
We applied two complementary spectroscopic eclipse mapping methods to the data: Eigenspectra7 and ThERESA29. We used two methods because, as described below, they interpret the data in distinct ways, giving us a way to check which conclusions derived from the eclipse maps are robust to differences in mapping methods. While Eigenspectra fits the spectroscopic data well, ThERESA struggled to match the emission features in the data, as ThERESA simultaneously fits a three-dimensional (3D) model to all the spectroscopic light curves, giving the model less flexibility than fitting each spectroscopic bin individually. Therefore, we chose to highlight only the Eigenspectra method in the main text, but we include ThERESA here as an independent check to verify some of the main results from Eigenspectra. Below, we describe some potential paths for future research to investigate how to improve multiwavelength eclipse mapping. Both methods start with the wavelength-resolved, systematics-corrected light curves presented in ref. 3.
Mapping with Eigenspectra
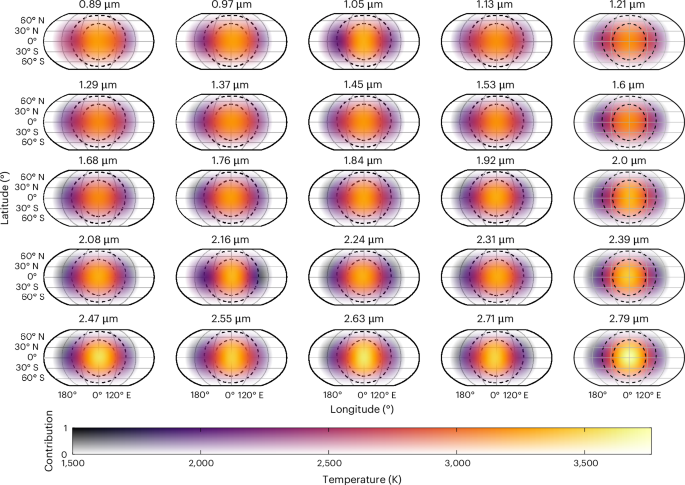
The Eigenspectra method7 splits 3D eclipse mapping into two stages. In the first stage, 2D brightness temperature maps are constructed for each wavelength bin following the eigenmapping method8. First, we derive an orthogonal basis set of light curves from spherical-harmonic light curves using principal component analysis, where each light curve has a corresponding 2D map component. Then, we perform a 2D fit at each wavelength using a subset of this basis set of light curves. The fitting begins with a small number of components, and the number of components is increased until the BIC indicates that the addition of more components is not preferred. For the fits presented in the main text, the 2D mapping preferred 4 or 5 free parameters at each wavelength, except for the fit at 1.05 μm, which preferred 7 free parameters. To perform multiwavelength mapping, Eigenspectra then extracts spectra from a grid of points in latitude and longitude across the visible area of the planet and uses a k-means clustering algorithm to identify regions of the planet with similarly shaped spectra. This grouping is repeated in a Markov-chain Monte Carlo (MCMC) framework to estimate uncertainties in the resulting grouped spectra.
The number of distinct groups is chosen by starting with one group and increasing the number one by one until the largest number of groups for which individual pixels are sorted into the same group across 75% of the MCMC map iterations is identified. This ensures that the number of groups is limited by the ability of the data to precisely sort latitude/longitude points into the best-fit group. We note that the 75% cut-off was chosen arbitrarily based on visually inspecting the results for different numbers of groups. Future work to perform Eigenspectra mapping on a larger sample of planets should further investigate whether this cut-off holds across different datasets. Supplementary Fig. 1 shows the mean group maps and histograms of the assigned group for randomly chosen points on the map for the 25-bin analysis described in the main text. The data showed a clear separation between groups when using two or three groups, but became mixed when using four groups.
We note that the grouping performed by Eigenspectra creates discrete spectra, but these discrete spectra probably represent a true planet with continuous properties, such as a smooth temperature gradient. The k-means clustering allows us to set the number of groups by the precision of the data, such that a more precise dataset would be able to identify more spectra, because the change in properties required to distinguish two spectra with smaller error bars is correspondingly smaller. In the limit of infinitely precise data, each latitude/longitude point would be identified as a distinct group with distinct properties. However, this discrete representation allows us to determine how much the properties change across the visible area of the planet in a way that is regulated by the signal to noise of the real observational data.
For each identified group, the Eigenspectra method then creates a representative spectrum by taking an area- and visibility-weighted mean of the spectrum of each point included in the group, and scaling it by an area weighting to represent it on the same scale as a regular secondary eclipse spectrum, which covers a full visible hemisphere of a planet. The primary outputs of this mapping method are therefore a handful of spectra representing emission from different regions on the planet, which are run through atmospheric inference (retrieval) codes to measure molecular abundances and thermal structures. By virtue of the area and visibility weighting, the eigenspectra are mathematically defined such that they should produce a hemisphere-integrated brightness equivalent to that of the full eclipse spectrum. Extended Data Fig. 2 shows that the hemisphere-integrated brightness indeed matches the wavelength-binned eclipse spectrum from ref. 3.
The error bars on the grouped spectra are calculated by taking the standard deviation of each point included in a group across all MCMC realizations of the planet map. The MCMC runs used 100 walkers, 7,000 steps and a burn-in of 700 steps. Convergence was evaluated by ensuring that the chain was at least 50 times as long as the autocorrelation timescale (see the emcee30 documentation at https://emcee.readthedocs.io/en/stable/tutorials/autocorr/). After calculating the errors in this way, we found that the hemisphere-integrated brightness had slightly smaller error bars than those from the original dayside eclipse spectrum from ref. 3. We tested running retrievals in the same format as the fiducial retrievals but with the error bars scaled up by a factor to match the original dayside eclipse spectrum, and we found that this change did not impact the retrieval results.
The method described above closely follows the method for mapping with Eigenspectra described in ref. 7, with two key improvements. First, for the 2D mapping with the eigencurves method, we restricted allowed planet maps to those which produce positive fluxes at all observed latitudes and longitudes, as a realistic planet must have positive thermal emission. Second, the area weighting was applied to the resulting mean spectra for each group to allow atmospheric retrieval with standard secondary eclipse retrieval codes. We computed per-point spectra on a grid with a resolution of 1° in both latitude and longitude. We also tested grids with a resolution of 3° and 9° and found that the positions of the groupings did not depend on the grid resolution.
The analysis described in the main text used 25 wavelength bins evenly spaced between 0.85 μm and 2.83 μm, with a width of 0.079 μm. We achieve reduced χ2 values of 1.02–1.39 for the single-wavelength eigenmapping fits, with between 4 and 7 free parameters per fit and 2,719 data points, and an overall \({\chi }_{\nu }^{2}=1.19\) for the full multiwavelength eigenmapping fit. The best fits at each wavelength were obtained with a small number of eigenmapping components, restricting the resulting maps to the large-scale patterns characteristic of low-order spherical harmonics. The \({\chi }_{\nu }^{2}\) values at each wavelength are slightly above the expected value of 1 for a fit with correctly estimated error bars. These elevated values are likely because the spectroscopic light curves were corrected for systematics at a higher resolution by ref. 3 and then later binned down for use in this work. We recommend that future work investigate removing systematics at the same wavelength resolution at which eclipse mapping fits are performed, and/or performing simultaneous systematics and eclipse mapping fits.
In addition to the 25-wavelength-bin fit described in the main text, we tested whether the results depended on the wavelength resolution by running a lower-resolution Eigenspectra fit. The lower-resolution fit had eight wavelength bins, with their central wavelengths and widths optimally chosen to capture spectral features seen in the original secondary eclipse spectrum (Table 1). The light curve fits for the 8 wavelength bins had reduced χ2 values between 1.22 and 2.26, with between 4 and 6 free parameters per fit and 2,719 data points. The larger reduced χ2 values are probably due to the greater amount of binning applied to the original data. We found that the temperature maps had the same shape as for the 25-bin fit, and the Eigenspectra method still identified 3 distinct spectral groups in nested rings. In addition, atmospheric retrievals on the 8-bin hotspot and ring groups showed consistent results with the 25-bin retrievals. We ultimately used the 25-bin spectrum for the main results because of the greater spectral resolution, but we used the 8-bin spectrum for comparison with the more computationally intensive ThERESA method, which could not be run on a greater number of wavelength bins within a reasonable timeframe.
To provide a quantitative analysis of how much of our mapping information comes from the phase-curve variation versus the eclipse itself, we compared our fit against one where we allow for only phase-curve variation, represented by a double sine function, and assume a standard box-shaped eclipse with no additional perturbations to the shape of ingress or egress. We used a double sine function to match the fit to the out-of-eclipse variation performed by ref. 3. The double sine fit had four free parameters, comparable to the four to seven free parameters in the Eigenspectra fits. This model is unphysical, as a planet with phase-curve variation necessarily has spatial brightness gradients and so should also induce a signal during ingress and egress, but with this approach we are artificially requiring the eclipse shape to match that of a planet with uniform brightness. A comparison between these two fits then reveals how much signal is contributed solely from the eclipse. We computed the BIC for both models and found a ΔBIC between −3 and 713 depending on the wavelength, with a positive number indicating a preference for the Eigenspectra fit. For 17 of the 25 wavelength bins, the ΔBIC was 10, indicating a strong preference for the Eigenspectra fit over the sinusoid fit. However, at some wavelengths, the improvement is marginal. This lack of strong preference for the eclipse mapping fit over a sinusoidal fit is due to several factors, including: (1) WASP-18b rotates substantially during our eclipse observation, creating considerable phase-curve variation that is present in a large part of the dataset relative to ingress and egress, and (2) WASP-18b’s low impact parameter reduces the strength of signatures of latitudinal temperature variation. However, the Eigenspectra analysis still provides multidimensional information that is not obtained from a simple sinusoidal phase variation fit—namely, the Eigenspectra fit reveals the radial extent of the hotspot so that its composition can be inferred separately from the surrounding dayside. Other planets will probably be even better targets for 2D and 3D characterization with JWST31.
The component of eclipse mapping that can be uniquely inferred through secondary eclipses and not out-of-eclipse phase-curve variation is latitudinal structure. Although the Eigenspectra maps show a lack of any latitudinal offset, this does not reflect an inability to constrain latitudinal information. To test the ability of the Eigenspectra fits to constrain latitudinal information, we follow methods similar to ref. 32 and artificially inject a latitudinal offset into the observations. Supplementary Figs. 2 and 3 show the light curves resulting from the minimum and maximum latitudinal offsets that produce fits with χ2 ≤ 10 higher than the best fit in each wavelength bin. We found that this requirement results in a median constraint on the latitudinal offset of −29° to 61°. This comparison demonstrates that the Eigenspectra method would be able to detect latitudinal structure outside this range if such structure existed.
Table 1 lists the grouped 25-bin spectra resulting from the Eigenspectra analysis used in the main text, and Supplementary Table 1 lists the 8-bin spectra used for comparison with ThERESA. The hotspot, ring and outer groups had a mean signal to noise of 483, 226 and 90, respectively. As described in the main text, although Eigenspectra identified three groups, we chose to fully analyse only two, the hotspot and ring. We chose not to apply atmospheric retrievals to the outer group because it had a signal-to-noise factor of ~2.5–12× smaller than the other spectra and a much smaller contribution to the secondary eclipse signal. While this may not appear to be a sizable difference in signal to noise, it probably indicates that the shape of the outer group is being driven by the fitting method rather than the data. As described above, the best 2D fit at each wavelength has a small number of eigenmapping components, and therefore will show only large-scale patterns characteristic of low-order spherical harmonics. Therefore, we suspect the shape of the outer group is primarily driven by the requirement of a smoothly varying map consistent with the much higher signal-to-noise hotspot and ring regions.
Mapping with ThERESA
Similar to Eigenspectra, ThERESA splits 3D eclipse mapping into two stages: 2D mapping and 3D mapping. First, it constructs 2D star-normalized flux maps of the planet at each wavelength bin in the observation, using the eigenmapping method8. This methodology is identical to 2D mapping with Eigenspectra (Supplementary Fig. 4), although with ThERESA we use only eight spectroscopic bins (the aforementioned lower-resolution fit; Supplementary Table 1) to reduce the model complexity (see below). To ensure physically plausible maps, we enforce a positive-flux constraint at the longitudes that are visible during the observation (−134.7–151.8°). To convert these flux maps into brightness temperature maps, we first compute a grid of planet brightness temperature versus star-normalized planet flux, assuming that the planet emits as a blackbody and using a PHOENIX33 model for the stellar spectrum. Then we interpolate this grid to the fluxes in our observed maps to determine the brightness temperatures of the the maps. Because these maps cover a relatively small wavelength range and our wavelength bins are chosen to probe small pressure ranges, converting these flux maps to brightness temperature maps is a reasonable choice for the 3D mapping (described below).
For the 3D mapping, ThERESA parameterizes the vertical placement of each of the 2D brightness temperature maps. We test both a simple parameterization, where each 2D temperature map is placed at a single pressure level, and a more complex parameterization where the depth of the temperature map has a sinusoidal dependence on latitude and longitude, and the phase of the longitudinal sinusoid is allowed to vary. Effectively, this sinusoidal model allows the photosphere to shift vertically with changing instellation and the resultant impact on temperature. The 3D model also includes an internal temperature parameter that sets the temperature of the bottom of the atmosphere at all latitudes and longitudes. We linearly interpolate, in log(pressures), along each column of the atmosphere between the 2D temperature maps and the internal temperature to create a 3D temperature grid. The atmosphere is assumed to be isothermal above the highest-altitude 2D temperature map.
We then apply solar-abundance thermochemical equilibrium to each cell of the 3D temperature grid to calculate the atmosphere’s chemical composition. For computational speed, we precompute a grid of chemical abundances versus temperature and pressure using GGChem34, and then interpolate to the temperatures in the model atmosphere. Based in part on 1D atmospheric characterization of WASP-18b3, we include H2O, CO, CO2, TiO, VO and H− in the atmosphere. We then calculate an emission spectrum from each column of the atmosphere using TauREx35 and integrate over the visible part of the atmosphere at each observation time, including the effects of planetary rotation, the angle between the sub-observer point and each grid cell, the area of each grid cell, and the occultation by the star. We use ExoTransmit36 molecular opacities and compute the model at the opacity native resolution (R ≈ 1,000), which is then binned to the data resolution. The model has 100 pressure layers evenly placed in log space between 0.0001 bar and 100 bar.
The resulting spectroscopic light curves are then compared against the data. This process (3D temperature grid parameterization, composition calculation, emission spectra calculation and spatial integration) is repeated behind an MCMC routine to explore the parameter space. For MCMC, we use the MC3 package37, which implements differential evolution Markov chains that can efficiently sample high-dimensional (>50) parameter spaces using a low number of chains38. We use 7 chains and run a total of ~1.4 million total iterations. For comparison with the Eigenspectra mapping, we achieve autocorrelation lengths of 21–50 for each parameter in the model. We calculate contribution functions for each spectroscopic bin and apply a penalty to the model goodness of fit if the vertical positions of the 2D brightness temperature maps are inconsistent with the contribution functions29. This penalty is a confidence-region-like calculation where, if the vertical position of a given 2D map falls within the pressures where 68.3% (1σ) of planetary emission at that wavelength originates, then there is effectively no penalty, but at substantially higher or lower pressures the penalty effectively causes the model to be rejected.
The full 3D temperature map is shown in Supplementary Fig. 5. Broadly, the 3D temperature structures agree with Eigenspectra, with a thermal inversion near the substellar point that transitions to roughly isothermal near the limbs. We achieve a reduced χ2 of 1.56 over all the spectroscopic light curves (33 model parameters, 21,752 data points), slightly worse than the Eigenspectra (Fig. 1) or the 2D ThERESA (Supplementary Fig. 4) fits. When considering all wavelengths together, the model residuals are well behaved and distributed Gaussian-like around zero. However, we note that ThERESA systematically overestimates or underestimates the light curves at certain wavelengths, and if the 3D model is post-processed into emission spectra (assuming thermochemical equilibrium and solar atomic abundances) from the planetary regions defined by Eigenspectra, the ThERESA spectra struggle to match the H2O features in the data. Models that create these emission features are within the parameter space we explored, but these models are rejected because they require increasing the temperature of the upper atmosphere, which leads to an overestimation of the total planetary emission, and such models also violate the contribution–function–consistency criterion. Because of this discrepancy with the observed spectra, we opt to only report the Eigenspectra results in the main text, which do not experience similar difficulties in fitting the spectroscopic data.
This mismatch motivates several avenues for additional work to understand 3D atmospheric retrieval with JWST data. First, ThERESA assumes that the planet’s upper atmosphere is isothermal, an assumption that worked well for synthetic data based on GCMs29 but may depress molecular emission features necessary to fit these data. Adjustments to the thermal profile parameterization that allow for flexibility in upper atmospheric temperature gradients would probably give the model the capability to match stronger molecular features. Second, ThERESA aims to place 2D brightness temperature maps at the pressures corresponding to contribution function maxima, to prevent non-physical scenarios where the 2D maps are placed at extremely high or low pressures. In reality, these 2D brightness temperatures come from a range of pressures, so the corresponding emission over that range, not just the emission at the peak of the contribution function, should be consistent with the 2D maps. Modifying the contribution function consistency check in this way would probably also reduce the model’s chances of creating an extended isothermal upper atmosphere. Finally, for simplicity, ThERESA assumes thermochemical equilibrium at solar atomic abundances. Expanding this framework to fit for bulk metallicity and C/O ratio, for example, could give the model some of the additional flexibility it needs to fit the data.
Eclipse mapping null space
Some finer-resolution spatial flux patterns are inaccessible to eclipse mapping analyses, as they create zero signal during the observation39,40. These patterns, collectively referred to as the eclipse mapping null space, need to be removed from GCMs before comparing them against measured eclipse maps, as the measured maps will never place constraints on the null-space patterns. The GCMs presented in Fig. 2 have been processed to remove the null space by representing the GCMs as high-degree spherical-harmonic maps, using principal component analysis to identify null components of the map, and removing those null components40.
Retrievals on EigenspectraHyDRA
HyDRA9,10,11,12 is an atmospheric-retrieval framework that combines a parametric forward atmospheric model with a nested sampling Bayesian parameter estimation algorithm, PYMULTINEST41,42,43. The inputs to the forward model include six parameters for the temperature–pressure profile, and the deep-atmosphere abundances of each of the chemical species considered. In particular, we use the temperature–pressure profile parameterization of ref. 44, which has been used extensively for atmospheric retrievals of exoplanet atmospheres, including ultrahot Jupiters such as WASP-18b3,10. The model also includes the abundances of chemical species that have opacity in the 0.8–2.8 μm range and are expected in H2-rich atmospheres10,45: collision-induced absorption due to H2–H2 and H2–He (ref. 46), H2O (ref. 47), CO (ref. 47), CO2 (ref. 47), HCN (ref. 48), OH (ref. 47), TiO (ref. 49), VO (ref. 50), FeH (ref. 51), Na (ref. 52), K (ref. 52) and H− (refs. 53,54). For each opacity source, line-by-line absorption cross-sections55 are calculated using data from the references listed. The opacity from H− free–free and bound–free transitions is calculated using the methods of refs. 53,54, respectively. We additionally include the effects of thermal dissociation for H2O, TiO, VO and H−. The depletion in the abundances of these species is calculated as a function of pressure and temperature, using a parametric method22. For all other species, the abundances are assumed to be constant with depth. In some of the retrievals, we additionally test the effects of adding a ‘dilution’ parameter (an area covering fraction), which multiplies the overall emission spectrum by a constant factor between 0 and 1 (ref. 56).
The forward model computes the thermal emission spectrum of the atmosphere given the input parameters described above. The pressure range considered is 10−5–103 bar. The spectrum is calculated at a resolving power of R ≈ 15,000, and is convolved to the resolution of the instrument before being binned to the data resolution. The binned model is compared with the data to calculate the likelihood of the model instance. We use 2,000 live points in the nested sampling parameter estimation algorithm. HyDRA ultimately outputs the posterior probability distributions for each model parameter, from which we calculate the median and 1σ contours for the retrieved spectrum, temperature profile and chemical abundance profiles. We additionally perform Bayesian model comparisons to determine the evidence for one model (for example, including a particular molecule) over another (for example, which excludes that molecule). To do this, we compare the Bayesian evidence from the retrievals using each model, which we convert to a ‘sigma’ confidence value using the methods of ref. 57.
Pyrat Bay modelling framework
Pyrat Bay is an open-source framework that enables atmospheric modelling, spectral synthesis and Bayesian retrievals of exoplanet observations13. The atmospheric model consists of 1D parametric profiles of the temperature, volume mixing ratios (VMRs) and altitude as a function of pressure (hydrostatic equilibrium). For this analysis, we considered a pressure array extending from 10−9 bar to 100 bar and a wavelength array from 0.8 μm to 3.0 μm sampled at a resolving power of R = 15,000. The temperature profile follows the parametric prescription of ref. 44. Our framework computes abundances in thermochemical equilibrium via a Gibbs free-energy optimization code that combines the flexibility and performance of previous chemical frameworks58,59. This chemical code produces VMR profiles consistent with the pressure, temperature and elemental composition of the atmosphere at each layer. The chemical network includes 45 neutral and ionic species that are the main carriers of H, He, C, N, O, Na, Si, S, K, Ti, V and Fe. We adopted three free parameters to vary the elemental composition at each iteration: a carbon-abundance scaling factor ([C/H], relative to solar values), an oxygen scaling factor ([O/H]) and a third ‘catch-all’ parameter that scales the abundance of all other metals ([M/H]). The altitude of each layer is calculated assuming hydrostatic equilibrium. Finally, we also considered a free parameter for dilution56, which accounts for spatial inhomogeneities of the planetary flux.
For a given set of atmospheric parameters, Pyrat Bay computes the emission spectrum considering opacities from the Na and K resonant lines60; H, H2 and He Rayleigh scattering61; H2–H2 and H2–He collision-induced absorption62,63,64,65,66,67; H− free–free and bound–free opacity54; and molecular line lists for CO, VO, H2O and TiO (refs. 49,50,68,69). To process the large molecular line-list opacity files, we applied the REPACK package70 to extract the dominant line transitions, which we then sampled over a temperature, pressure and wavelength grid for interpolation during retrieval runs. The Bayesian sampling in Pyrat Bay is managed with the MC3 package37, in this case using the MULTINEST nested sampling algorithm41,42 with 1,500 live points.
Hotspot group retrievals
Supplementary Figs. 6 and 7 show the results from retrievals on the hotspot group. Both retrievals of the hotspot group find a strong thermal inversion around the ~1 bar pressure level, where the temperature increases from 2,900 K to 3,300 K. Above this level, most molecules start to thermally dissociate, depleting the upper layers of the main optical/near-infrared absorbers (H2O, TiO and H−). The retrieved spectra are dominated by a series of H2O emission bands at wavelength λ > 1.25 μm and by optical opacity (for example, H−, TiO and/or VO) at λ < 1.5 μm. The Pyrat Bay retrieval shows a well-constrained posterior with subsolar elemental abundances ([M/H] = −0.22 ± 0.16) and a subsolar C/O ratio (C/O = 0.22 ± 0.15); these elemental compositions lead to a water abundance of \({\log }\ {{n}_{{{\rm{H}}}_{2}{\rm{O}}}}=-3.20\pm 0.17\) at the photosphere. Similarly, the HyDRA retrieval shows a well-constrained water abundance of \({\log }\ {{n}_{{{\rm{H}}}_{2}{\rm{O}}}}=-3.{7}_{-0.2}^{+0.3}\), although it is unable to precisely constrain the abundances of any other species. These results generally agree with the full dayside atmospheric constraints3, which is expected as the bright and directly visible hotspot dominates thermal emission throughout the observation.
Ring-group retrievals
Supplementary Figs. 8 and 9 show a summary of retrieved constraints for the ring group. We note that we saw the same results for the ring group when using 8 and 25 wavelength bins. The nominal atmospheric retrievals of the ring group, as well as the ThERESA fit, result in physical properties in stark contrast to the hotspot group, although this depends strongly on the model assumptions, as described below. The nominal models result in non-thermally inverted temperature profiles with brightness temperatures of ~2,500–2,700 K, probed mainly at pressures of 1–10 bar by the observations. This decrease in temperature from ~3,000–3,200 K of the hotspot (Fig. 3) is roughly consistent with the GCMs with atmospheric drag, although the GCM temperatures in the ring region vary considerably with latitude/longitude and show thermal inversions.
Perhaps the most puzzling outcome of the ring-group retrieval is the atmospheric composition. With Pyrat Bay, we found that the abundance posterior distribution was constrained to the C/O > 1 region, leading to extremely low H2O abundances (VMR < 10−6), such that there were no visible H2O absorption bands in the model. Similarly, the nominal HyDRA retrievals on the ring group found very low H2O abundances (also VMR < 10−6), while we would expect VMR ≈ 10−3.3 (Supplementary Fig. 8). In both sets of retrievals, the ring spectrum was mainly dominated by absorption due to H2–H2 and H2–He collision-induced absorption. This represents a drop of over two orders of magnitude in H2O abundance from the hotspot to the ring group. Such a steep gradient in dayside composition seems physically unlikely, especially as H2O is expected to be more abundant in the cooler ring region compared with the hotspot, where thermal dissociation depletes the H2O abundance. In addition, the ring-group spectrum appears by eye to show slight H2O emission features at the same wavelengths where emission features are seen in the hotspot and full dayside spectra (for example, slight peaks at ~1.4 μm and ~1.9 μm; Supplementary Fig. 9). It is, therefore, possible that H2O absorption is shaping the ring-group spectrum, but is incorrectly identified in the retrievals. Finally, the lack of any detected opacity aside from H2–H2 and H2–He collision-induced absorption in the ring group throws into question the validity of the retrieved temperature–pressure profile, as the retrievals would not be sensitive to a wide range of pressures without any species that can change the atmospheric opacity over the wavelengths we investigated.
We suspect that there are physical or geometric effects that the 1D models are not able to capture, hence preventing the retrievals from providing a sound physical interpretation. We found that the standard model was strongly preferred over a simple blackbody (>14σ). The fact that the spectrum shows significant deviations from a blackbody indicates that the results of the standard retrieval are not due to an inability to detect atmospheric features; the data show a clear preference for a model with features over a perfect blackbody.
As a test, we ran additional retrievals fitting the standard model with the addition of a dilution parameter. Supplementary Fig. 9 shows the spectrum for the HyDRA code.
One possible explanation for these results is that what may be a sharper boundary in spectral features between the hotspot and ring groups is smeared out by the 2D eigencurves fitting. Eigencurves fitting is based on maps constructed from relatively low-order spherical harmonics, so it is fundamentally limited to producing maps with relatively smooth gradients7,8. If the true planet showed a rapid change in spectral features at a sharp boundary, the eigencurve mapping may smear out this sharp boundary, producing a mix of spectral features in the resulting group spectra that might confuse standard retrievals. However, we note that the grouped spectra are very similar in shape and amplitude to spectra derived from similar regions of a GCM, perhaps indicating that the eigencurve fitting does not have an oversized impact on the resulting spectra. The specific extent to which eigencurve fitting impacts the spectra can be investigated in the future by applying the Eigenspectra mapping method to GCM outputs where the ground-truth map is known.
We also explored whether the slant viewing angle between the observer and the flux from the ring-group biases the retrievals. For this, we modified the 1D emission models to, instead of integrating the planet intensity over the entire dayside hemisphere, integrating only over a region delimited by \(\cos (\psi )\in (0.6,0.2)\), where ψ is the angle between the line of sight and the intensity vector over the dayside hemisphere. This is the region where the ring-group flux originates. While we confirmed that the slant viewing angle has a wavelength-dependent impact on the emission spectra, we found no significant changes in the retrieved temperatures or abundances between this approach and the nominal retrieval. However, we have not ruled out the possibility that some other effect due to the non-standard geometry may be impacting the retrievals. Temperature variations within the ring-group region could also affect the retrieval results. Indeed, the dilution parameter is designed to account for thermal inhomogeneities due to a hotspot region56, and could be compensating for variations within the relatively large ring-group region, although imperfectly.
We exclude the chemistry results from the ring group from the main text due to our suspicions that the retrievals may be impacted by some combination of the factors listed above. While a more detailed investigation of these possibilities is outside the scope of this work, future research should investigate this further to improve upon spectroscopic eclipse mapping methods. Applying the Eigenspectra method to GCM outputs would allow an investigation of the effects listed above and whether improving upon any of them can increase the fidelity of the retrievals.