
Large language models demonstrate remarkable abilities, but their size often limits practical deployment, prompting researchers to explore methods for efficient compression. Yesheng Liang and Haisheng Chen from UC San Diego, alongside Song Han and Zhijian Liu from NVIDIA, address this challenge with a novel approach to post-training quantization. Their work introduces Pairwise Rotation Quantization, a technique that refines the process of reducing model precision, specifically targeting the problem of accuracy loss in complex reasoning tasks. By carefully managing the distribution of numerical values within the model, ParoQuant significantly reduces errors that accumulate during lengthy calculations, achieving improved performance with minimal computational overhead and opening new possibilities for deploying powerful language models on a wider range of hardware.
ParoQuant Achieves Efficient 4-bit Language Model Quantization
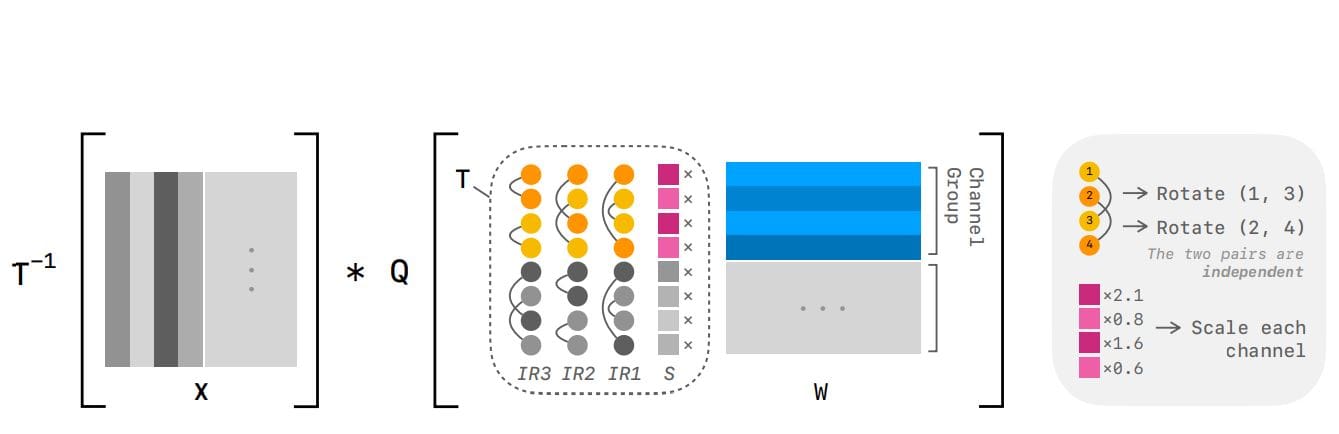
This research introduces ParoQuant, a new post-training quantization method for large language models, designed to compress models and accelerate inference without significant accuracy loss. Scientists recognized that outlier values in both weights and activations hinder low-precision quantization, and engineered a system to suppress these outliers while minimizing computational overhead. The method uses a combination of channel-wise scaling, independent rotations, and a specific quantization scheme to achieve a balance between accuracy and efficiency. The research team implemented channel-wise scaling to concentrate values within each channel, and then applied pairwise rotations to draw values from different channels closer together.
This innovative combination effectively aligns values within each channel pair, narrowing the dynamic range and improving quantization fidelity. The method was rigorously tested on reasoning tasks, demonstrating an average 2. 4% accuracy improvement over the widely used AWQ method, with less than 10% overhead. Experiments involved evaluating models like LLaMA-2, LLaMA-3, and Qwen3 on datasets including WikiText2, C4, RedPajama, and specialized reasoning benchmarks. Performance was measured using metrics like perplexity and accuracy on reasoning tasks, as well as throughput on non-reasoning tasks.
The team utilized hardware including NVIDIA H200 and RTX GPUs, varying batch sizes and sequence lengths to optimize performance. Detailed results demonstrate ParoQuant’s effectiveness across a range of models and tasks. The researchers also conducted thorough comparisons to other quantization methods, including AWQ, QTIP, and EfficientQAT, analyzing trade-offs between accuracy and efficiency. They meticulously documented calibration time, GPU usage, and performance on both reasoning and non-reasoning tasks. The team utilized tools like Lighteval and vLLM for evaluation, employing multiple seeds to reduce variance and ensure reliable results. These findings demonstrate ParoQuant’s ability to deliver a compelling balance between model compression, accuracy, and efficiency.
Pairwise Rotation Quantization Boosts Language Model Efficiency
ParoQuant represents a significant advance in the efficient deployment of large language models, specifically addressing the challenges of post-training quantization. Researchers developed a method that compresses model weights into low-precision formats, reducing memory requirements and accelerating inference without substantial accuracy loss. This approach effectively mitigates the impact of outlier values that commonly degrade performance in quantized models, particularly those designed for complex reasoning tasks.
The team demonstrated that ParoQuant achieves an average accuracy improvement of 2. 4% over existing methods, such as AWQ, on reasoning tasks, while maintaining a low computational overhead of less than 10%. This is accomplished through a carefully designed inference kernel that fully exploits the parallel processing capabilities of modern GPUs. A key aspect of the method is the constraint of mutual independence between rotation pairs, enabling full parallelization and compatibility with block-wise quantization. While acknowledging that a single independent rotation has limited expressiveness, the researchers overcame this by sequentially applying multiple rotations, effectively increasing the transform’s fitting capability.
ParoQuant Boosts Reasoning Accuracy in Quantization
The research team developed Pairwise Rotation Quantization (ParoQuant), a new weight-only post-training quantization method designed to compress large language models while preserving accuracy, particularly in reasoning tasks where errors can accumulate. The work addresses the challenge of reducing model size without significant performance degradation, a crucial step for deploying these models on resource-constrained devices. Experiments demonstrate that ParoQuant achieves a substantial improvement in accuracy compared to existing linear quantization methods, while maintaining competitive efficiency. On the MMLU-Pro benchmark, a large-scale reasoning test, ParoQuant consistently outperformed all linear quantization baselines and matched the accuracy of the vector quantization method QTIP.
Across a suite of reasoning benchmarks, including GPQA and AIME, ParoQuant exhibited superior performance, causing only an average 0. 9% accuracy degradation and achieving improvements of 6. 5%, 2. 4%, and 0. 9% over EfficientQAT, AWQ, and QTIP, respectively.
This demonstrates ParoQuant’s ability to maintain accuracy even in complex, multi-step reasoning processes. The team also evaluated ParoQuant on non-reasoning tasks, finding it maintained near-lossless performance, outperforming AWQ, EfficientQAT, and QTIP by 0. 9%, 0. 7%, and 0. 2%, respectively.
This suggests the method’s effectiveness extends beyond specialized reasoning tasks. In terms of efficiency, ParoQuant achieved a throughput comparable to QTIP while being 15%-30% faster, and was only 10% slower than AWQ, all while providing a significant accuracy improvement. Specifically, on the Qwen3-1. 7B model, ParoQuant achieved a throughput of 320 tokens per second, compared to 170 for the full-precision FP16 model. The researchers implemented ParoQuant within the Transformers library, modifying only the weight transformation and dequantization code, ensuring a fair comparison with other methods. These results demonstrate that ParoQuant offers a compelling trade-off between model compression, accuracy, and efficiency, making it a promising technique for deploying large language models in a wider range of applications.