

At CES 2026, Phison demonstrated consumer PCs with its aiDAPTIV+ software/hardware combo running AI inference up to ten times faster than without its specialized suite of technologies. When Phison introduced its aiDAPTIV+ technology in mid-2024, it essentially transformed NAND memory into a managed memory tier alongside DRAM to enable large AI models to train or run on systems that did not have enough DDR5 and/or HBM memory, but at the time, it was merely a proof-of-concept aimed at enterprises. By early 2026, the positioning of the technology has changed, and now Phison sees it as an enabler of AI inference models on client PCs, which broadly increases the use-case. So,
Normally, when tokens no longer fit into the GPU’s key-value (KV) cache during inference, older KV entries are evicted, so if/when the model needs those tokens again (in cases of long context or agent loops), the GPU must recompute them from scratch, which makes AI inference inefficient on systems with limited memory capacity. However, with a system equipped with Phison’s aiDAPTIV+ stack, tokens that no longer fit into the GPU’s KV cache are written to flash and retained for future reuse, which can reduce memory requirements in many cases and dramatically increase the time to first token, which is the time it takes to produce the first word of a response.
You may like
Image 1 of 10
 (Image credit: Tom’s Hardware)
(Image credit: Tom’s Hardware) (Image credit: Tom’s Hardware)
(Image credit: Tom’s Hardware)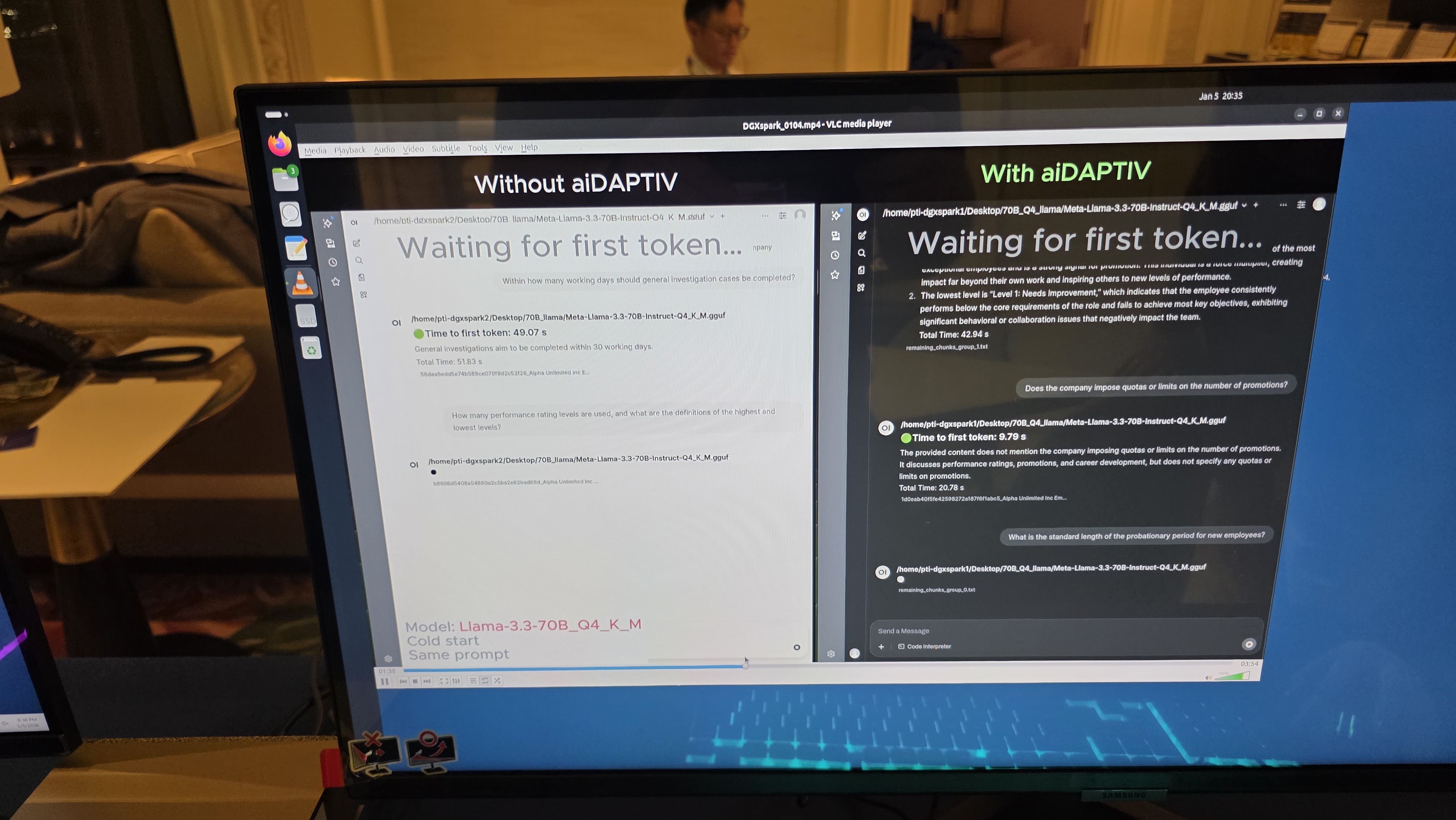 (Image credit: Tom’s Hardware)
(Image credit: Tom’s Hardware) (Image credit: Tom’s Hardware)
(Image credit: Tom’s Hardware) (Image credit: Tom’s Hardware)
(Image credit: Tom’s Hardware) (Image credit: Tom’s Hardware)
(Image credit: Tom’s Hardware)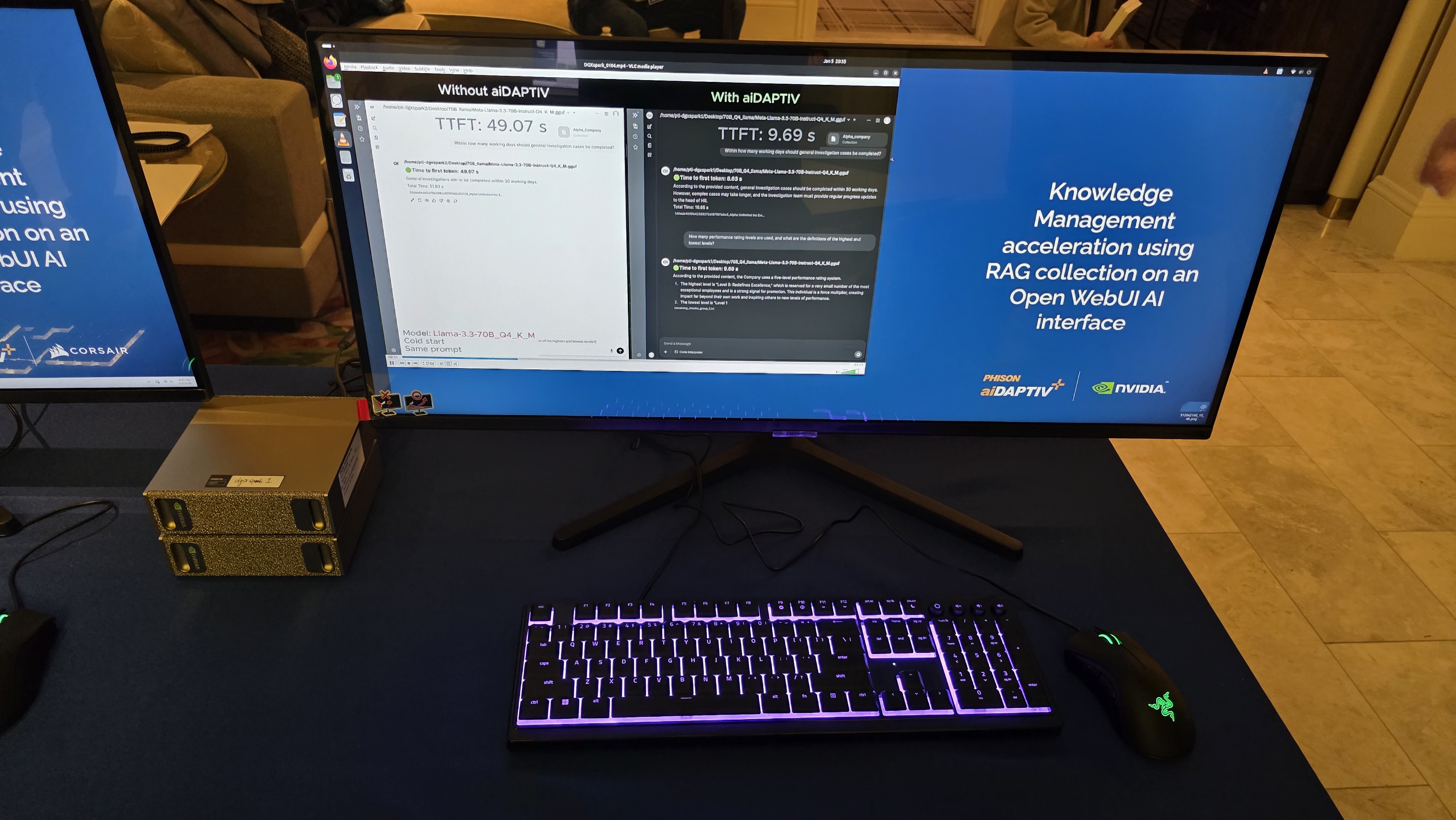 (Image credit: Tom’s Hardware)
(Image credit: Tom’s Hardware)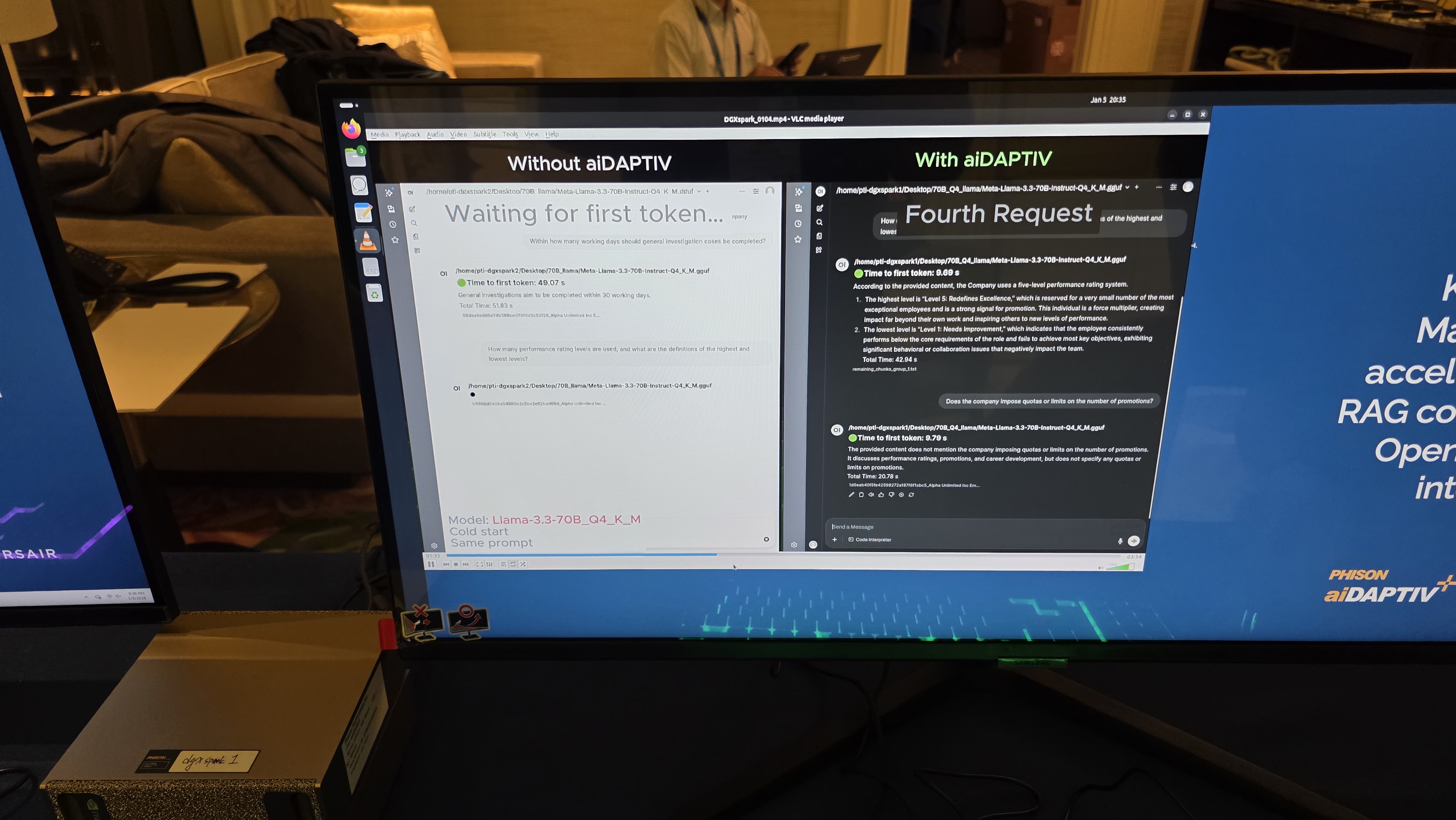 (Image credit: Tom’s Hardware)
(Image credit: Tom’s Hardware) (Image credit: Tom’s Hardware)
(Image credit: Tom’s Hardware) (Image credit: Tom’s Hardware)
(Image credit: Tom’s Hardware)
According to Phison’s internal testing, aiDAPTIV+ can accelerate inference response times by up to 10 times, as well as reduce power consumption and improve Time to First Token on notebook PCs. Obviously, the larger the model and the longer the context, the higher the gain, so the technology is especially relevant for Mixture of Experts models and agentic AI workloads. Phison claims that a 120-billion-parameter MoE model can be handled with 32 GB of DRAM, compared with roughly 96 GB required by conventional approaches, because inactive parameters are kept in flash rather than resident in main memory.
Given that Phison’s aiDAPTIV+ stack involves an AI-aware SSD (or SSDs) based on an advanced controller from Phison, special firmware, and software, the implementation of the technology should be pretty straightforward. This is important for PC makers, value-added resellers, and small businesses interested in using this capability, so it is reasonable to expect a number of them to actually use this technology with their premium models aimed at developers and power users. For Phison, this means usage of their controllers as well as added revenue from selling the aiDAPTIV+ stack to partners.

Follow Tom’s Hardware on Google News, or add us as a preferred source, to get our latest news, analysis, & reviews in your feeds.