

In the AI boom, what is the most “coveted” thing for large models? Is it computing power, storage, or complex network interconnection? At Hot Chips 2025, Noam Shazeer, one of the inventors of Transformer and the co-leader of Google’s Gemini, gave the answer.
See through the global large models at a glance! A grand contribution on the tenth anniversary of AI Probe, the 37 – page 2025 ASI Frontier Trends Report is released for the first time.
What do large models need?
At the keynote speech on the first day of the technology event Hot Chips 2025 held in Silicon Valley, Noam Shazeer from Google DeepMind answered this question and delivered a keynote speech titled “Predictions for the Next Phase of AI”.

Besides being one of the authors of the Transformer paper “Attention Is All You Need”, he has also promoted many technological innovations, such as significantly improving the spelling correction function in Google Search.
As early as 2017, he invented the Transformer model and has been deeply involved in the LLM field for ten years.
Later, he developed a chatbot, but Google refused to release the result, which prompted him to leave and found Character.AI.
Soon after, Google realized its own shortcomings and finally reached a cooperation with Character.AI at a high price of $2.7 billion.
Now, Noam has returned to Google and serves as the co – leader of the Gemini project.
As he showed, large language models can continuously improve their performance and accuracy with the improvement of various resources such as hardware.

In the next phase of AI, it’s all about computing power, computing power, and more computing power
Noam Shazeer mainly shared the requirements of LLM, his personal research path in LLM, and the relationship between hardware and LLM.

He emphasized several key points.
First of all, Noam believes that language modeling is the most important research field at present.
He dedicated a slide in his speech to explain this point, which shows his high enthusiasm for this topic.

Then he talked about “What LLMs want”.
He is more concerned about the fact that more FLOPS means better performance.

This is very important because as the number of parameters, depth, non – linearity, and information flow increase, the scale of LLM also increases.
This may require more computing resources. More high – quality training data also helps to create better LLMs.
He also mentioned that in 2015, training on 32 GPUs was a big deal; but ten years later, hundreds of thousands of GPUs may be needed.
Another interesting detail is that he said that in 2018, Google built computing nodes for AI.
This was a big deal because before that, Google engineers usually ran workloads on a thousand CPUs. But then they would slow down and be used for other purposes, such as web crawling.
Having large machines dedicated to deep learning/AI workloads has led to a huge improvement in performance.
Next is a highlight of the chip conference, that is, the hardware requirements of LLM.

An interesting view can be seen from this slide
More computing power, memory capacity, memory bandwidth, and more network bandwidth are all crucial for promoting the progress of future AI models.
At “all levels”, this is not only about the capacity and bandwidth of DDR5, but also includes HBM and on – chip SRAM.
Reducing precision to make better use of these four aspects is also considered a good thing in many cases.
Determinism helps with better programming.
The message of the speech boils down to: Having larger and faster devices in the cluster will lead to gains in LLM.
This may be good news for Google and some other companies.

What kind of hardware do large models need?
Noam is a typical “reverse cross – over person”: as an AI researcher, he is very curious about hardware and always wants to know how these machines work.
In the Mesh – TensorFlow project, he became very interested in the underlying network structure of TPU.

Paper link: https://arxiv.org/abs/1811.02084
He asked many refreshing questions:
Is your chip actually a ring network structure?
How do data packets run in it?
How is it mapped to the tensor calculation of the neural network?
This curiosity ultimately led to many breakthroughs in Google’s collaborative design of software and hardware.
In this speech, Noam Shazeer deeply analyzed what kind of hardware LLM actually needs.
The hardware support needed for AI: It’s not just GPUs
There is no doubt that computing power is the most needed factor for LLM.
When people say “What do LLMs want”, they are actually asking:
How does our hardware system need to change to make AI smarter?
Noam’s answer is clear and direct: The more, the better; the bigger, the better.

1. More FLOPs
The more computing power, the better. It’s best to have petaflops of floating – point operation capabilities. It directly determines how large a model you can train, how large a batch you can use, and how much training data you can cover.
2. Larger memory capacity & higher memory bandwidth
Noam pointed out that insufficient memory bandwidth will limit the flexibility of the model structure. For example, you can’t easily add non – linear layers. And higher bandwidth means more fine – grained control.
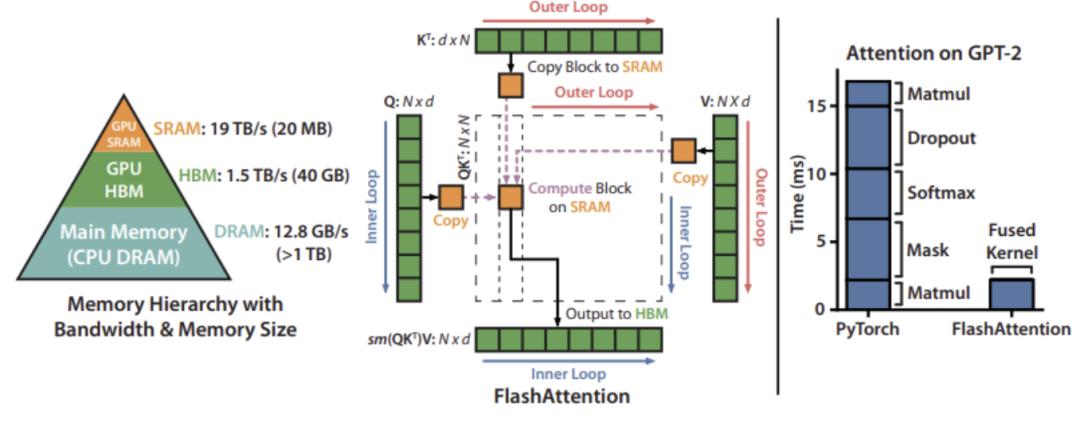
Memory includes: on – chip SRAM, high – bandwidth memory (HBM), video memory, or other medium – high – speed caches such as DRAM
In terms of memory capacity, it directly determines:
How large a model can be accommodated;
How many intermediate states can be retained during inference (such as long context, cache, attention heads, etc.).
3. Network Bandwidth
This is an important factor that many people ignore.
Because whether it is training or inference, LLM almost always : the model is distributed across multiple chips, and data is transferred back and forth between them.
For example, everyone is now pursuing a “long chain of thought”, which means that the model needs to “think” for a longer time to get a stronger answer.
But this also means each step of inference needs to be completed faster, otherwise the response will slow down.
At this time, the bottleneck often lies in whether you can quickly access all the model parameters – not just the copy on the chip, but all parts distributed in an entire computing grid.
Therefore, Noam summarized:
If you want fast inference, the core question is – how much memory bandwidth can your group of chips provide in total?
With the rapid development of AI, where is the way forward for humanity?
He added some other “wish lists” for hardware design.
1. Low Precision
In traditional scientific computing, precision is crucial.
But in LLM, the model itself has a certain degree of “fuzziness”, and low – bit precision often doesn’t have much of an impact.
Therefore, low – precision computing power is completely reasonable. It’s worth using 8 – bit or even 4 – bit to get more FLOPs.
The industry is indeed trying lower and lower precision formats (FP8, INT4, binary, etc.) – as long as convergence can be maintained, the lower the better.
Of course, reproducibility cannot be sacrificed.
The core challenge is “sufficient precision during training” and “small enough error during inference”.
2. Determinism
Noam believes this is the key because the failure rate of machine – learning experiments is already very high.
Many times, you don’t know whether a result fails because of the wrong model structure, problems with the data, or a bug in your code.
If different results are obtained every time you train, you can’t even start “debugging”.
He recalled that in the early days of asynchronous training at Google Brain, there were often situations where “it worked this time, but failed the next time”, and the engineering experience was extremely poor.
So, his advice to hardware designers is:
Unless you can give me 10 times the performance, don’t sacrifice reproducibility.
3. Problems of arithmetic overflow and precision loss
A live audience member asked: How to deal with the overflow or instability that often occurs in low – precision arithmetic?
Noam answered:
Ensure that the accumulator uses higher precision;
Or perform clipping to prevent the values from exploding;
The worst option is “wrap around”.
The host Cliff added a witty remark:
What we want is that after loading the checkpoint, the machine should crash in the same way – this is the real reproducibility.
A tricky question raised by a Waymo engineer : If hardware no longer progresses from today on, can we still develop Artificial General Intelligence (AGI)?
Noam gave a surprising but firm answer: Yes.
He pointed out that AI will accelerate its own development, promoting the continuous evolution of software and system design. Even if the hardware remains the same, we can still make progress through software – level innovations.
Of course – he changed the subject: But if you can continue to develop better hardware, it will be even better.
If AGI really arrives, where should humanity go?
Will AI save or end humanity?
Driven by computing power and data, AI is constantly advancing into more complex fields.
“As long as enough data and computing power are provided, it is possible to learn and reveal the internal structure of the universe.”
In a recent interview, Mustafa Suleyman, the CEO of Microsoft AI, said so.
He pointed out that the current LLM (Large Language Model) is still just a “single – step prediction engine” and is still in the early stage of AI development.
But with the addition of persistent memory and long – term prediction capabilities, LLM is expected to develop into an “action – type AI” with complete planning capabilities:
It can not only formulate complex plans like humans but also continuously execute tasks.
This leap may be achieved by the end of 2026.
Suleyman used the word “breathtaking” to describe this future and emphasized that we are just at the beginning, and everything will soon change profoundly.

该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。