
SPONSOR BLOG
Tightly coordinated data movement and low-latency on-chip storage for real-time environments.

The race to build smarter and faster AI chips continues to surge. This is especially true in autonomous vehicles that interpret the world in milliseconds, edge accelerators that push trillions of operations per second, hyperscale data-center processors that drive massive workloads, and next-generation consumer devices that demand ever-higher intelligence. As modern system-on-chip (SoC) architectures become increasingly complex, they produce rapidly growing volumes of on-chip data. Managing this data requires increasingly efficient movement, storage, and access. Insufficient data delivery rates create bottlenecks that restrict overall system responsiveness. Cutting-edge designs require tremendous throughput, but they often sit idle because the data arrives too slowly. The result is data starvation. This creates evaporating performance and unpredictable latency.
With system interconnects and memory hierarchies now influencing performance as much as computation itself, SoC teams increasingly rely on FlexGen and FlexNoC-optimized data transport, paired with intelligent on-chip caching, to maintain responsiveness.

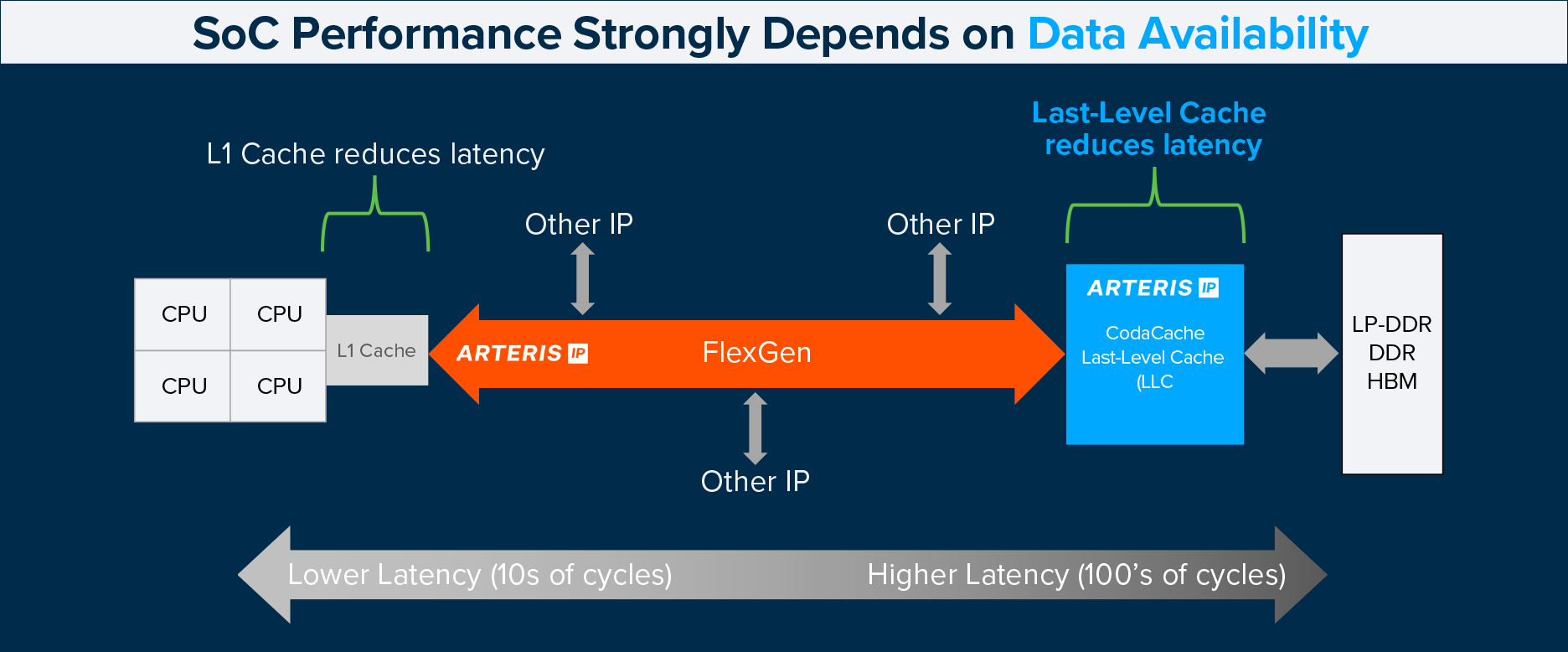
Fig. 1: The role of last-level cache in successful designs. (Source: Arteris, Inc.)
A modern LLC for a modern SoC
As these bottlenecks intensify, SoC designers are increasingly turning to on-chip memory resources to keep data close to compute. Reducing reliance on off-chip memory and minimizing wait cycles is essential to overcoming data starvation across diverse workloads. One of the most effective architectural tools for achieving this is a shared, on-chip last-level cache (LLC).
While an LLC plays a vital role in today’s SoCs, determining the correct configuration is a complex architectural challenge. For example, parameters such as the number of banks, parallel access capabilities, and partitioning strategies all influence the cache’s efficiency under real workloads.
Oversized LLCs add unnecessary silicon cost, while undersized LLCs fail to deliver meaningful benefits. Achieving the optimal balance requires detailed traffic analysis and workload simulation to ensure the cache is tailored precisely to the system’s data movement patterns.
Design teams must consider:
Capacity is sized to provide enough on-chip storage for critical data while staying within area and frequency constraints.
Hit-and-miss behavior depends on how the cache is organized and sized, influencing how effectively data is retained close to the compute.
Eviction behavior must align with workload characteristics so that frequently reused data remains resident while less valuable lines are replaced efficiently.
The choice between scratchpad and cache operation affects determinism and flexibility, requiring a balance between software-managed control and hardware-managed transparency.
Parallelism requirements depend on the number of simultaneous accesses the design must support, driving decisions about banking, ports, and internal concurrency.
Fairness and quality of service considerations ensure that multiple requestors receive predictable access to shared resources without starving lower-priority clients.
An essential ingredient in today’s SoCs
Arteris is uniquely qualified to address these limitations because data movement is the company’s core expertise. Leveraging this foundation, the company created CodaCache to mitigate the widening gap between rapidly advancing processors and comparatively slow main-memory access. By storing relevant in-flight data on-chip and coordinating efficiently with external DRAM, it provides a high-bandwidth, power-efficient reservoir that keeps critical data close to compute.
When paired with FlexGen, FlexNoC, CodaCache complements the interconnect’s ability to route traffic efficiently across heterogeneous systems:
DRAM accesses—often hundreds of cycles long—are dramatically reduced through higher hit rates, lower latency, and improved bandwidth utilization.
FlexGen and FlexNoC’s topology-aware routing ensures low-contention access paths into CodaCache, improving average-latency behavior across varied workloads.
System simulations from the pairing show:
Significant latency reductionas hit rates increase, with even moderate hit rates (25%) providing ~13% latency benefit over DRAM-only flows.
DDR traffic reduction of up to 25–30%, lowering power and improving efficiency.
Improved bandwidth, especially when short bursts benefit from CodaCache prefetch behavior.
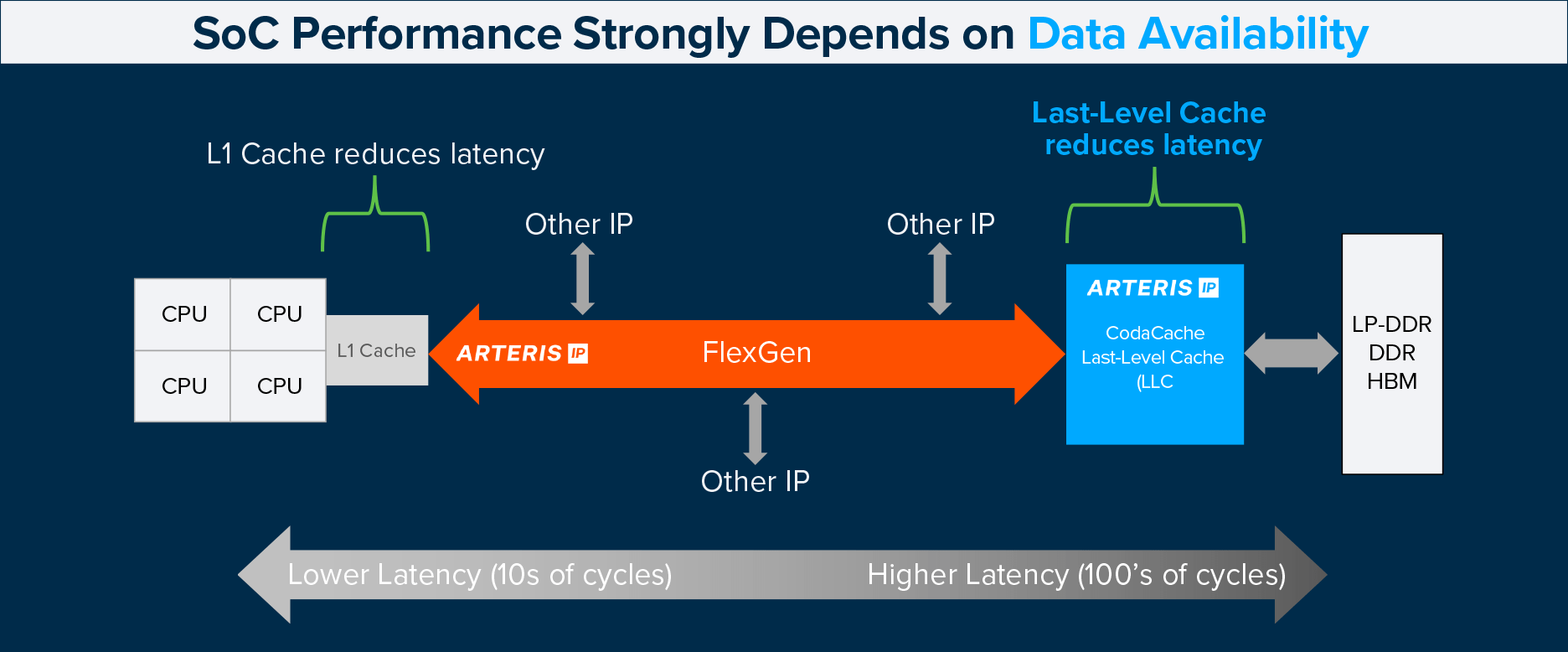
Fig. 2: SoC performance is dependent upon data availability. (Source: Arteris, Inc.)
CodaCache is designed for seamless integration into heterogeneous network-on-chip architectures, delivering a well-balanced combination of capabilities.
Large capacity for storing high-value data, supports multi-instantiation and up to 8 MB per AXI port, with configurable cache-line size, associativity, and cache-organization so that it can be sized appropriately for different SoC workloads.
Shared accessibility for multiple compute engines by providing a shared LLC that multiple processors and accelerators can access, with flexible partitioning to support either shared or isolated usage while reducing external memory traffic.
Significantly reduced latency and power consumption by keeping frequently accessed data on-chip, and improving overall system responsiveness.
The result is a subsystem that meaningfully boosts performance across advanced AI compute markets.
As SoC architectures become increasingly complex, with growing numbers of cores, accelerators, concurrent workloads, and chiplets, the need for intelligent, scalable, and automated data management infrastructure continues to grow.
It is no longer enough to build faster compute engines. Designers must feed them efficiently. The combination of FlexGen/FlexNoC and CodaCache represents a new class of system IP that acknowledges this shift, delivering tightly coordinated data movement and low-latency on-chip storage for demanding real-time environments.
Arteris CodaCache represents a new class of system IP that recognizes this shift in demanding real-time environments.
André Bonnardot (all posts)
André Bonnardot is Senior Manager of Product Management at Arteris, where he leads Cache Controller solutions and next-generation Network-on-Chip products. Formerly CEO of a semiconductor startup specializing in GaN epitaxy, he brings deep expertise in SoCs and microelectronics. His career includes design and leadership roles at Alcatel, Siemens, Infineon, and Intel. Bonnardot holds a master’s degree in Electronics from ENSERG Engineering School in Grenoble and an Executive MBA from KEDGE Business School.