
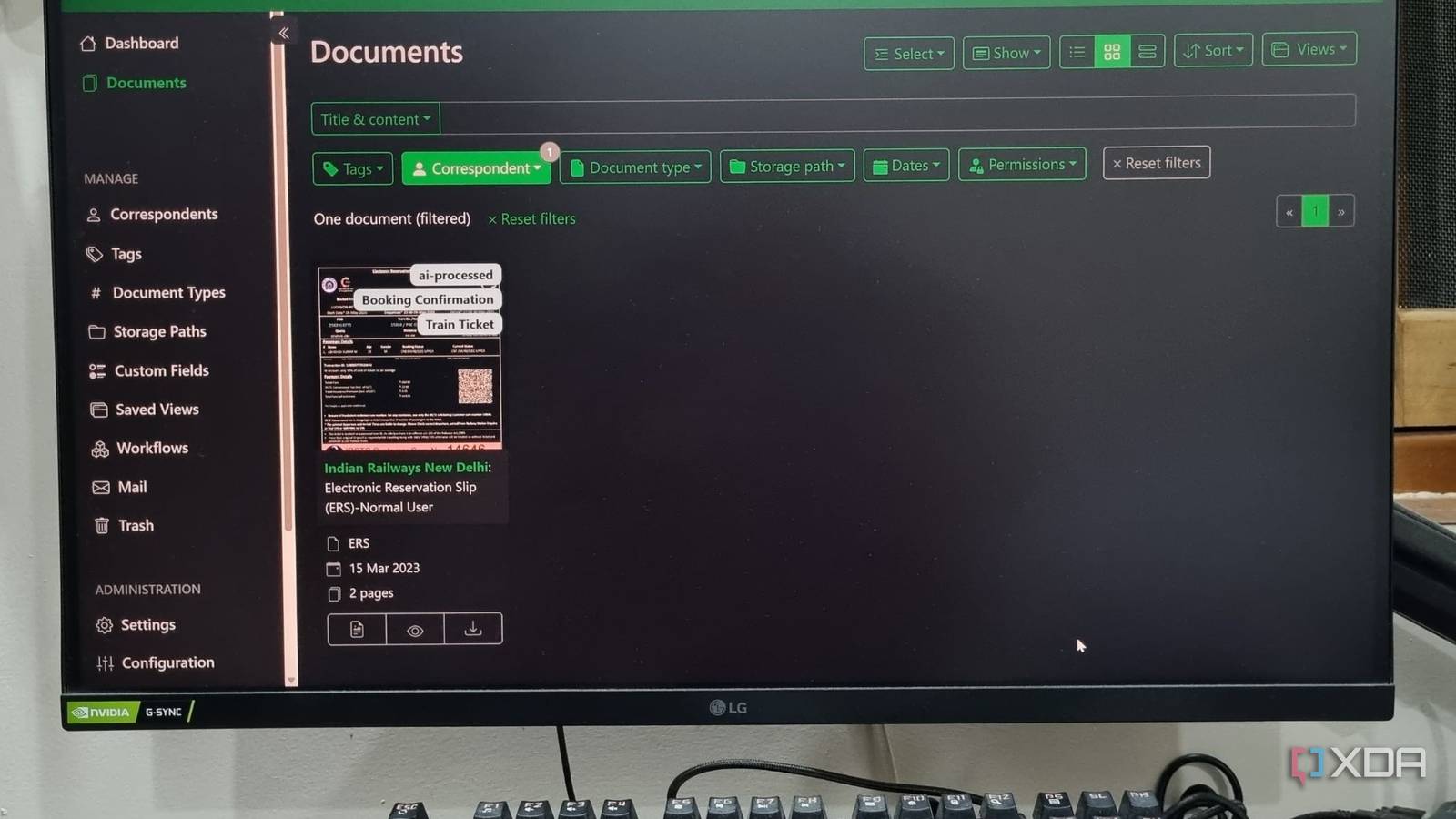
Paperless-ngx is a life-saving tool if you want to digitize and self-host all the documents, invoices, and receipts in a centralized store. I use it because I accumulate hundreds of purchases, documents, paperwork, contacts, quotations, and more in a year. While keeping a physical copy is a good practice, most of these resources exist in either image or PDF format. Paperless-ngx auto-tags documents, which makes it very easy to narrow down your search. I integrated it with Paperless AI a while ago, which utilizes a local LLM to analyze my entire collection.
My decision to add AI into the mix eliminates a lot of trouble and saves time in finding documents by name or tags. Even analyzing and extracting context from tens of pages is a relatively small task with Ollama’s LLM, and I don’t need to subscribe to an AI service to upload and analyze documents for me. Let’s examine why I made this decision and how it affects my routine workflow.
Paperless-ngx without an LLM can be overwhelming
AI put to good use
If you have been using Paperless-ngx for some time, you may have encountered the same problem I have. Tagging documents is undoubtedly the best aspect of this self-hosted app, which enhances its sorting capabilities. You no longer need to find a file just by its name or make guesses. Categories and tags do half the job for you. But when your Paperless-ngx database grows, even subcategories and tags can only help to a certain extent.
What if you want to search the complete collection for a file related to a project that you only remember by the name of a certain client or material used? It would take a few minutes to find files that way, only if you named them correctly. Otherwise, it’s a long session of opening and closing files from one category.
The second problem is that even if you find the correct file, comprehending and extracting the necessary information can consume a significant amount of time. For example, if I want to find a document related to my false ceiling work and extract the correct rate per square foot or understand the contract conditions, I have to give it a good read.
With a local LLM, Paperless AI can automatically process the entire file collection, allowing me to search for something without knowing its name. I can also select a document and then enter full AI mode to summarize it, or perform other related actions.
Multiple interaction modes
Effortless search and summarization
Paperless AI has two chat modes. I prefer the RAG chat mode slightly more because it can retrieve related documents from a single search string. Since Paperless AI supports natural language input, even a basic search query like “show me the false ceiling rates” can produce pretty accurate results.
It displays a short explanation of the document containing the file. You can also use the normal chat mode, which works on a per-file basis. Just select the file from the drop-down list, and then you can ask the AI assistant about it. It’s helpful with huge documents that aren’t easy to flash read in one go.
The single chat document is beneficial if you want to analyze and understand one document in detail. There’s also a manual mode that allows you to select a document, process it with AI, and then initiate a chat session.
Detailed dashboard and analytics
Document history and more
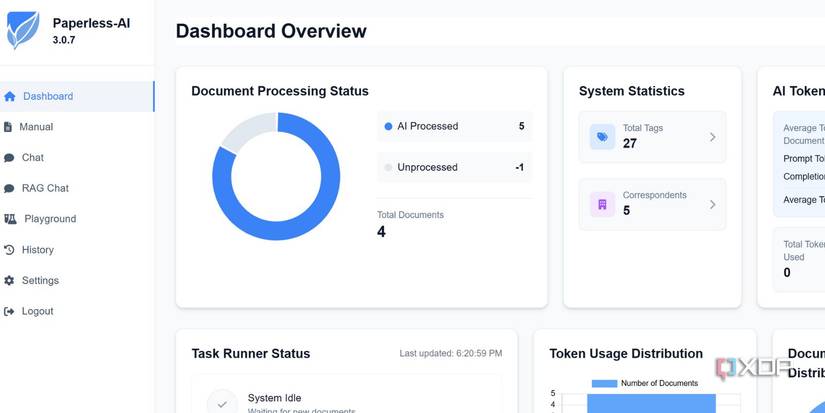
When you first set up the Paperless AI instance, it prompts you to select a default configuration. I chose to mark all the processed documents with an AI tag and then never bothered to launch Paperless-ngx web UI on my system. I instead use Paperless AI’s dashboard to get a complete overview of my processed documents.
The dashboard recognizes whenever you upload a new file to the Paperless-ngx server. It then runs the automatic AI processing on each uploaded file in the background. You can see the processing status in the dashboard and check which documents failed to process. The Task Runner status section displays the system status, providing complete details about all files.
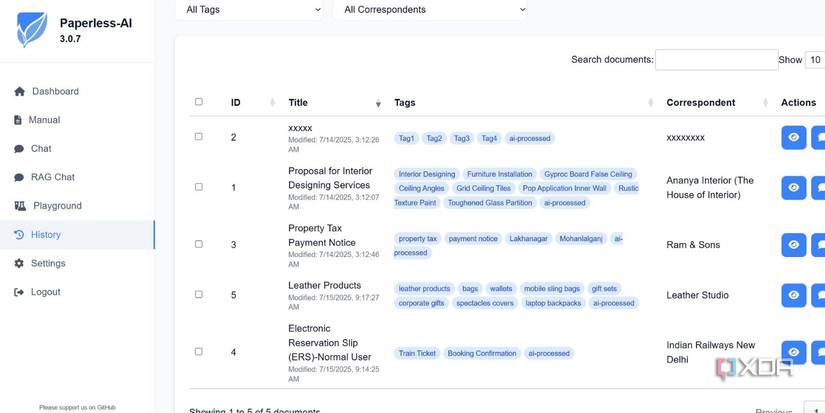
You can check the total tags, and the graphical interface is easy on the eyes with less textual information. I also use the history tab to oversee every processed document and can search for any file when required. There’s also an option to start the chat from the history window, which is helpful because there’s no search option in the single chat mode.
Local LLM can harness your system’s power
No need to pay for an API integration
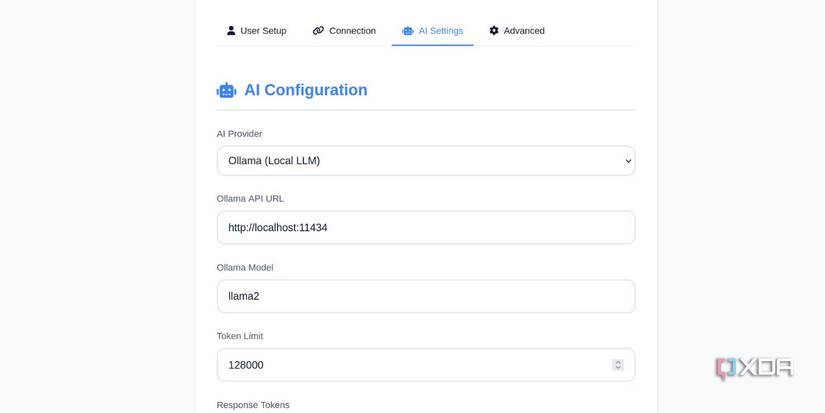
Integrating a paid API can become an expensive affair in the long run. If you have a fairly capable GPU that can run a large language model like Ollama with adequate speed, there’s no need to pay for any integration. I’ve already discussed setting up Paperless-ngx with Paperless AI, and I successfully achieved this on an Ubuntu system running on WSL 2.
My system has a mobile RTX 3060 Nvidia graphics card, and Ollama works nicely with it. The responses are fast enough, and Paperless AI doesn’t take too much time to reply to any of my queries. The automatic document processing is equally swift on my system.
Another advantage is that everything happens on your local machine. Both Paperless-ngx and Paperless AI run and process data on your system, and don’t upload it anywhere else while using Ollama. So, you don’t need to prepare for unauthorized data sharing. Even if your document library grows in the coming years, your hardware can store and process it.
There’s also less delay while using a local LLM compared to the time it takes for the query to happen via a web server and then wait for the response. You don’t need to wait for minutes before the assistant answers your question.
Get more out of Paperless-ngx
Paperless-ngx is a big deal for anyone who wants to preserve valuable documents for an extended period. Adding Paperless AI, which can use a local LLM, makes it an invaluable tool for me to sift through a huge pile of documents with ease. It doesn’t cost anything except a moderately powerful GPU, and you mustn’t ignore it.