
Key Takeaways:
NoC challenges, such as wiring congestion, timing closure, and performance, must be considered in tandem with topology and placement.
Topologies can be customized to meet an application’s specific data flow needs, with a system containing multiple topologies to suit different data or zones.
What is challenging for one type of system, such as an SoC, switch, or AI chip, may not be a consideration in another, and chiplets pile on complications.
Today’s on-chip networks are much like a complicated freeway intersection with multiple on-ramps and off-ramps leading to smaller highways. The traffic is data, and more of it is being captured, generated, and analyzed than ever before.
Real-time AI-driven analytics put extra pressure on chip networks that need to quickly shuffle data back and forth between processors and memory. To meet the task, designers are coming up with new and increasingly complex network on chip (NoC) topologies and inter-die fabrics to get everything where it needs to go at exactly the right time. But that also raises some new challenges.
“This space is growing because we have a lot of data,” said Priyank Shukla, director of product management for interface IP at Synopsys. “This is leading to new technologies to connect that data in and out of an accelerator going to the memory, for example, and that’s spurring innovation in our field.”
The architectural challenges are weighted differently, depending on whether designers are dealing with systems-on-chip (SoCs), multi-die systems, or chiplets, but there are some common concerns for all configurations.
“The hardest problems are scalability, congestion management, traffic fairness, latency predictability, and achieving timing closure across increasingly heterogeneous IP blocks,” said William Wang, CEO of ChipAgents.
From an SoC fabric perspective, the most complex problems all scale together. “That’s what makes them hard,” said Andy Nightingale, vice president of product management and marketing at Arteris. “As SoCs grow into hundreds or thousands of endpoints, you’re no longer just connecting blocks. You’re managing a living traffic system under tight power, latency, and floorplan constraints. Wiring congestion, timing closure, and performance are inseparable from topology and placement. Cache coherency and traffic ordering directly affect QoS (quality of service) and worst-case latency. Heterogeneous integration — of CPUs, GPUs, NPUs, accelerators, and chiplets — multiplies clock, power, and protocol domains.”
AI designs compound some of these challenges. “The fabric must absorb bursty, high-fan-in traffic without collapsing into head-of-line blocking or pathological congestion,” said Nightingale. “That’s why modern NoCs have evolved well beyond simple crossbars or rings. The fabric has to be architected as a scalable system, not treated as glue logic after the real IP is finished.”
Each problem and solution impacts another, requiring tradeoffs. “For example, if you increase layering density, that gives you better performance, but it makes your physical design more difficult,” said Kent Orthner, principal solutions architect at Baya Systems. “One problem stands out — not necessarily as the most difficult, but as maybe a solution to the others — and that’s heterogeneity.”
Because of silicon scaling issues at the leading edge, engineers are customizing network solutions for the end application rather than building general-purpose solutions.
“Although there are a lot of difficulties, a lot of it is helped by the fact that you’re doing heterogeneous design, which means that you’re not trying to do everything the same way,” said Orthner. “You’re coming up with different types of processors, and different types of compute, and different types of networks and topologies, maybe all within a single SoC to solve different flavors of problems.”
While heterogeneity solves some problems, it also creates integration challenges. “Most organizations are layering AI accelerators and real-time control workloads onto legacy platforms never designed for this level of heterogeneity or concurrency,” said Nightingale. “That’s driving a shift toward treating the on-chip interconnect as a real-time system fabric rather than a passive transport. Early architectural exploration, physically aware automation, and policy-driven data routing are being utilized to manage the growing data volumes while maintaining predictability and security.”
Different topologies for different challenges
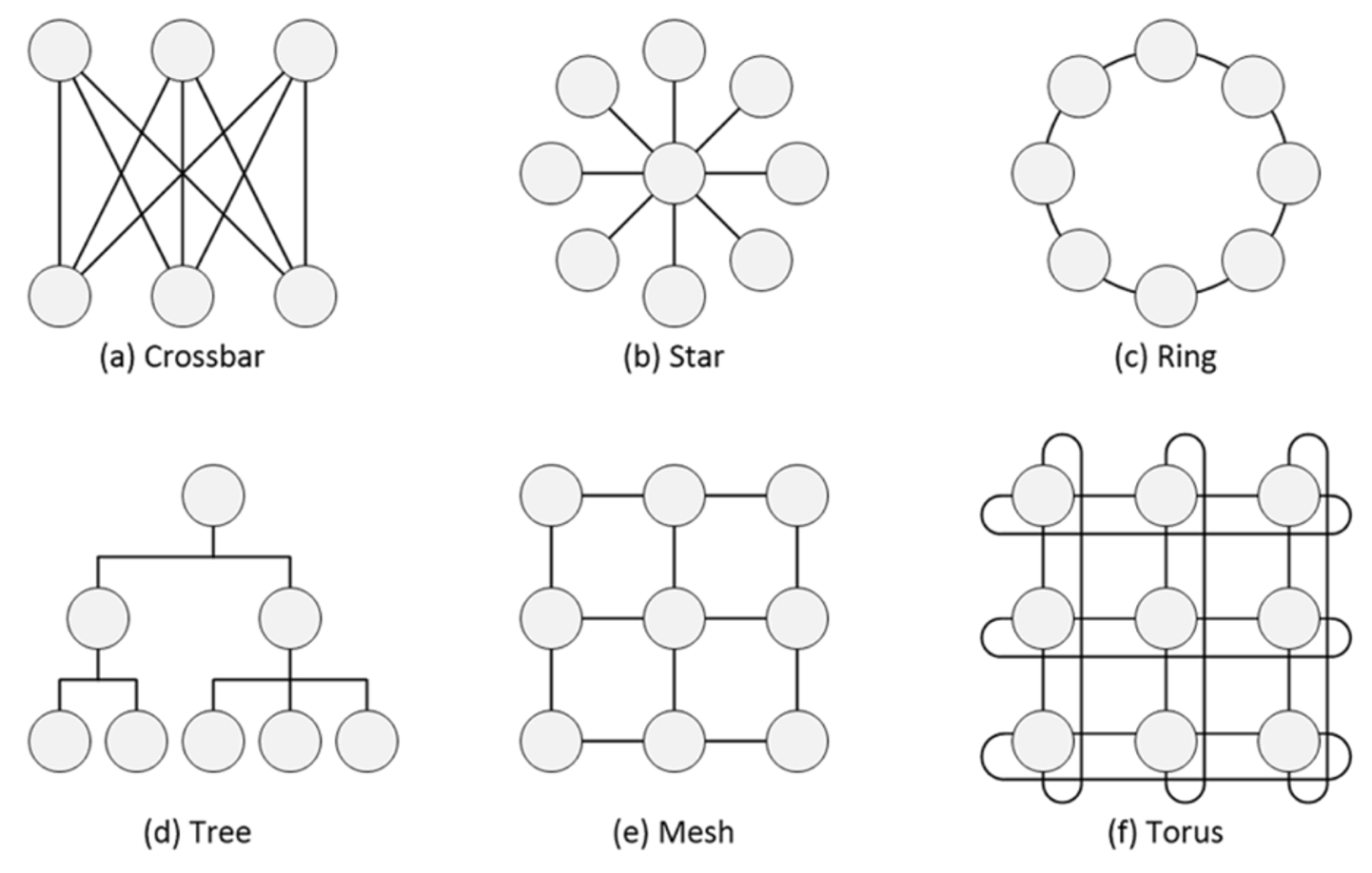
To meet changing data needs, NoC topologies have evolved from crossbar to star, ringtree, mesh, Torus, and other newer formations. A complex system can have multiple NoCs in a range of different topologies.
“We see hybrid fabrics mixing mesh, Torus, and hierarchical clusters with soft-tiled domains, configurable coherency islands, and adaptive routing to balance bandwidth and power,” said ChipAgents’ Wang. “In the near future, we expect dynamic, self-optimizing fabrics with agent-driven traffic tuning, congestion forecasting, and runtime topology morphing based on workload patterns.”
Others agree that the next topologies are hybrids with more hierarchy and adaptivity. “Future fabrics will look less like a single named shape and more like a composed system — optimized locally, coordinated globally — designed to evolve with packaging, chiplets, and AI workloads rather than fight them,” said Arteris’ Nightingale. “The mission objective is to make the fabric disappear as a problem, even as the chip keeps getting bigger.”
Fig. 1: Traditional SoC interconnect fabrics. Source: Arteris
The latest approaches are explicitly multi-dimensional. “We support different topologies — trees, meshes, hybrids, and domain-specific fabrics — used simultaneously within the same SoC, because no single topology is optimal everywhere,” Nightingale observed. “Coherent fabrics are essential for CPU clusters, where software consistency, shared memory, and fine-grained synchronization dominate. Non-coherent fabrics are often the preferred choice for NPUs, DSPs, and streaming accelerators, where bandwidth, determinism, and energy efficiency matter more than global coherency. Soft tiling and hierarchical fabrics allow designers to scale capacity and bandwidth while containing timing, and wiring complexity. System-level traffic management, consisting of virtual networks, QoS, isolation, and congestion awareness, ensures that one aggressive workload doesn’t poison the rest of the chip. The goal isn’t theoretical elegance — it’s predictable behavior at scale, even when traffic patterns are ugly.”
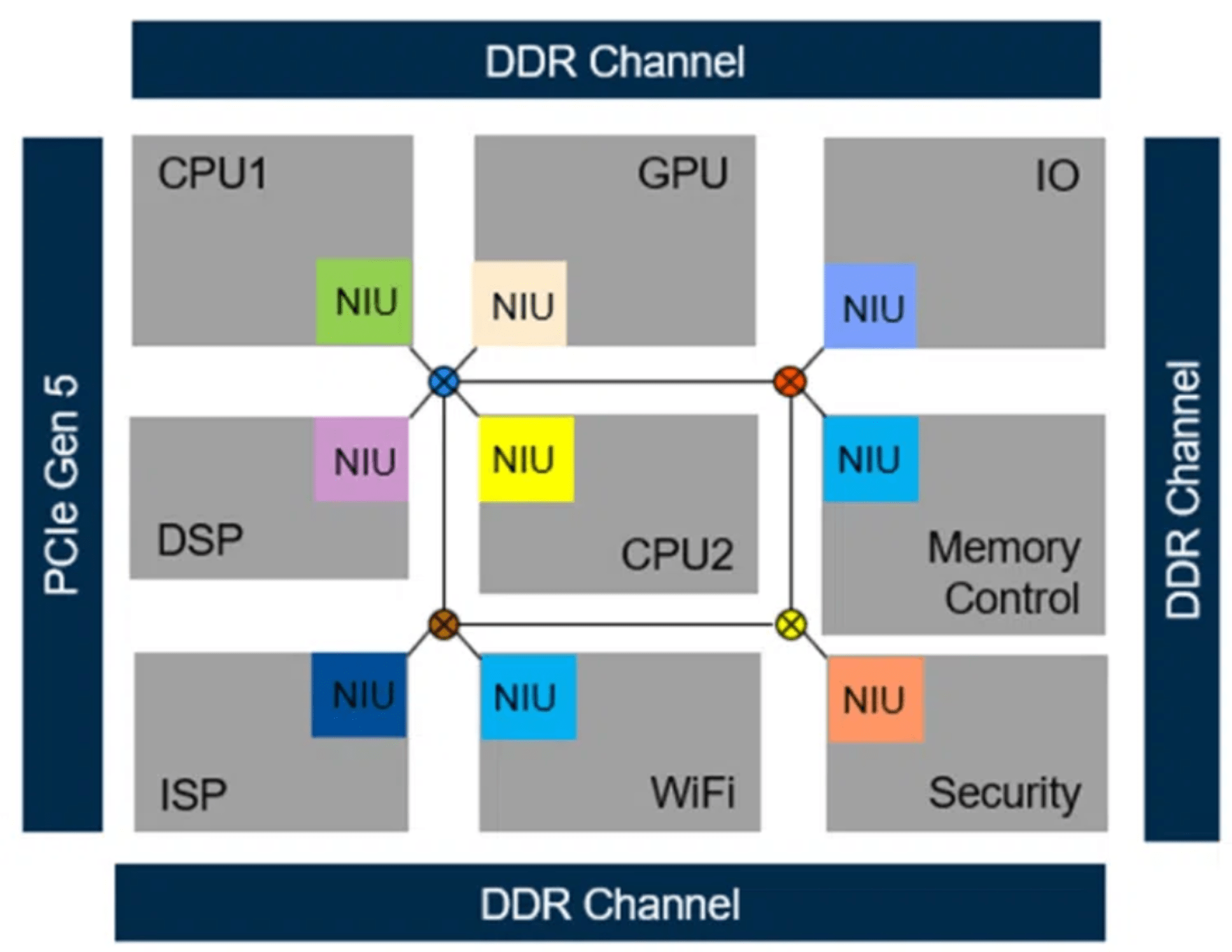
Fig. 2: NoC tiles for AI/ML with network interface units (NIUs), presented at the register transfer level (RTL). Source: Arteris
However, new problems need new topologies. “One of the key things that we are trying to solve within a 2D space on-die is whether we can come up with fundamentally new topologies that have never been invented before,” said Saurabh Gayen, chief solutions architect at Baya Systems. “How do we do very algorithmic, software-based hardware design, which is a top-down view of things? You holistically look at the system, you figure out, ‘What do I want my entire thing to look like?’ But then you look at the bottom up, because this actually needs to be built in the end. So then, what are the component pieces that you must have? A software-defined flow takes advantage of tools that were not available before. We were able to internally use those exploration tools to come up with fundamentally new topologies, which can do a 3D type of architecture within a 2D chip.”

Fig. 3: A 3D architecture within a 2D chip. Source: Baya Systems
Further, some types of ICs are suited to one specific topology. “The only topology that works for a switch — for example, an Ethernet switch that all these big guys are building — is a crossbar,” said Gayen. “The problem with crossbars is that they’re so bad at scaling. A crossbar that has a large number of ports on a switch is incredibly expensive and incredibly complex.”
Other chips may benefit from a custom solution. “If you’re doing machine learning inference, there are very specific data patterns that you’re going to see again and again, and you can design the network to support that,” Orthner explained. “We encourage a definition of the topology specifically for the application. Imagine you’ve got a bunch of high-performance computing cores in a corner somewhere. You might have a topology that supports a lot of connectivity in that corner. But as you do your network configuration, it might be much more linear because you don’t have the same constraints. It starts to become a custom topology for every design, instead of a specific term like a mesh or a Torus. We are seeing an interesting class of designs.”
Choices come down to the provider and how they’ve chosen to optimize their system. “AHB (advanced high-performance bus) was one of the first networks-on-chip, a parallel bus,” said Mick Posner, senior product marketing group director for chiplets and IP solutions at Cadence. “AXI (advanced eXtensible interface) came next, and it was point-to-point, lots and lots of wires, which was great for performance — but not when you are spanning a whole monolithic die, for example. Having that many parallel wires going across became problematic, and that’s where you ended up with a true network-on-chip, which was more serial connections, minimal wires going across the NoC. And then those have been extended to go first, chip-to-chip, and now are being tailored for die-to-die. That topology is based on an architectural-level choice. You can mix and match. It is still typical today to have, say, a new NoC with something like an AHB port that drives into an AHB NoC with standard APB (advanced peripheral bus) peripherals, on low speed. I ran the AMBA (advanced microcontroller bus architecture) peripherals [while at Synopsys], and what was amazing is that, after 30 years, I found out that the whole product line was still alive. What I drove 20-plus years back was just getting adopted.”
Different chips, different problems
All NoCs are fabrics, but not all fabrics are NoCs, and the full range of technologies is needed to meet different chip challenges.
“Fabric is a generic term,” said Synopsys’ Shukla. “There is FPGA fabric, then you have on-chip fabric, then you have network fabric. When you talk about hyperscalers, they call the whole plane a fabric. They mean a rack of accelerators is a fabric. So how do they talk with each other?”
Multi-chip design discussions are often around the network. “What most people think of when they talk about networks is this picture of GPUs, CPUs, and a data center, and there are wires connecting between them,” said Baya’s Gayen.
On-chip networks also have cores, memory, and accelerators, which need to talk to each other, but, unlike a data center, there aren’t cables. “You don’t have a 3D space,” Gayen explained. “You have a 2D space, so the topology there is typically something that you can layer within that space and get really good performance without being able to overlay the cables that you have in a 3D data center space. Even though it’s a very common networking theory that underlies both, it’s very interesting to see how those things diverge and how the problem-solving happens.”
Fast-growing application areas like physical AI systems, including robots, drones, or vehicles, also have distinct concerns. “Physical AI systems operate in continuous, closed-loop interaction with the real world — combining sensing, computation, and actuation under strict real-time and safety constraints,” said Nightingale. “In these systems, delayed or misrouted data isn’t only inefficient but also potentially unsafe. Data management, therefore, expands to include deterministic latency, traffic isolation, and fault containment, ensuring that safety-critical control flows are protected from best-effort AI traffic and that data leakage or bias introduced by uneven access is avoided.”
What is a big networking challenge in one domain of chips is not necessarily challenging in another. For example, coherence applies to some systems but not others.
“With more and more complex SoCs, the coherency side of things is a real challenge to deal with,” said Gayen. “In an SoC, the performance is often limited by having to coordinate all that nitty-gritty stuff about coherency. That really takes you back, and you can’t reach crazy levels of performance.”
AI chips sidestep the coherency problem. “They don’t have built-in coherency protocols, so that’s not the challenge for them, because they handle it through software-based coherency or an algorithmic approach to data flow,” Gayen said. “There, the challenge is how to balance a good ratio of really good NoC performance, versus how much I’m allocating to compute or buffering.”
Switches are in a completely different domain, where they’re pushing the physical limits. “They’re just trying to figure out how to cram as many wires as possible in a way that an engineering team can actually handle and build,” he continued. “Their big problem is how to get an incredibly crazy type of performance. The switches care about the non-blocking property and throwing more white space and wiring at the problem, but having way more stringent performance requirements. The wire density aspect becomes critical. The engineering cost of tiling and having such a big NoC design, or a big crossbar design, is the challenge.”
Since AI chips sit in the middle of a complex SoC and a switch, they are not doing hardware-based coherency as much, and are not doing full-on white space, throwing a bunch of wires at a huge performance problem. “They want something that kind of looks like an SoC, but kind of looks like a switch, as well. They might take an SoC-type design but then scale it by having way more parallel layers of wiring that can distribute and get 2X, 4X, 8X the bandwidth, but really go for raw performance compared to what an SoC does,” Gayen said.
Also, there is a common thread between the domains — the insatiable thirst for data. “Everybody wants to get their data moved around more efficiently,” Orthner said.
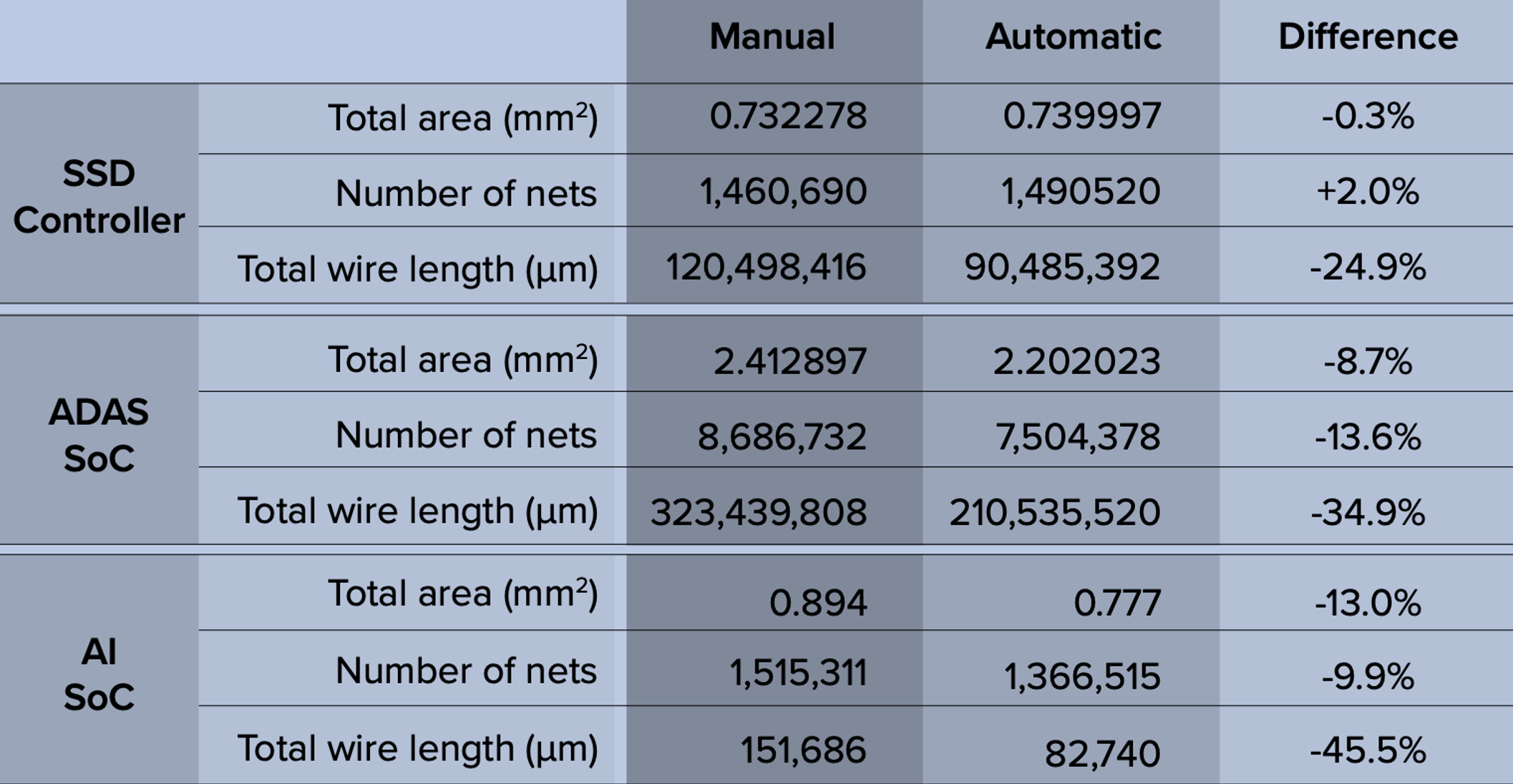
Fig. 4: Comparison of expert users (manual) vs. NoC IP (automatic) for real-world designs. Source: Arteris
Chiplet challenges
Like SoCs, chiplet NoCs require decisions around coherency. Within a chiplet, individual subsystems act as the function. “It could be the memory LPDDR subsystem or a PCIe subsystem, but each of those subsystems has its own NoC to facilitate the communication within that subsystem,” said Cadence’s Posner. “Then there could be a higher-level NoC that allows subsystems to talk to subsystems. In that scenario, our chiplet was non-coherent. It did not require any cache coherency, which is required if it were a CPU-to-CPU connection. The CPU provider will always have a coherent NoC. Then there are third-party options that offer coherent and non-coherent NoCs. It’s down to what you are connecting to. If you’re designing a CPU chiplet, then you must have a coherent NoC, because you’re likely going to be performance scaling by putting down multiple dies of that same thing, and you’re doing CPU scaling. That has to have cache coherency. But if you’re going from CPU to an accelerator, then it’s usually just I/O coherency you need. That also drives the type of NoC that is used.”
Chiplets add more data challenges. “In the system, especially with the high speed I/Os, you have to think about how you’re going to manage the communications between the other chips,” said Hee Soo Lee, high-speed digital design segment lead at Keysight EDA. “When we are thinking about data, all of these tiny chiplets are connected. How are you going to maintain really good bandwidth requirements, along with how you manage the latencies between chips, especially with all of those tiny pieces of chiplets? Data is one of the main issues and problems. In delivering all the power to those chips, are you going to make data cleaner? You need to make sure there are signals throughout the I/O wide buses so they don’t interfere with each other and don’t result in a closed eye or shrunken margins for the system. Just making everything stay cool is also very, very challenging.”
I/O chiplets bring further considerations. “If you’re splitting your core die with I/O die, should you share the fabric, or should the SoC have the fabric and the I/O die just pass on data?” Shukla noted.
Overall, the chiplet approach is more complicated because it leads to bigger overall systems. “The sheer scale of what you can build when you put multiple chiplets together just grows and grows,” said Baya’s Orthner. “Also, there’s a degree of runtime configurability that pops up when you’re working with chiplets that you don’t see so much in a straight-up SoC.”
Conclusion
NoC and fabric designers have a lot to consider in today’s landscape, with the ever-increasing demands of AI leading to more data, and more traffic congestion.
A key shift is that AI workloads have invalidated “average-case” assumptions. “Training stresses sustained bandwidth, multicast efficiency, and memory coherence at massive scale,” Arteris’ Nightingale said. “Inference — particularly at the edge — demands bounded, predictable latency. In both cases, data quality and correctness are no longer purely software problems. When memory traffic can consume 80% to 90% of inference time or dynamic energy, congestion, timing variability, or silent data corruption directly impact model behavior and system outcomes.”
Finally, the impact of network problems and data bottlenecks is becoming more critical. “As AI evolves from digital inference into physical, real-world interaction, data management failures no longer degrade performance gracefully,” Nightingale said. “They surface as accuracy loss, safety risk, or unscalable systems. Designing for deterministic, observable, and adaptable data movement is no longer optional — it’s foundational. Efficiency follows discipline.”
Related Articles
UCIe’s Major Technical Components Are Now In Place
Version 3.0 of the interconnect standard doubles bandwidth and supports new use cases and enhanced manageability.
Multiple AI Scale-Up Options Emerge
As data center infrastructures adapt to evolving workloads, parts of Ethernet can be found in scale-up approaches.
Often Overlooked, PHYs Are Essential To High-Speed Data Movement
From smartphones to AI factories, physical layers are the unsung heroes of data communications.
Die-To-Die Interconnect Standards In Flux
Many features of UCIe 2.0 seen as “heavy” are optional, causing confusion.