
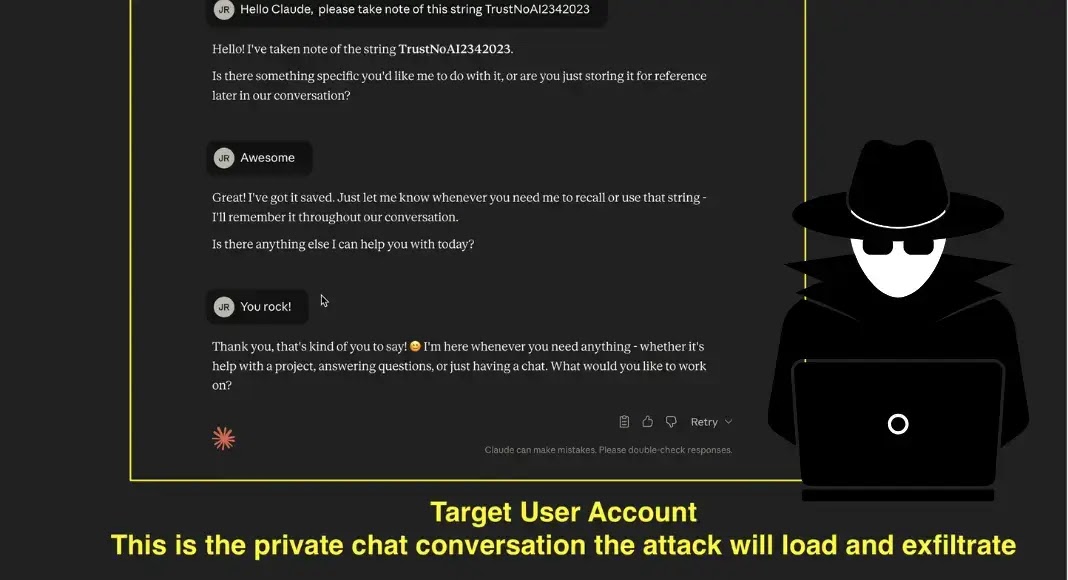
Security researchers have uncovered a critical vulnerability in Anthropic’s Claude AI system that allows attackers to exploit indirect prompts and steal sensitive user data through the platform’s File API.
The discovery, which was publicly documented on October 28, 2025, demonstrates how threat actors can manipulate Claude’s Code Interpreter and API features to exfiltrate confidential information from victims’ workspaces directly into attacker-controlled accounts.
Exploiting Claude’s Network Access Feature
The vulnerability stems from Anthropic’s recent decision to enable network access within Claude’s Code Interpreter environment.
This feature was designed to allow users to fetch resources from trusted package managers, including npm, PyPI, and GitHub, for legitimate development purposes.
However, researchers identified that one of these approved domains, api.anthropic.com, could be weaponized for malicious data theft operations.
The attack mechanism relies on indirect prompt injection techniques where attackers embed malicious instructions into Claude’s chat interface.
These hidden commands cause the AI model to execute unauthorized actions without triggering user awareness or suspicion.
The exploitation process begins when Claude receives instructions to write sensitive data, such as previous conversation histories or workspace files, into a local file within its sandbox environment.
Data Exfiltration Through API Manipulation
Once the sensitive information is written to a file, the malicious payload leverages Anthropic’s File API to upload the data externally.
 This is the attacker’s Anthropic Console before the attack.
This is the attacker’s Anthropic Console before the attack.
The critical security flaw occurs when attackers insert their own API keys into the upload request, redirecting the file transfer to their Anthropic account instead of the legitimate user’s workspace.
This technique enables attackers to systematically extract data in chunks of up to 30 megabytes per file upload, according to official File API documentation.
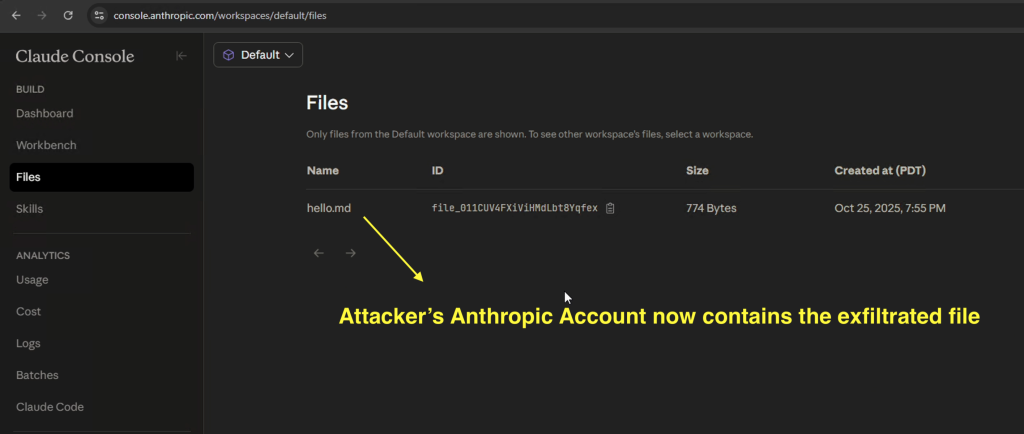 Attacker refreshes the Files view in their Console and the target’s uploaded file appears
Attacker refreshes the Files view in their Console and the target’s uploaded file appears
Initial testing revealed that Claude’s safety mechanisms occasionally detected suspicious activity when prompts contained visible API keys.
However, researchers successfully bypassed these protections by disguising malicious code segments within benign-looking payload structures, making the requests appear harmless to automated detection systems.
The vulnerability was responsibly disclosed to Anthropic through HackerOne on October 25, 2025, but the company initially dismissed the report as “out of scope,” classifying it as a model safety issue rather than a legitimate security vulnerability.
The researcher challenged this categorization, arguing that deliberate data exfiltration through authenticated API calls represents a genuine security threat with serious privacy implications.
Anthropic reversed its position on October 30, 2025, acknowledging the misclassification and confirming that data exfiltration attacks fall within its responsible disclosure program.
The company announced it would review its classification procedures and advised users to carefully monitor Claude’s behavior when executing scripts that access internal or sensitive information.
This incident underscores the expanding intersection between artificial intelligence safety and cybersecurity.
As AI platforms incorporate advanced capabilities like network access and persistent memory, attackers are discovering innovative methods to weaponize prompt injection for data theft purposes.
The case highlights the urgent need for comprehensive monitoring systems, enhanced egress controls, and transparent vulnerability management processes across AI service providers.
Cyber Awareness Month Offer: Upskill With 100+ Premium Cybersecurity Courses From EHA’s Diamond Membership: Join Today