
Local AI coding models have been growing in popularity, and for good reason. Between Qwen3 Coder Next, Devstral 2, gpt-oss-120b, and a wave of smaller fine-tuned models, the pitch is that you can run a legitimate coding assistant on your own hardware, without a cloud subscription. I’ve been running local models for a while now, and I genuinely believe they’ve reached a point where they’re useful for real work. But “useful” is a wide spectrum; reverse engineering and static analysis is something I find them useful for, but what about good old coding? I wanted to find where some of the most popular models fall on that spectrum… so I designed a test.
I put together a single prompt, which I gave to five separate models running on the Lenovo ThinkStation PGX. These five models were:
Qwen3-Coder-Next (80B MoE, 3B active)
Qwen3.5-122B-A10B (122B MoE, 10B active)
Devstral 2 123B (123B dense model)
gpt-oss-120b (117B MoE, 5.1B active)
Omnicoder-9B (9B dense model)
With the exception of Devstral 2 123B, all of these models can be run on your own hardware if you have enough RAM and a decent enough GPU. For example, gpt-oss-120b can run on an RTX 4090 with 64GB of system RAM, and you can achieve similar with the other Mixture of Experts-based models used in this test. Omnicoder 9B, though, is a model that comes in at just shy of 5GB when quantized to 4-bits, which was an intentional choice to show what a smaller model that could run on something like a laptop can do as well.
There was no hand-holding (aside from the occasional prod to “continue”), and for the second test, I then gave each model the same test, but with an instruction to use Context7.
This is the exact prompt that I gave the models:
Build a CLI static site generator in Python. It should take a directory of Markdown files with YAML frontmatter (title, date, tags), convert them to HTML using a simple template, generate an index page sorted by date, and output everything to a _site/ directory. Include a –watch flag that rebuilds when files change. Use only the standard library plus markdown and pyyaml. Write tests for the frontmatter parser and the index generation. The project structure should be clean — separate modules for parsing, templating, and file watching.
I designed this test to be simple enough to be a realistic ask, while also being complex enough to expose real weaknesses. YAML has a few different potential hurdles, and the request to only use the standard library alongside markdown and pyyaml meant that it couldn’t use the watchdog library to check for file changes. I used OpenCode as the harness for all of these models. For the second test, the only addition to the above prompt was “Use context7” at the end.
It’s important to be aware that these models are inherently stochastic. That means that subsequent runs will not give the same results, and a model might fare better on a third, fourth, or even fifth pass. But some of the decisions made by these models indicate that it’s unlikely subsequent tests would give much improved results. You could potentially improve them by holding their hand a lot more throughout a project, but when you don’t need to do that for a cloud model, it can be frustrating to have to do it constantly for a local one.

![]()
9/10
Brand
Lenovo
Storage
1TB/4TB
CPU
Nvidia GB10
Memory
128 GB
The Lenovo Thinkstation PGX is a mini PC powered by Nvidia’s GB10 Grace Blackwell Superchip. It has 128 GB of VRAM for local AI workloads, and can be used for quantization, fine-tuning and all things CUDA.
Two models pulled clearly ahead of the pack
And one of them did it in five minutes
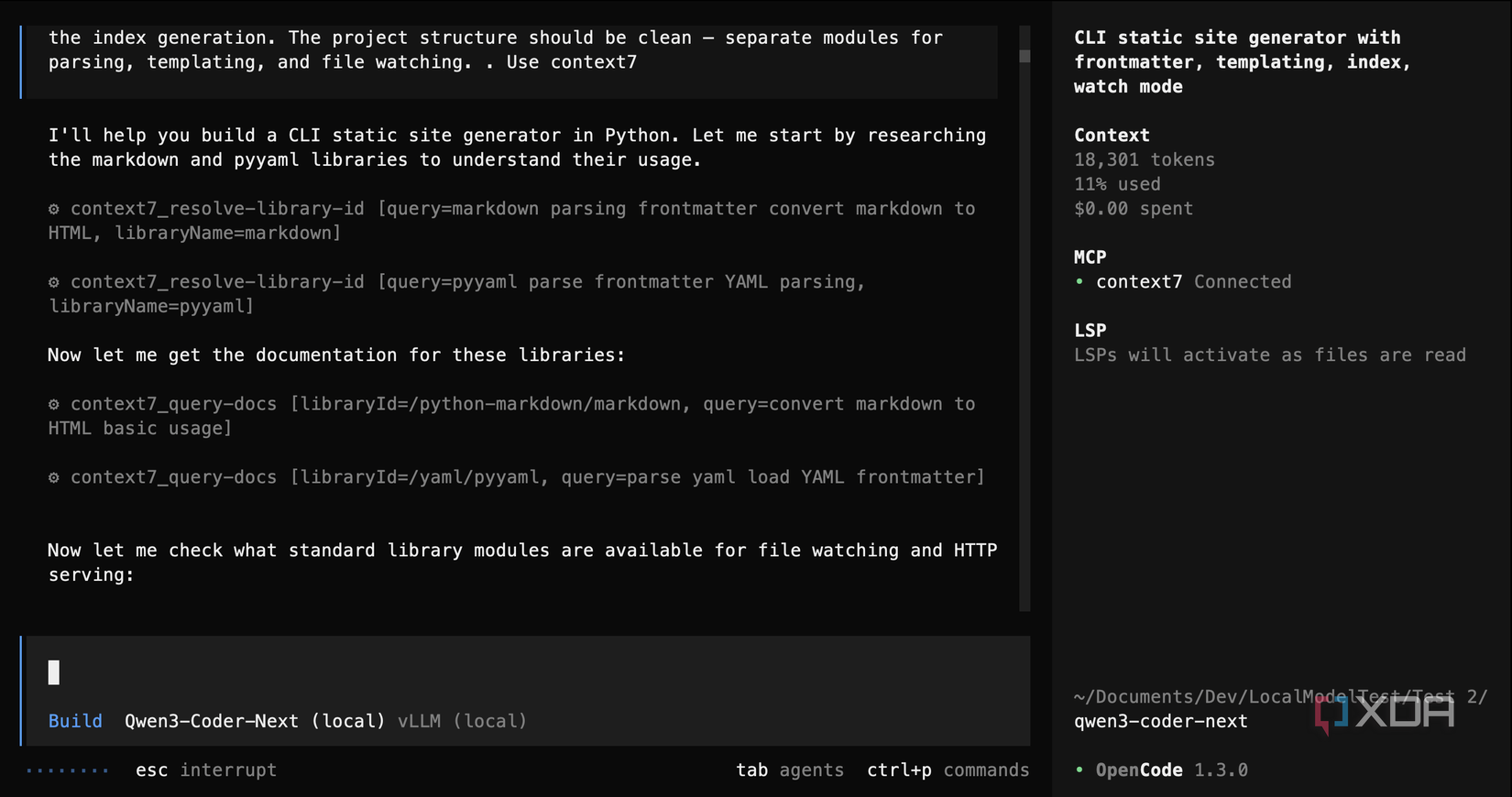
Qwen3 Coder Next was the standout of all of these tests. In the first test, without Context7, it produced a clean project with a proper “src/” layout, class-based architecture, a polling-based file watcher, and 14 passing tests. It took about 32 minutes and required five debugging rounds, mostly spent wrestling with a PyYAML edge case I’ll get to later. That’s a solid result from raw model knowledge alone.
In the second test, with Context7 available, it was a different story: Qwen3 Coder Next actually used it. It resolved library IDs for both markdown and pyyaml, pulled the documentation, and got to work. It completed the task in 17 minutes instead of 32, made 16 passing tests instead of 14, required less debugging, and it even added bonus features like a built-in HTTP dev server and styled HTML output. It nearly halved its completion time while producing a better result overall. It worked perfectly.
gpt-oss-120b, OpenAI’s open-weight model, was incredibly quick. It finished the first test in under five minutes at roughly 72 tokens per second, which is absurd. The output was a clean modular structure with separate parser, templater, generator, and watcher modules. The architecture was sound, but it left bugs behind: a missing Dict import in the watcher that would crash at runtime, and Jinja2 artifacts left in the HTML templates. The second test using Context7 was similar, as it had slightly better architecture and slightly fewer leftovers like those. However, it called Context7’s resolve-library-id for both libraries, got the IDs back, then decided it already knew enough and never actually read the documentation. It was fast and it was confident, but it didn’t nail it in the way that Qwen3 Coder Next did.
Between the two, Qwen3 Coder Next wins on quality and gpt-oss-120b wins on speed. If you need a first draft in five minutes and plan to review it yourself, gpt-oss-120b is genuinely impressive. If you want something that runs correctly the first time, Qwen3 Coder Next is the better bet.
The other three models tell a different story
Capable on paper, messy in practice
Devstral 2 123B, Mistral’s coding model, put in a strong first performance with a pretty great package structure, eight passing tests, and styled HTML output in just over 40 minutes. The catch is that it used watchdog for file watching, which explicitly violated the spec’s standard-library constraint. In the second test, things got worse. It took almost twice as long, produced a flat script with only four tests that couldn’t run due to import path issues, and completely ignored the instruction to use Context7. It didn’t even attempt to call it. Devstral 2 was clearly better when left to its own devices, and the added complexity of an instruction to use Context7 seemed to trip it up rather than help it.
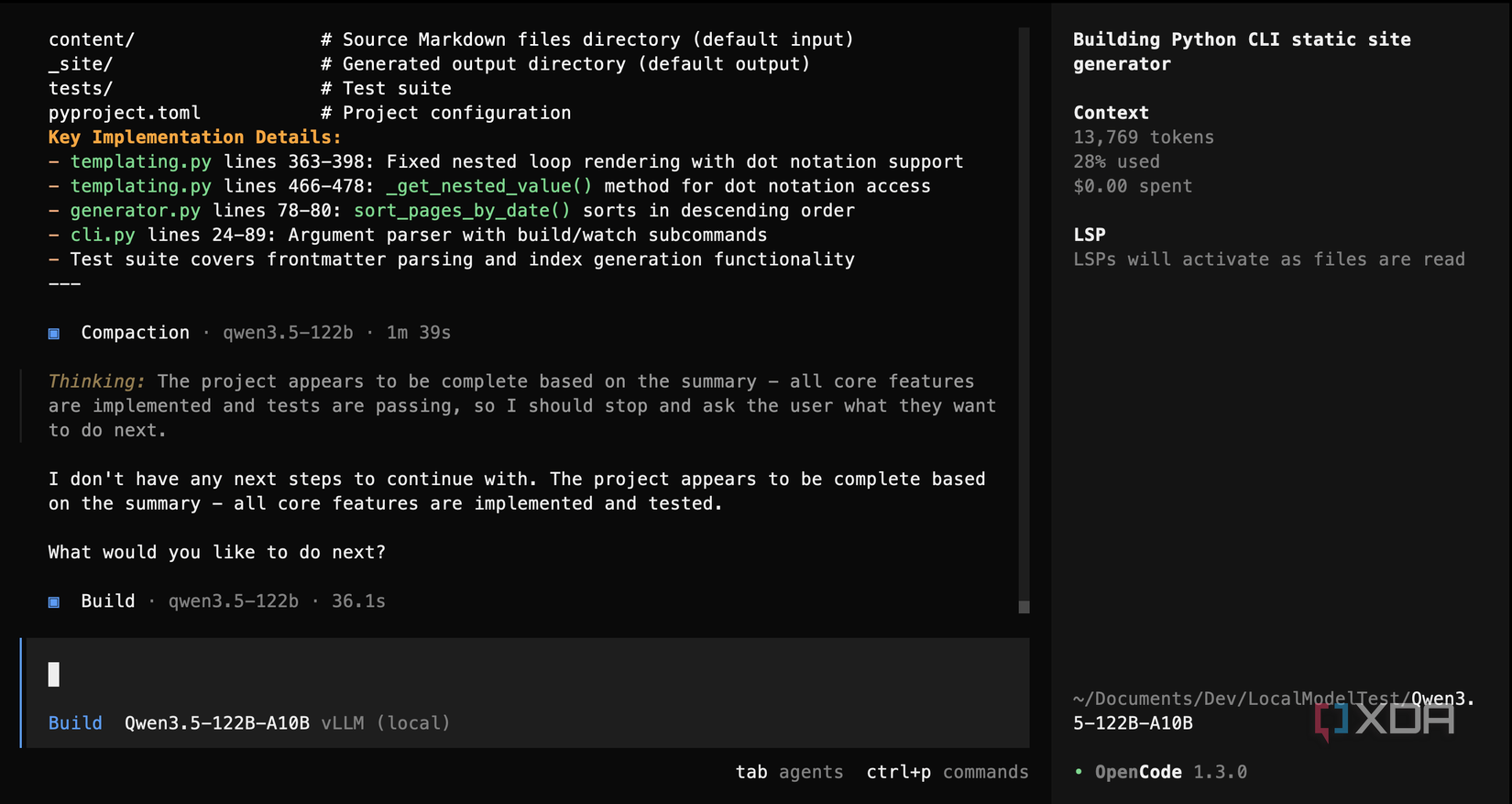
Qwen3.5 122B A10B was the most ambitious model in the group, but that’s not always a good thing. In the first test, it built a custom template engine from scratch, with an almost-600-line file supporting variable interpolation, for loops, if statements, and dot notation. It’s ridiculous, and it’s the very definition of overengineering. It created 20 passing tests, which would be the most of any model, except for the fact that the application didn’t actually work properly. Plus, by the time context was compacted mid-session after reaching its allotment of 70,000 tokens, the model seemed confused about what it had already built.
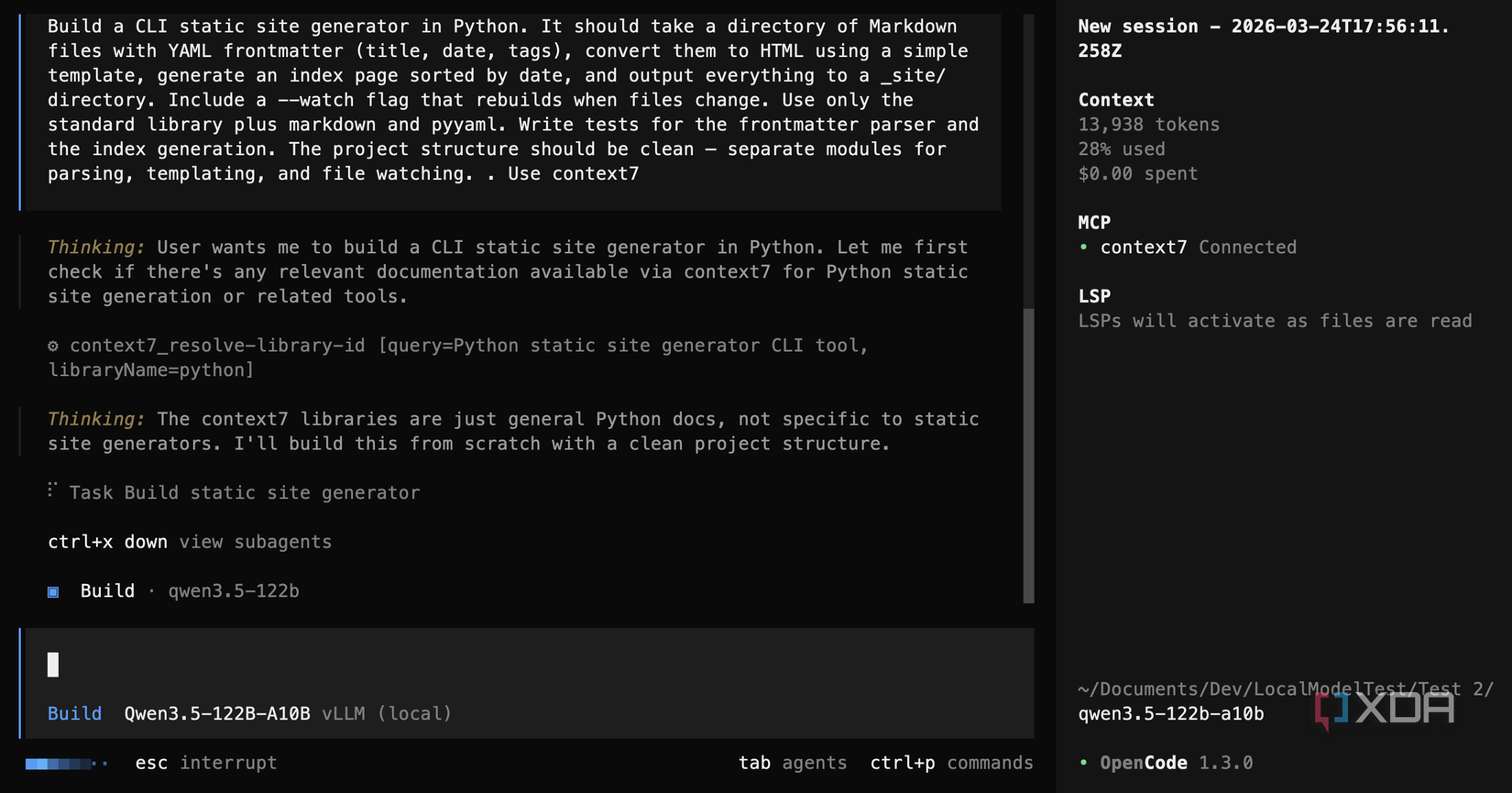
The second test was worse for Qwen3.5 122B A10B: it misused Context7 by searching for generic “Python” documentation instead of looking up markdown or pyyaml, got back CPython docs, dismissed them as irrelevant, and gave up. The code it produced had a function referenced in the generator that was never defined in the templating module, and templates written in Jinja2 syntax that its own custom engine couldn’t process. It would crash immediately on any real input. It was like there were two halves of the project that just couldn’t speak to each other. It makes sense as well, as it tried to make use of subagents for development when none of the other models did that.
Omnicoder 9B, the smallest model at 9 billion parameters and roughly 4GB quantized, was always going to be the underdog. In the first test, it hand-rolled its own YAML parser instead of using pyyaml, used Jinja2 for templating, and never got its tests to run. But the code it did produce showed some structural awareness, and for a model that fits on a budget GPU with just 8GB of VRAM, the attempt was respectable.
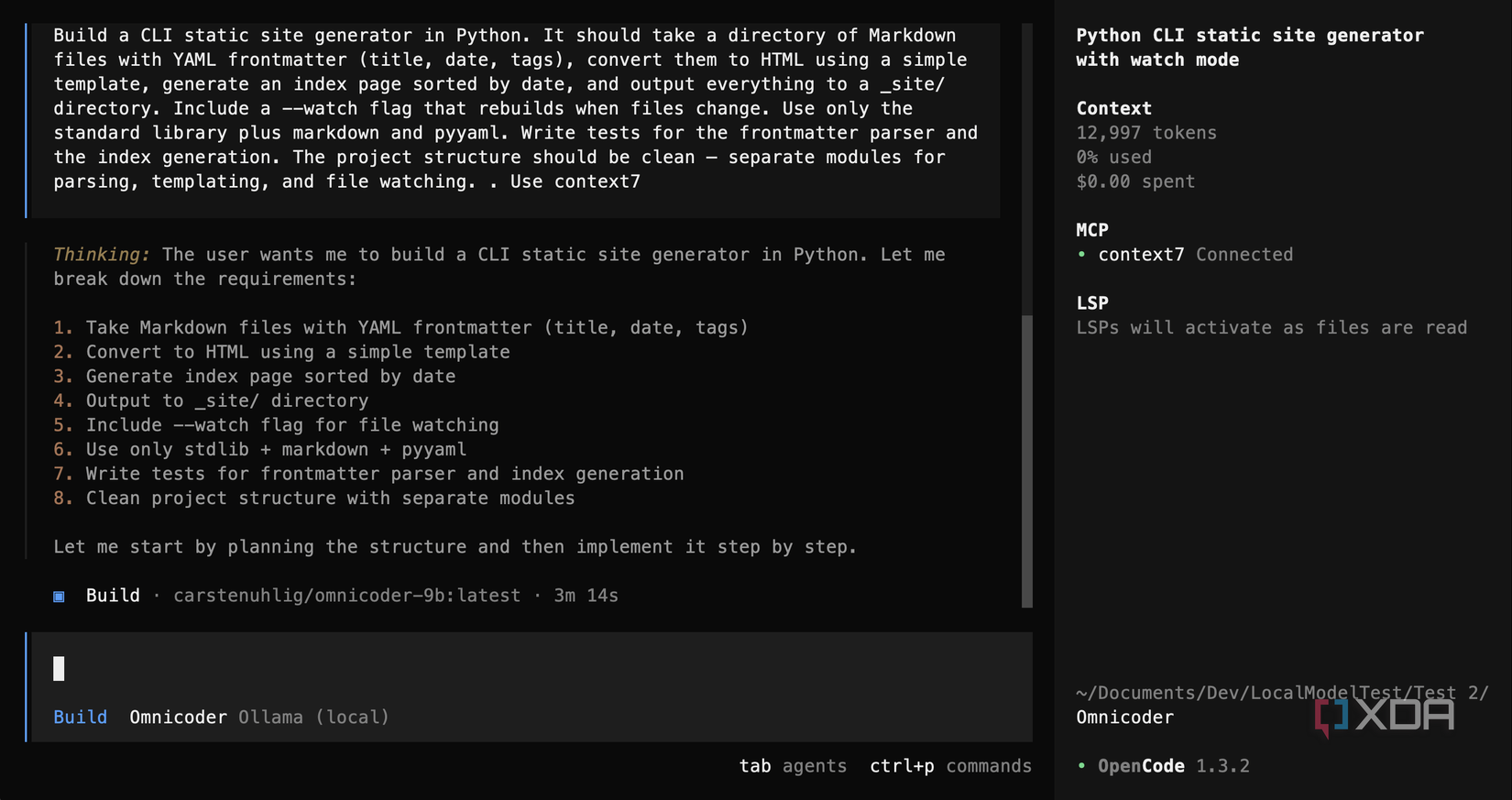
The second test was architecturally better, as it used the correct libraries and had a class-based design, but it took over an hour of constant nudging to continue and never successfully ran the generator. It tried to call Context7 but used the wrong parameter name, failed, and gave up. At 9B parameters, the gap compared to the larger models is pretty big, but it’s not useless. For a first pass at a simple project, there’s something there.
Comparing Qwen3.5 122B A10B to Omnicoder 9B reveals something pretty funny, though; Omnicoder 9B arguably won when comparing the two second tests. Qwen’s code was fundamentally broken with an over-engineered solution. It’s a model with 13 times more parameters than Omnicoder, but Qwen3.5’s active parameters are nearly identical. Omnicoder’s attempt was more in-line with the specification and it would be easier to debug and fix than Qwen3.5’s attempt would be.
Only one model actually read the documentation
The rest decided they already knew enough
The entire point of the second test was to see whether giving models access to live library documentation via Context7 would improve their output, as I imagine that most people running a local LLM would bolt Context7 on to improve the output. It’s a well-documented MCP server that lets models look up real, current documentation for practically any library you can think of. All you have to do is tell the model to “use context7,” and it’s supposed to resolve the libraries it’s working with and fetch the relevant docs before writing code.
Out of five models, only one used it properly. Qwen3 Coder Next resolved library IDs for both markdown and pyyaml, fetched the documentation, and applied what it learned. It’s somewhat comedic that Qwen3 Coder Next produced the best, working result out of the lot in the first test, yet for the second test, it still used Context7 when it was available to it. It already knew more than the other models, but it was the only one to ensure it had the full picture first.
Every other model either ignored the instruction entirely (Devstral 2), searched for the wrong thing (Qwen3.5 searched for generic “Python”), got the library IDs and then decided it didn’t need the actual docs (gpt-oss-120b), or failed to call the tool correctly (Omnicoder 9B used the wrong parameter name).
While most people running local LLMs know this already, MCP tool usage is not automatic. You can give a model access to live documentation and explicitly tell it to use that documentation, but that doesn’t mean it will. A model might not understand the tool interface, doesn’t think it needs help, or it can get the call wrong and give up. The one model that did use it properly improved more between tests than any other model came close to.
Every model made the same mistakes
Training data biases were too strong
There’s a pattern that runs through all five models, regardless of size or architecture, and it’s down to training data. I designed the prompt specifically to test prompt adherence with each of these models, and if they were capable of following explicit instructions rather than solely what their training data suggests. That’s why I included the Context7 test; my thinking was that a model would look up the relevant documentation, and if they struggled in the first test, their second attempt would likely avoid the same pitfalls.
For starters, every single model that got far enough to run tests hit the same PyYAML bug: they wrote unquoted dates in YAML frontmatter (“date: 2023-01-01”) and then wrote code expecting a string. PyYAML auto-parses that into a datetime.date object, not the string “2023-01-01”. Code that calls datetime.fromisoformat() on a date object breaks immediately.
This happens because the vast majority of YAML frontmatter tutorials and blog posts show unquoted dates with code that treats them as strings. Real-world static site generators like Jekyll and Hugo handle the type coercion internally, so users never see raw PyYAML output. The training data is likely saturated with the wrong pattern, and every model converges on the same mistake because it’s the most statistically common one.
The same thing happens with “python” versus “python3” on macOS, with “watchdog” leaking into code or requirements.txt despite the stdlib constraint, and with Jinja2 syntax appearing in custom template engines. The pattern repeats here, because file watching in Python would nearly always be implemented using watchdog, and HTML templating in Python is very likely to be closely associated with Jinja2 in a model’s training data. None of these are reasoning failures in the traditional sense, as the models just reproduce whatever pattern is most common in training data, even when the prompt explicitly says otherwise.
This is also why Context7 matters so much. Qwen3 Coder Next, the one model that actually read the PyYAML docs, resolved the date parsing issue faster than any other model in any test, and it finished in almost half the time on the second attempt. The documentation overrode the training data bias and the date issue was fixed in fewer iterations than any other model managed across either test. This is one of the biggest reasons as to why Qwen3 Coder Next has become my favorite local LLM to run.
If you’re running local models for coding, live documentation retrieval matters more than I expected going in. The problem is that most models aren’t good enough at tool use to actually consistently take advantage of it yet. That gap, between having access to a tool and being able to use it, is where the real work still needs to happen. There are definitely ways to improve a local model’s tool calling, but there’s not much you can do when a model seems to favor its own knowledge regardless.