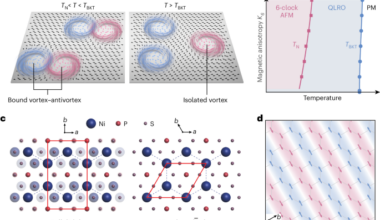
PPhysics Read More Six-state clock physics in an atomically thin antiferromagnetFebruary 24, 2026 Mermin, N. D. The topological theory of defects in ordered media. Rev. Mod. Phys. 51, 591 (1979). Article …
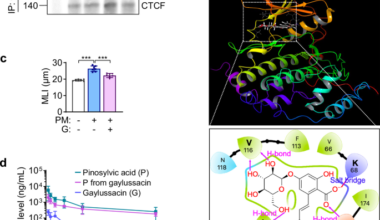
HHealth Read More Stilbenoid gaylussacin modulates particulate matter-induced chromatin remodeling in macrophages to suppress chronic obstructive pulmonary diseaseFebruary 24, 2026 Chronic obstructive pulmonary disease (COPD), a leading cause of mortality worldwide, is characterized by chronic bronchitis and emphysema.1…
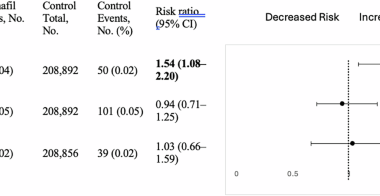
SScience Read More Sildenafil use and risk of serous retinal detachment in men with erectile dysfunction in USFebruary 21, 2026 Phosphodiesterase type 5 inhibitors (PDE5i) are widely used for erectile dysfunction. Case reports and claims-based cohort studies have…
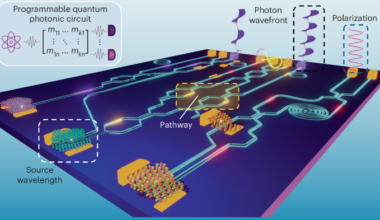
PPhysics Read More Programmable integrated quantum photonics | Nature PhotonicsFebruary 20, 2026 Wehner, S., Elkouss, D. & Hanson, R. Quantum internet: a vision for the road ahead. Science 362, eaam9288…
EEnvironment Read More Extreme events and river biodiversity under climate changeFebruary 20, 2026 Lynch, A. J. et al. People need freshwater biodiversity. WIREs Water 10, e1633 (2023). Article Google Scholar WWF.…
SSpace Read More Award-Winning NASA Camera Revolutionizes How We See the InvisibleFebruary 20, 2026 Imagine trying to photograph wind. That’s similar to what NASA engineers dealt with during a recent effort to…
PPhysics Read More Statistical localization of U(1) lattice gauge theory in a Rydberg simulatorFebruary 20, 2026 Kogut, J. B. The lattice gauge theory approach to quantum chromodynamics. Rev. Mod. Phys. 55, 775 (1983). Article …
PPhysics Read More An exciton crystal in a moiré excitonic insulatorFebruary 19, 2026 Wigner, E. On the interaction of electrons in metals. Phys. Rev. 46, 1002–1011 (1934). Article ADS Google Scholar …
SSports Read More Society Insider: Soul Bar’s general manager Olivia Carter to leave role after 17 years; Steve Dunstan’s new brand repping Auckland; Hannah & Beauden Barrett’s wedding weekendFebruary 18, 2026 Carter has been behind Soul’s highest profile events and hosted many A-list international celebrities in her tenure, including…
SSpace Read More NASA Advances High-Altitude Traffic Management – NASAFebruary 18, 2026 High-altitude flight is getting increasing attention from sectors ranging from telecommunications to emergency response. To make that airspace more accessible,…
PPhysics Read More Collective dynamics on higher-order networksFebruary 18, 2026 Strogatz, S. H. Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering 3rd edn (CRC…
HHealthcare Read More A scoping review of silent trials for medical artificial intelligenceFebruary 17, 2026 Chen, J. H. & Asch, S. M. Machine learning and prediction in medicine—beyond the peak of inflated expectations.…