
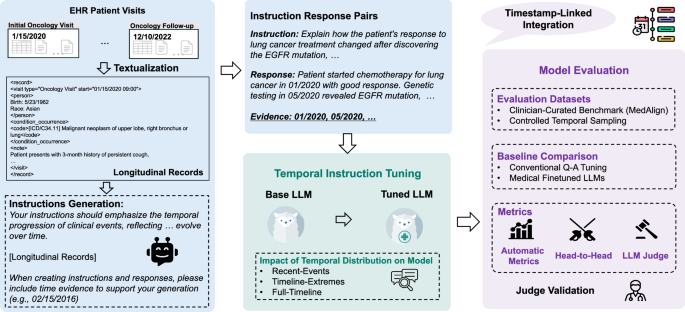
Study design and data source
Figure 1 summarizes the TIMER method for instruction-tuning and evaluating temporal reasoning capabilities of LLMs on longitudinal EHRs. Our study addresses two primary research questions (RQs):
RQ1: Can temporally-grounded instruction-response pairs from EHR data improve LLMs’ longitudinal reasoning capabilities compared to conventional medical question-answer pairs?
RQ2: How does the temporal distribution of instructions used in instruction-tuning affect model performance, specifically when we evaluate on varying temporal distributions?
We used de-identified longitudinal EHRs from the Stanford Medicine Research Data Repository (STARR)17. These records are accessible pre-IRB, cover Stanford Health Care (primarily adult care) and Lucile Packard Children’s Hospital, and are formatted in OMOP-CDM. Only data from patients who have previously consented to the research use of their de-identified data via the institutional privacy notice is included in STARR.
RQ1: Impact of temporal-aware instruction tuning
We compared models instruction-tuned with TIMER against both standard medical LLMs and models tuned with conventional medical QA datasets to quantify the specific benefits of temporal awareness in instruction tuning.
Overall performance
We evaluate multiple medical LLMs, including Meditron-7B, MedAlpaca, AlpaCare, MMed-Llama-3-8B, PMC-Llama-13B, MedLM-Medium, and MedInstruct (Conventional QA-tuned Llama-3.1-8 B-Instruct), using MedAlign and a model-generated evaluation set, called TIMER-Eval, that requires temporal reasoning. When models cannot process full patient timelines, inputs are truncated to recent tokens of their context limits. As shown in Table 1, even the strongest medical model baseline achieves just 30.85% correctness and 13.93% completeness in temporal reasoning evaluations. In contrast, models tuned with TIMER consistently outperform baselines across both evaluation sets. TIMER improves Llama-3.1-8B-Instruct’s performance from 30.69% to 34.32% correctness as measured using MedAlign and from 45.02% to 48.51% as measured via a temporal reasoning evaluation. Similar improvements are observed with Qwen-2.5-7B-Instruct, indicating that these gains are consistent across different base model architectures. TIMER’s performance gains on MedAlign are particularly significant given the dataset’s temporal characteristics. Despite MedAlign’s extended temporal coverage (median 3,895.1 days) and pronounced recency bias (55.3% of questions in the final 25% of timelines), TIMER-tuned models achieve consistent improvements in both correctness and completeness. This demonstrates TIMER’s ability to effectively utilize the full temporal scope of longitudinal records, even when evaluation questions exhibit temporal distribution misalignment.
Table 1 Performance (%) of baseline models and TIMER -tuned models on MedAlign and TIMER-Eval benchmarks, reported as mean ± standard deviation from bootstrap resampling (n = 10,000) with 100 samples over the test set
To illustrate these improvements, Table 7 provides concrete examples of enhanced temporal reasoning. For instance, when asked to “Describe the trend in the patient’s weight over the past year” base models incorrectly assess trends from 2+ years prior, while TIMER-tuned models correctly limit analysis to the specified timeframe, demonstrating improved temporal boundary adherence.
Head-to-head comparison
To further identify performance improvement in addition to rubric-based scoring, we perform head-to-head analyses of outputs to given questions from different models. We identify in Table 2 that models instruction-tuned with temporal instruction data produce answers that are more generally preferred compared to existing medical finetuned models, with even the best medical model MedLM-Medium being preferred 20% less frequently on TIMER-Eval generated questions than models tuned with TIMER.
Table 2 Head-to-head comparison between various models and TIMER-Instruct
Additionally, we compare conventional QA-style tuning (MedInstruct) with our temporally grounded instruction-tuning (TIMER Tuning). While instruction-tuning with MedInstruct provided gains over baseline Llama-3.1-8B-Instruct performance, instruction tuning with TIMER provides additional gains of 6.3% on MedAlign and 8.45% on TIMER-Eval. This indicates the value of incorporating temporal structure into instruction tuning data.
RQ2: Effect of the temporal distribution of instructions on model performanceTemporal biases in existing clinical instruction sets
Existing clinical instruction data have pronounced temporal biases. Using our normalized temporal position metric, we found that MedAlign16, the first clinician-curated collection of clinical instructions, has a pronounced recency bias. Despite spanning an average of 3895 days (~10.7 years), 55.3% of its instructions reference only the final 25% of patient timelines, with 47.0% and 29.5% focused on just the last 15% and 5%, respectively (Fig. 2).
Fig. 2: Distribution of MedAlign instructions across patient timelines.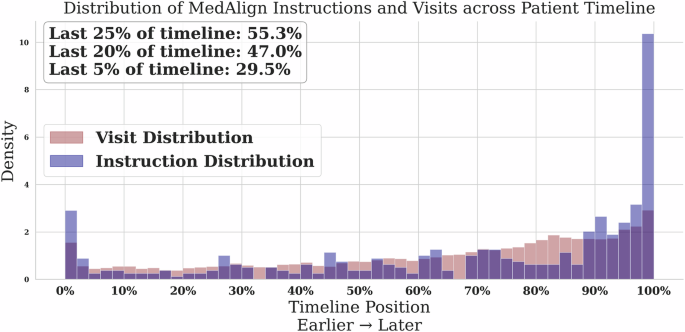
The majority of human-generated instructions focus on the most recent encounters.
When examining model-generated instructions, we observed a “lost-in-the-middle” effect regarding the parts of the patient record in which the instructions were grounded (Fig. 3). These instructions cluster at the beginning (25.9%) and end (52.1%) of patient timelines while relatively underrepresenting middle periods (22.1%). These distribution biases in both human and model-generated instructions highlight the need for a more controlled approach to both instruction generation and evaluation.
Fig. 3: Normalized temporal position of evidence in model-generated instructions reveals edge-focused attention.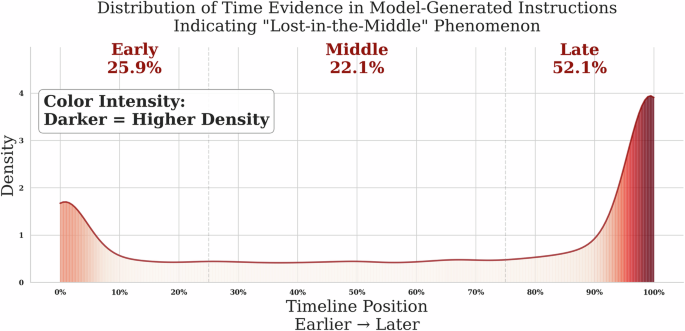
Instructions cluster around early (0–25%) and late (75–100%) parts of patient timelines.
Temporal duration vs. utilization
An important distinction emerges between the temporal duration available in clinical records and the actual temporal scope utilized in instruction generation. MedAlign’s construction involved clinicians generating instructions independently without examining specific patient records, with these instructions subsequently matched to appropriate EHR data via retrieval. The pronounced recency bias (55.3% of instructions in the final 25% of timelines) reveals that MedAlign reflects the natural recency bias inherent in clinical question formulation when clinicians pose questions independent of specific patient cases. This observation motivates the need for systematic temporal control approaches that ensure evaluation coverage across extended patient timelines.
Development of controlled temporal distribution evaluation
Our analysis of existing temporal biases necessitated a new evaluation approach that could isolate and measure the specific effects of temporal distribution on model performance. Unlike existing approaches with inherent limitations (Table 3), we developed an evaluation method incorporating multi-visit records with explicit time evidence attribution. Table 3 highlights how TIMER-Eval overcomes limitations in prior approaches. MIMIC-Instr15 is restricted to single-visit episodes with limited temporal scope (median 7.2 days), while MedAlign’s human curation leads to recency bias. Our approach enables precise assessment of temporal reasoning while maintaining scalability through controlled sampling, allowing systematic manipulation of temporal distribution patterns in both instruction tuning and evaluation.
Table 3 Comparison of EHR instructional evaluation set for medical LLMsClinician validation
To ensure the validity of the model-generated evaluation data, three clinicians assessed 100 randomly sampled instruction-response pairs generated with TIMER (Table 4). The pairs received high scores for clinical relevance (mean 95/100), temporal reasoning complexity (mean 80/100), and factual accuracy (mean 98/100), with strong inter-rater agreement. The results show high inter-rater agreement (86% clinical relevance, 93% accuracy) with low standard deviations (4.32, 1.89, respectively). Complexity scoring, being an inherently more qualitative metric, showed increased variability but remained significantly above chance (53% observed agreement vs. 12.5% random chance; std 14.87). Additional examples of where annotators agreed and disagreed on question complexity can be found in Supplementary Note 7. Disagreements primarily occurred on questions requiring temporal data retrieval with moderate synthesis, where annotators differed on whether the reasoning depth met clinical complexity standards. This variability demonstrates the rigor with which experienced clinicians evaluate temporal reasoning tasks, distinguishing between temporal mechanics and genuine clinical reasoning complexity. These validation results support the claim that our schema generates clinically meaningful evaluation scenarios.
Table 4 Clinician evaluation of TIMER evaluation samplesEffect of instruction distributions on model performance
To understand how temporal distributions affect model performance, we created three distinct distribution patterns: Recency-Focused, Edge-Focused, and Uniformly-Distributed across timelines.
Table 5 demonstrates that across all evaluation patterns, models using distribution-matched training consistently outperform alternative training approaches. The advantage of matched training ranges from +1.20% to +6.50% in head-to-head comparisons. Notably, the largest performance difference appears in the Uniformly-Distributed evaluation setting. For instance, when evaluating on Uniformly-Distributed questions, Full-Timeline training shows a +6.50% advantage over Recent-Events training, highlighting how distribution alignment affects model performance on temporal reasoning tasks. These results indicate that while general alignment between train and test distribution is helpful, it provides the most significant gains in the harder evaluation schema of Uniformly-Distributed instructions.
Table 5 Performance comparison of instruction tuning with different temporal distributionsLLM-judge and human correlation
To scale evaluation, we developed an LLM-based judge and validated it against clinician rankings for MedAlign responses. Table 6 shows a strong Spearman correlation between LLM scores and human ranks: ρ = −0.97 (average), −0.94 (correctness), and −0.89 (completeness). This inverse relationship (high LLM score = low human rank) supports that LLM-judge is a reliable proxy for human assessment in temporal reasoning evaluation. We additionally show the LLM Rank for a more direct comparison to human rank, and see general ranking trends being maintained across LLMs.
Table 6 Validation of LLM-Judge against established human rankings on MedAlignCase studies: temporal reasoning behavior
Table 7 presents qualitative examples comparing base and TIMER tuned models. TIMER-tuned models consistently show improved:
1.
Temporal boundary adherence (e.g., limiting responses to the past year),
2.
Trend detection (e.g., correctly summarizing longitudinal lab trends), and
3.
Temporal precision (e.g., associating measurements with exact dates).
Table 7 Case studies on TIMER-Eval: Comparison of model responses between base Llama-3.1-8B-Instruct and model tuned w/ TIMER-Instruct
In contrast, base models often conflate visits or provide temporally irrelevant information. Responses of models tuned with TIMER are more contextually grounded and clinically interpretable.