
The increasing complexity of modern quantum computers presents a challenge for programmers, who rarely design circuits to directly utilise every physical qubit. Instead, they rely on software to translate circuits into a format compatible with specific hardware. Jeremie Pope and Swaroop Ghosh, from Pennsylvania State University, along with their colleagues, investigate how this translation process affects qubit usage, revealing significant imbalances in how qubits are employed. Their analysis of IBM’s 27-qubit Falcon R4 architecture demonstrates a tendency for certain qubits to become overworked while others remain largely unused, a phenomenon linked to the choices made by transpiler configurations. This research highlights opportunities to improve quantum hardware efficiency, potentially reducing calibration demands, refining optimisation algorithms, and even influencing pricing strategies in shared quantum computing environments to encourage more balanced hardware throughput.
Researchers currently design circuits that directly utilise these qubits, rather than relying on software suites to algorithmically translate the circuit into one compatible with a target machine’s architecture. For connectivity-constrained superconducting architectures, the synthesis, layout, and routing algorithms used to translate a circuit significantly alter the average utilisation patterns of physical qubits. This paper analyses average qubit utilisation of quantum hardware as a means to identify how various translator configurations change utilisation patterns. The team presents preliminary results of this analysis using IBM’s 27-qubit Falcon R4 architecture on the Qiskit platform.
Mapping Algorithms to Real Quantum Hardware
This document provides a comprehensive exploration of quantum software engineering, focusing on the practical challenges of mapping quantum algorithms onto physical quantum hardware. It surveys the field, addressing benchmarking, optimisation, and the pursuit of quantum utility, demonstrating a practical advantage over classical computation. The authors emphasise moving beyond theoretical algorithms towards realisable quantum computation, examining key concepts such as achieving quantum utility, which requires proving a clear advantage over classical methods, and qubit mapping, a complex optimisation problem given the limitations of current hardware. The document highlights the importance of efficient qubit routing algorithms and robust benchmarking techniques to accurately assess quantum computer performance, advocating for a systematic approach to quantum software development, including tools for circuit creation, manipulation, compilation, and optimisation.
A recurring theme is the need for algorithms that can scale to larger numbers of qubits while maintaining fidelity, framing qubit routing as a type of subgraph isomorphism problem, allowing the application of graph algorithms and optimisation techniques. The document discusses algorithms such as Lightsabre and Sabre, designed for qubit mapping and optimisation, and Vf2++, an algorithm for solving subgraph isomorphism problems relevant to qubit routing. It also examines the use of mirror circuits in randomised benchmarking and the Supermarq benchmark suite. The authors acknowledge challenges such as the scalability of routing algorithms, maintaining high fidelity, and developing robust benchmarks, identifying a lack of mature quantum software engineering tools as a hindrance to progress. The document’s key contributions include an emphasis on practicality, framing qubit routing as a graph problem, highlighting the importance of benchmarking, and advocating for a systematic approach to quantum software engineering. It establishes connections between benchmarking and routing, routing and scalability, and software engineering and scalability, providing a valuable overview of the current state of quantum software engineering, highlighting challenges and opportunities in the field.
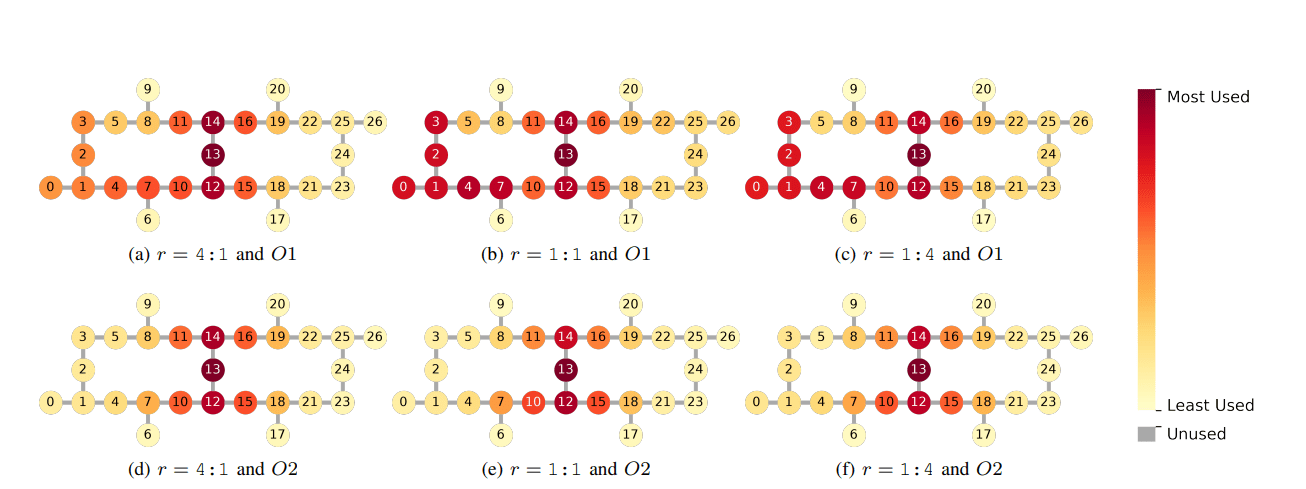
Transpiler Bias and Qubit Utilization Analysis
This work presents a novel method for measuring how different configurations of quantum computer transpilers influence the utilisation of individual qubits. Researchers investigated the 27-qubit Falcon R4 architecture using IBM’s Qiskit platform, focusing on synthetic workloads with a consistent ratio of one to two qubit gates. The team systematically varied transpiler settings and monitored the resulting allocation of quantum operations to physical qubits, revealing a persistent bias towards trivial mapping during transpilation, meaning the system favoured certain qubits over others. To address this, the researchers explored increased optimisation levels, finding that this could improve qubit utilisation, but only when the overall architecture utilisation remained below a specific threshold.
Analysis of qubit allocation demonstrated that some qubits were consistently overused while others remained significantly underused. The synthetic circuits were constructed using defined sets of one and two qubit gates, ensuring a controlled and reproducible testing environment, opening several avenues for improvement, including focusing calibration efforts on the most heavily used qubits to reduce overhead. Refining the algorithms used for optimisation, mapping, and routing could maximise hardware utilisation across all qubits. The researchers also suggest a pricing model for underused qubits, offering lower rates to incentivise their use and improve overall throughput in multi-tenant quantum computing environments, potentially enhancing the efficiency and cost-effectiveness of quantum computation as the technology matures.
Trivial Mapping and Coarse Optimization Balance Qubit Use
This research presents a novel method for analysing how different configurations of quantum software impact the utilisation of individual qubits within a quantum computer. Applying this analysis to IBM’s Falcon R4 architecture, the team discovered a consistent tendency towards trivial mapping, where the software favoured certain qubits over others, particularly at lower optimisation levels. While some limitations were expected, the persistence of this bias, even with varying qubit counts and gate distributions, was notable. The level of coarse optimisation proved to be a key factor in mitigating this uneven qubit usage, guiding the average utilisation towards a more balanced distribution across the architecture. This initial analysis supports continued investigation into these effects, especially as quantum computers grow in size and capability, with future work focusing on exploring real-world workloads and incorporating calibration data to refine understanding of qubit utilisation patterns and establish broadly applicable conclusions. The authors acknowledge that the analysis was performed on a specific architecture and that further research is needed to determine the generalisability of these findings.