all words, (3) stop words, and (4) content words separately, as well as (5) all possible combinations thereof.
Table 2. List of speech timing features.Whole-recording levelSingle-word levelPause duration ratioN/AaSpeech segment duration ratioWord durationPause ratioNormalized word durationPause durationWord countSpeech segment durationNormalized word countVoiced rateN/A
aN/A: not applicable.
Table 3. List of vocabulary selection features.Word-class featuresSemantic featuresNoun ratioN/AaVerb ratioGranularityAdjective ratioSemantic variabilityAdverb ratioN/A
aN/A: not applicable.
All whole-recording and word-level features were expressed in seconds, and when possible, represented in terms of 6 statistical values (mean, SD, skewness, kurtosis, minimum value, and maximal value), as in previous research [].
Transcript Preprocessing and Extraction of Vocabulary Selection Features
We used previously reported transcriptions from both datasets. English recordings were transcribed using CHAT (Codes for the Human Analysis of Transcripts), a standardized system developed by the CHILDES (Child Language Data Exchange System) project [] for transcribing and analyzing spoken language data. It uses structured tiers to represent participant information, transcribed speech, translations, and annotations. Special characters used by this procedure (eg, ?, –, (), +) were automatically removed from each text. Spanish recordings were transcribed via an automatic speech-to-text service [] and manually revised. The rare occurrences of unintelligible words were discarded. In all cases, examiners’ interventions were removed (including the silent segment following each intervention). Transcriptions were analyzed regarding word-class and semantic features.
First, word-class features were calculated as the ratio of each content word type: nouns, verbs, adjectives, and adverbs—namely, words which, unlike functional categories, involve representational content and thus tap on core conceptual processes affected by AD []. We calculated these proportions relative to the text’s overall word count and the number of content words only. Second, we calculated 2 types of semantic features. We used the Natural Language Toolkit library in Python to estimate each word’s granularity using WordNet, a hierarchical graph whose nodes branch out from the highest hypernym entity to more specific concepts (such as animal, dog, and bulldog, in increasing order of granularity). Granularity is calculated as the smaller number of nodes between a word and the root node entity. For instance, words in bin-3 are closer to the “entity” than those in bin-10, indicating that the former refers to more general concepts []. We extracted distributional statistics and the proportion of words with low, intermediate, and high granularity over the total number of words. Third, in line with reported procedures [], semantic variability was established across: (1) content words, (2) not-repeated adjacent words, and (3) not-repeated adjacent content words. We allocated individual words to vectors within the vocabulary through the fastText (Meta) model [], pretrained with an extensive corpus. Specific pretrained monolingual models were used for each language (cc.en.300.bin for English and cc.es.300.bin for Spanish), both downloaded from the official fastText website. These were trained separately on each language’s Common Crawl and Wikipedia corpora under an identical configuration (Continuous Bag of Words) with position-weights, 300 dimensions, character n-grams (length 5), window size 5, and 10 negatives. Distances between adjacent vectors were stored in a time series. Semantic consistency was determined by calculating the variance of this combined time series. A higher value in semantic consistency is observed in texts where consecutive words represent distant concepts. As in previous NLP research [], variables were analyzed whenever feasible, considering their mean, SD, skewness, kurtosis, minimum value, and maximal value.
Data Analysis
Within- and between-language analyses were performed following identical steps (D). The within-language analysis used 80% of participants from each group for model training, and the remaining 20% were set aside as a hold-out sample for testing. The between-language analysis used the same training model as the English-language experiment and used the entire Spanish-speaking sample for testing. In all cases, we considered three classification scenarios based on (1) acoustic features only, (2) linguistic features only, and (3) both types of features combined via early fusion (E). We trained the model with dedicated speaker-independent training and test splits to ensure robustness. Note that the Spanish-speaking cohort was used exclusively as an independent testing set.
We used a modified algorithm that combines decision trees with a partially connected, sparse multilayer perceptron (MLP) network [,]. This network’s structure is based on information from a group of decision trees trained to discriminate AD. It is not constructed with a fully connected layer; the interconnections are guided by the decision tree classifier preceding the MLP. Each neuron specializes in processing a specific tree, taking input from features generated by the decision tree. Importantly, the MLP’s decision tree component improves interpretability, which is important for clinical relevance, and its sparsely connected nature results in fewer parameters, reducing the risk of overfitting. Feature importance is assessed by counting the neurons connected to a specific feature (the more connections, the greater the importance).
The models underwent a bootstrapping strategy, with an 80/20 split. Features were normalized as z-scores relative to the train set parameters. To reduce the risk of overfitting, several strategies were implemented during model training []. Ridge regularization [] was applied to penalize large weight magnitudes, encouraging simpler models that generalize better to unseen data. Early stopping [] was used with a patience of 10 epochs, halting training when validation performance ceased to improve and preventing the model from overadapting to the training data. Within each feature set (speech timing, linguistic, and fusion), we report the best-performing combination of trees ∈ {10,20,40,60,80,100} and depth ∈ {4,6,8,10} (“depth” refers to the number of levels or splits in a single decision tree, indicating its complexity, while “number of trees” refers to the quantity of decision trees used in an ensemble model, such as a random forest or XGBoost [Extreme Gradient Boosting]) across both settings (within-language and between-language), based on the area under the receiver operating characteristic curve (AUC) values. Given the class imbalance problem, we used weighting techniques to assign a higher penalty to misclassification of the minority class, thus adjusting the cross-entropy loss within the neural network []. Details about hyperparameter tuning are offered in (Sections S3 and S4). The corresponding code implementations are available on GitHub []. Pairwise DeLong tests were conducted to assess whether AUC differences across models were statistically meaningful.
Additionally, we examined whether speech timing and linguistic features in each language were predictive of patients’ MMSE scores (F). We report the best correlation across both languages in each case based on the Spearman correlation coefficient (ρ) and the root-mean-squared error (RMSE). This approach indicates how close the predicted values are to the true values on average.
Ethical Considerations
Data collection procedures of the English dataset (from the publicly available Pitt Corpus) were approved by the Institutional Review Board of the University of Pittsburgh. Participants provided informed consent in accordance with the protocols established by the Alzheimer and Related Dementias Study at the University of Pittsburgh School of Medicine. Data from the Chilean cohort were collected with approval from the Ethics Committee of the Servicio de Salud Metropolitano Oriente, Santiago (project code: ANID-Fondap 15150012). All participants provided written informed consent under the 1964 Declaration of Helsinki. The Spanish dataset’s ethical approval allowed for data to be integrated with international datasets for projects involving the principal investigators (note that these data were analyzed by our local research team rather than shared with external collaborators). The English dataset is open for cross-national analyses, as shown in previous papers and challenges [,,]. Both datasets were deidentified via the removal of personal information (names, occupations, and geographical locations). Data shared in our repository was limited to deidentified feature sets; there being no raw audio recordings (in particular, the speech timing features we targeted cannot be leveraged to infer a speaker’s identity). Importantly, the picture description task we used elicits no self-referential information, as verified manually in each of the transcriptions. Additionally, we ensured harmonization of ethical oversight across both sites by aligning our procedures with international best practices for secondary use of sensitive speech data. Privacy and data protection were guaranteed by (1) robust deidentification, (2) restricting analyses to derived features that cannot be reverse-engineered into intelligible speech or personal identity, and (3) refraining from sharing raw audio between sites. These safeguards are consistent with concerns highlighted in the speech technology and legal communities regarding General Data Protection Regulation compliance and privacy protection []. Accordingly, ethical clearance covered the full scope of our cross-linguistic analyses and ensured compliance with data governance requirements at both sites. No compensation was offered or given to participants.
ResultsWithin-Language Results
As shown in , within-language (English-to-English) analyses revealed similar classification based on timing features from all words and stop words (AUC=0.79, A) and based on lexico-semantic features (AUC=0.80, B). The fusion of both dimensions yielded maximal discrimination (AUC=0.88, C). The outcomes of these 3 classifiers did not differ significantly (speech timing vs lexico-semantic features: P=.96; lexico-semantic features vs fusion: P=.55; speech timing vs fusion: P=.52). Further, the MMSE scores of English-speaking patients correlated significantly with those predicted by within-language regressions based on speech timing features (ρ=0.430, P<.001, RMSE=5.620), but not with those based on lexico-semantic features (ρ=0.271, P=.39, RMSE=7.898) or the combination of both feature sets (ρ=0.088, P=.79, RMSE=6.257).
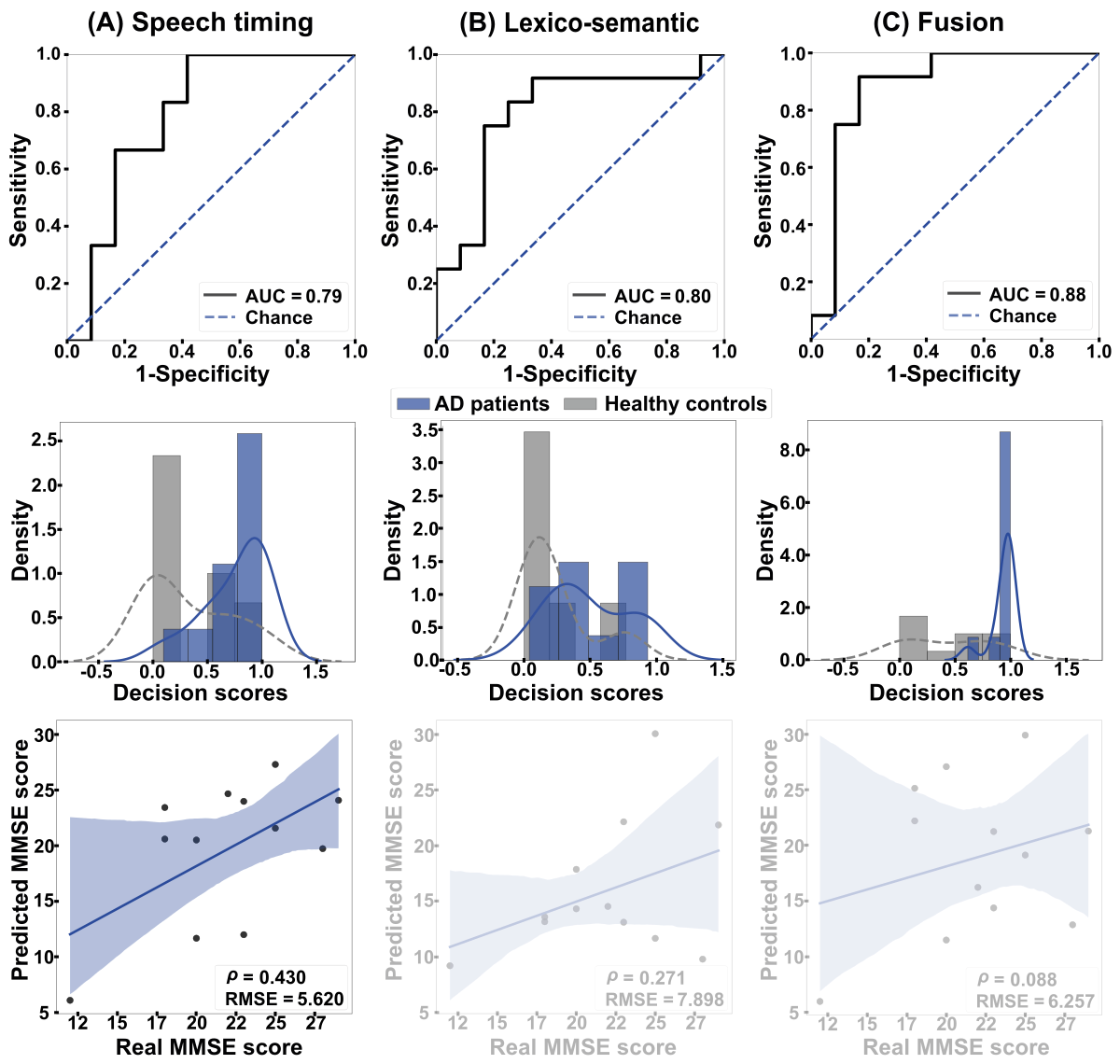 Figure 2. Within-language results. The ROC curves (top row) and the classification scores (middle row) show outcomes for classifying AD patients and HCs in the English-to-English setting. (A) Discrimination was good when based on speech timing and (B) lexico-semantic features alone, and (C) excellent when combining both modalities via early fusion. The bottom row shows correlations between actual and predicted MMSE scores. Associations were significant and moderately strong for all 3 feature sets. AD: Alzheimer disease; AUC: area under the curve; HC: healthy control; MMSE: Mini-Mental State Examination; RMSE: root mean squared error; ROC: receiver operating characteristic curve. Between-Language Results
Figure 2. Within-language results. The ROC curves (top row) and the classification scores (middle row) show outcomes for classifying AD patients and HCs in the English-to-English setting. (A) Discrimination was good when based on speech timing and (B) lexico-semantic features alone, and (C) excellent when combining both modalities via early fusion. The bottom row shows correlations between actual and predicted MMSE scores. Associations were significant and moderately strong for all 3 feature sets. AD: Alzheimer disease; AUC: area under the curve; HC: healthy control; MMSE: Mini-Mental State Examination; RMSE: root mean squared error; ROC: receiver operating characteristic curve. Between-Language Results
Between-language (English-to-Spanish) analyses () yielded maximal discrimination for the speech timing classifier, based on stop words (AUC=0.75, A). Lower outcomes were obtained for lexico-semantic features, considering semantic information (AUC=0.64, B), and the fusion of both dimensions (AUC=0.65, C). The speech timing model performed significantly better than lexico-semantic features (P=.015) and the fusion of both dimensions (P=.005), while the latter 2 models did not differ significantly (P=.90). The MMSE scores of Spanish-speaking patients correlated significantly with those predicted by between-language regressions based on speech timing features (ρ=0.389, P<.001, RMSE=6.248). Correlations were not significant for regressions based on lexico-semantic features (ρ=–0.306, P=.05, RMSE=6.189) or the combination of both feature sets (ρ=0.042, P=.79, RMSE=6.470).
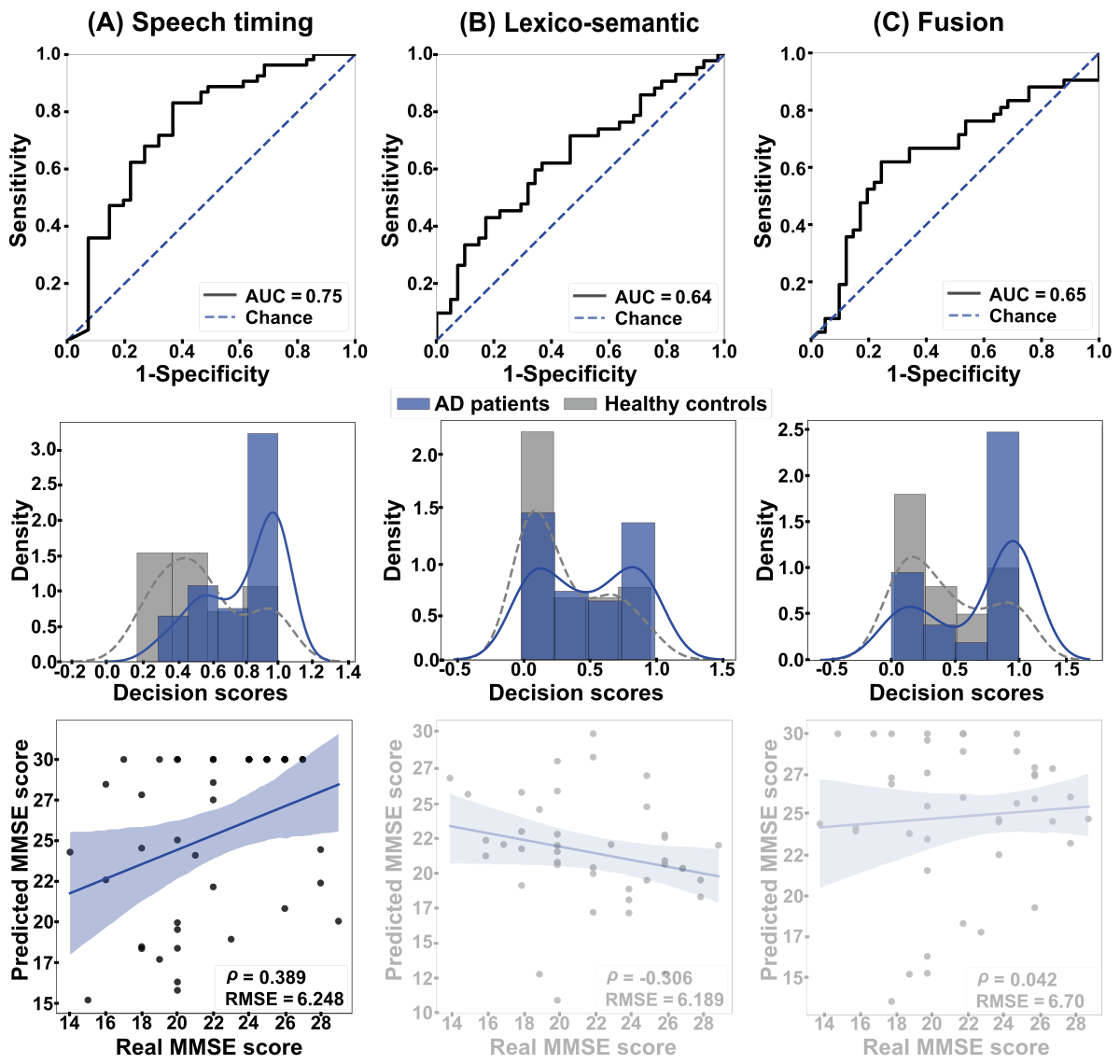 Figure 3. Between-language results. The ROC curves (top row) and the classification scores (middle row) show outcomes for the classification between AD patients and HCs in the English-to-Spanish setting. (A) Discrimination was good when based on speech timing and (B) poor when based on either lexico-semantic features or (C) the combination of both dimensions via early fusion. The bottom row shows correlations between actual and predicted MMSE scores. (A) A strong, significant association emerged when using speech timing features, while (B) nonsignificant correlations were obtained when using lexico-semantic features or (C) the combination of both dimensions. AD: Alzheimer disease; AUC: area under the curve; HC: healthy control; MMSE: Mini-Mental State Examination; RMSE: root mean squared error; ROC: receiver operating characteristic curve.
Figure 3. Between-language results. The ROC curves (top row) and the classification scores (middle row) show outcomes for the classification between AD patients and HCs in the English-to-Spanish setting. (A) Discrimination was good when based on speech timing and (B) poor when based on either lexico-semantic features or (C) the combination of both dimensions via early fusion. The bottom row shows correlations between actual and predicted MMSE scores. (A) A strong, significant association emerged when using speech timing features, while (B) nonsignificant correlations were obtained when using lexico-semantic features or (C) the combination of both dimensions. AD: Alzheimer disease; AUC: area under the curve; HC: healthy control; MMSE: Mini-Mental State Examination; RMSE: root mean squared error; ROC: receiver operating characteristic curve.
To benchmark against commonly used classifiers, we rerun our cross-linguistic analysis using a support vector machine and a support vector regressor. For the support vector machine, the best performance in Spanish was obtained with lexico-semantic features (AUC=0.603), while speech timing and combinations of features performed worse (AUC≤0.458). For the support vector regressor, correlations between predictions and true labels were very low and nonsignificant across feature sets (eg, lexico-semantic features: ρ=–0.075, P=.64; speech timing: ρ=–0.008, P=.96; combination of features: ρ=–0.131, P=.499), with RMSEs ≥4.46.
Discussion
This study used interpretable ASLA features to identify persons with AD in within- and between-language settings. Trained on data from English speakers, our models detected English-speaking patients through timing and lexico-semantic features (especially when combined), with timing features yielding the best prediction of MMSE scores. Conversely, testing on Spanish speakers showed that only speech timing features were useful for identifying patients and capturing their MMSE scores. These findings inform the quest for clinically relevant and cross-linguistically valid ASLA features, as discussed below.
Within-language classification reached AUC values of 0.79 and 0.80 when based on speech timing and lexico-semantic features, respectively. These classification scores resemble those of other acoustic [,,] and linguistic [,,] studies while meeting the requirements of interpretability. As proposed in previous AD research, longer pauses and syllables likely reflect reduced word retrieval efficiency []. Extended silences and phonated segments are typically observed when intended words are not easily retrieved, either because they are not optimally entrenched in memory or because reduced contextual awareness complicates decisions among other lexical candidates. Compatibly, the observed lexico-semantic alterations replicate previous findings from AD research [,]. These include high semantic variability and low semantic granularity, pointing to greater variance in conceptual proximity across words and reduced conceptual precision [,]. Such patterns also seem absent in other neurodegenerative disorders [,], highlighting their role as distinct candidate markers of AD.
Of note, joint analysis of both dimensions yielded an AUC of 0.88, corroborating that within-language AD detection is higher for multimodal (acoustic plus linguistic) than unimodal (eg, linguistic only) ASLA approaches [,]. Importantly, these results approximate others derived from uninterpretable audio- and text-level embeddings (eg, Wav2vec and transformer-based models such as BERT) [,], suggesting that focus on interpretable ASLA features does not entail a loss of sensitivity. Briefly, the integration of strategic acoustic and linguistic features can optimize AD identification while illuminating patients’ cognitive dysfunctions.
Further, timing features successfully captured patients’ MMSE scores in the within-language setting. This replicates previous works based on timing and other audio-derived features [,,], underscoring the importance of speech rhythm as a candidate marker of the disorder []. Specific speech dimensions, then, seem related to overall cognitive status in AD—a promising finding given the vast intra- and interindividual cognitive heterogeneity across patients [].
Additional insights were obtained through between-language analyses. Identification of AD patients was significantly better for timing features (AUC=0.75) than for lexico-semantic or fusion features (AUCs<0.65). Accordingly, we propose that low word retrieval efficiency (captured by timing metrics) would represent a general cognitive trait of AD, affecting verbal production irrespective of the patient’s language. Indeed, this dimension has enabled AD detection in separate studies targeting languages as diverse as English, Spanish, and Mandarin Chinese [,-]. Conversely, lower cross-linguistic generalization for lexico-semantic patterns would follow from the vast vocabulary differences across typologically distant languages [,]. Indeed, specific linguistic patterns may exhibit different and even opposite alterations in AD depending on the patients’ language—for example, pronouns are overused by English-speaking patients and underused by patients who speak Bengali, a language with a more complex pronoun system []. Importantly, features yielding moderate AUCs can still support clinical decision-making when interpretability and generalizability are prioritized []. Briefly, timing features seem to outperform lexico-semantic features as potential cross-linguistically valid markers of AD.
The poor cross-linguistic performance of lexico-semantic features invites reflection for further research. First, weak classification and MMSE prediction results may reflect the inadequacy of the specific features we used rather than an overarching futility of lexico-semantic measures for between-language studies. In fact, it might even be that these very features do generalize robustly between other (eg, typologically close) language pairs. Further, beyond our study’s goals, cross-linguistic generalizability might be enhanced through alternative strategies, including transfer learning and model training with data from multiple languages [].
This notion is reinforced by MMSE estimation results. In the between-language setting, MMSE scores were captured by timing features, but not by the lexico-semantic or fusion models. Compatibly, a model trained on silence features and acoustic embeddings from English-speaking patients with AD and HCs yielded good prediction of MMSE scores in a Greek-speaking sample []. Thus, speech timing features emerge as promising candidates not only for identifying patients but also for estimating symptom severity across typologically different languages.
Note that our approach cannot ascertain the cause of observed anomalies. In particular, speech timing anomalies may certainly reflect cognitive deficits, but they may also reflect motor speech dysfunction. While motor deficits are rarely reported in AD, they may be present in several cases [], inviting new studies integrating relevant measures for patient stratification or covariance analysis. The same analytical approaches could be used with strategic measures (eg, picture naming response times) to test the conjecture that speech timing metrics reflect lexical retrieval effort.
Our results bear clinical implications. First, the features used here, as opposed to scores from black-box models, may enhance patient phenotyping and therapeutic decision-making. Indeed, they can be linked to specific cognitive dysfunctions that practitioners are well versed in. Second, they indicate that some, but not all, findings from Anglophone samples may be useful for assessing AD in other Indo-European language communities. The point is important because of the overrepresentation of English in ASLA studies [,] and the tendency to derive language-agnostic conclusions from the Pitt Corpus (the English-language dataset used here, which has been leveraged by numerous studies) [,,,,] and wide-ranging research challenges []. Third, our approach rests entirely on automated methods, increasing cost-efficiency and scalability while minimizing the potential for human error. In this sense, our pipeline has been deployed in a recent version of the Toolkit to Examine Lifelike Language, a speech testing app used in several clinics worldwide [,,]. This allows for its widespread implementation in actual screening, diagnostic, and monitoring scenarios—a key milestone for bridging the gap between basic research and real-world applications.
Yet, our work is not without limitations. First, the 2 datasets we used differed in terms of acquisition conditions. Although we included gold-standard audio normalization steps ensuring comparability, it would be useful to replicate our approach with harmonized cross-linguistic protocols. Second, AD in the English dataset was established before the release of contemporary diagnostic criteria. Although we chose patients with AD-consistent MMSE scores and ensured their sociodemographic matching with same-language controls as well as Spanish-speaking groups, future works should replicate our approach with Anglophone cohorts fulfilling NINCDS-ADRDA criteria or other validated standards. Third, we acknowledge that the limited sample size, especially in the Spanish cohort, restricts statistical power and constrains our capacity to rigorously assess model generalization. Future works should aim for substantially larger groups and include models trained with Spanish speakers and tested on English speakers—thus illuminating their potential for bidirectional generalizability while enabling alternative analytical approaches, based on cross-linguistic calibration or transfer. Fourth, while we controlled for sociodemographic variables, and participants’ dialects were consistent within language groups, our datasets lacked data on education quality, cultural communication norms, and other factors influencing speech production. Future studies should be strategically designed to tackle these factors.
Fifth, we lacked data on when and how examiners intervened during participants’ descriptions. While all examiners’ segments were removed, future works should contemplate the potential impact of this factor. Sixth, our cross-sectional design reveals features that are sensitive to patients’ current cognitive status, but moot on their clinical trajectories. Longitudinal datasets should be leveraged to examine whether these features can predict AD progression. Seventh, though vital for enhancing VAD and downstream processing [,], denoising in our preprocessing pipeline might have introduced speech artifacts. These were mitigated through manual revision of all processed audio files and careful tuning of the algorithm’s threshold parameters to minimize unintended distortions. Yet, future studies with more controlled acoustic conditions (eg, in recording booths) could replicate our approach without applying denoising. Eighth, while our 0-shot framework provides insights into the cross-linguistic generalizability of interpretable features, we recognize that performance could likely be improved through few-shot learning strategies, particularly if small amounts of target-language data are available [,]. Prior studies leveraging embeddings have demonstrated such gains [], though often at the cost of transparency. Future research should explore hybrid approaches that incorporate limited target-language samples to enhance model robustness while preserving clinical interpretability.
Finally, note that we aimed to examine whether a model trained in 1 language can generalize to another using interpretable features. Thus, we avoided multilingual large language models or Wav2vec-style embeddings due to their lack of clinical interpretability. Likewise, we did not aim to train a model with interpretable features from both languages, as this would have hindered insights into cross-linguistic generalizability. Such strategies could be leveraged in further research with different goals. Here, evidence that an English-only model can be applied to a lower-resource language helps in understanding which mainstream (English-based) results might hold promise for global speech and language frameworks. Thus, future works should compare our target features with embedding-based features to establish whether interpretability involves a trade-off with sensitivity.
In sum, this study reveals 2 novel empirical patterns for ASLA research on dementia. Interpretable timing and lexico-semantic features support AD detection and cognitive decline estimation among English speakers, but only timing features generalize well from English to Spanish speakers. This suggests that timing features are more language-agnostic than lexico-semantic features. Further work can aid the search for cross-linguistic and language-specific ASLA markers of brain health.
We express our gratitude for the thought-provoking discussions around this paper’s topic with members of the International Network for Cross-Linguistic Research on Brain Health (Include). No generative artificial intelligence tools (eg, ChatGPT or similar large language models) were used in any portion of the paper’s generation, including writing, editing, data analysis, or figure creation. All content was developed exclusively by the authors. This work was partially funded by the joint project between GITA Lab and the CNC (PI2023-58010) and EVUK program (“Next-generation Al for Integrated Diagnostics”) of the Free State of Bavaria. BLT is supported by the Global Brain Health Institute, Alzheimer’s Association (AACSFD-22-972143), University of California, San Francisco, National Institutes of Health (NIA R21AG068757, R01 AG080469, R01 AG083840, UF1 NS 100608, U01 NS128913, NIA P01AG019724), Alzheimer’s Disease Research Center of California (P30 AG062422). JdL is supported by the Alzheimer’s Association (AARGD-22-923915) and the National Institutes of Health (K23DC018021, R01AG080396). AI is supported by grants from ReD-Lat (National Institutes of Health and the Fogarty International Center [FIC], National Institutes of Aging [R01 AG057234, R01 AG075775, R01 AG21051, R01 AG083799, CARDS-NIH], Alzheimer’s Association [SG-20-725707], Rainwater Charitable Foundation—The Bluefield project to cure frontotemporal dementia, and Global Brain Health Institute), ANID (Agencia Nacional de Investigación y Desarrollo)/fondecyt Regular (1250317, 1250091, 1220995); and ANID/FONDAP (Fomentamos la Investigación Asociativa que se Desarrolla en el País)/15150012. AG is an Atlantic Fellow at the Global Brain Health Institute (GBHI) and is partially supported with funding from the National Institute on Aging of the National Institutes of Health (R01AG075775, 2P01AG019724-21A1); ANID (fondecyt Regular 1250317, 1250091); the Latin American Brain Health Institute (BrainLat), Universidad Adolfo Ibáñez, Santiago, Chile (#BL-SRGP2021-01); ANII (EI-X-2023-1-176993); Programa Interdisciplinario de Investigación Experimental en Comunicación y Cognición (PIIECC), Facultad de Humanidades, Universidad de Santiago de Chile (USACH). The contents of this publication are solely the responsibility of the authors and do not represent the official views of these institutions.
The demographic information and feature matrices extracted for both datasets are available online [].
PAP-T handled work on the methodology, software, and visualization, curated the data, and wrote the original draft. FJF and GP worked on the methodology, formal analysis, writing of the original draft, and visualization. BLT, JdL, EN, MS, AM, and MLG-T reviewed and edited the writing. AS acquired resources and curated the data. AI acquired resources, and reviewed and edited the writing. JRO-A carried out work for the methodology, software, and visualization, and wrote the original draft. AG put effort into the conceptualization, methodology, visualization, acquiring resources, reviewing and editing the writing, supervising this study, administering this project, and acquiring funding for this study.
None declared.
Edited by J Sarvestan; submitted 22.Mar.2025; peer-reviewed by R He, LER Simmatis; comments to author 13.May.2025; revised version received 15.Jul.2025; accepted 05.Sep.2025; published 15.Oct.2025.
©Paula Andrea Pérez-Toro, Franco J Ferrante, Gonzalo Pérez, Boon Lead Tee, Jessica de Leon, Elmar Nöth, Maria Schuster, Andreas Maier, Andrea Slachevsky, Maria Luisa Gorno-Tempini, Agustín Ibáñez, Juan Rafael Orozco-Arroyave, Adolfo García. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 15.Oct.2025.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work, first published in the Journal of Medical Internet Research (ISSN 1438-8871), is properly cited. The complete bibliographic information, a link to the original publication on https://www.jmir.org/, as well as this copyright and license information must be included.