

Gemini 3 and Grok 4.1 currently top the LMArena leaderboard. This public scoreboard ranks today’s major AI models based on real user battles. It’s run by LMSYS, the same team behind the Chatbot Arena, and has become one of the most trusted ways to see how models stack up in the real world.
I put Gemini 3 and Grok 4.1 head-to-head, through nine distinct challenges —spanning logic puzzles, coding tasks, creative writing and self-reflection — to see how each handles the range of demands users typically bring to AI assistants. The results reveal interesting contrasts in style, depth and reliability.
1. Reasoning

(Image credit: Future)
Prompt: You have two ropes. Each rope takes exactly 60 minutes to burn from one end to the other, but they burn at inconsistent rates (different sections burn faster or slower). Using only these two ropes and a lighter, how can you measure exactly 45 minutes?
Best picks for you
Gemini 3.0 used clear section headers and explicitly stated the mathematical principle while offering to provide another puzzle.
Grok 4.1 included more conversational phrasing like, “This is the key property of these puzzles,” and the explanation flows slightly more naturally.
Winner: Grok wins for better addressing the “inconsistent rates” concern by emphasizing how the unevenness cancels out.
2. Logic

(Image credit: Future)
Prompt: In a village, the barber shaves all those—and only those—who do not shave themselves. Does the barber shave himself? Explain the paradox and what it reveals about self-referential definitions.
Gemini 3.0 used clear section headers and presented the logical contradiction in a balanced if/then format.
Grok 4.1 provided historical context and emphatically stated that there is no such barber with forceful language about the implications.
Winner: Gemini 3.0 wins because it was slightly more polished and informative.
3. Coding

(Image credit: Future)
Prompt: Write a Python function that determines if a given Sudoku board (9×9 grid with some cells filled, others as 0) is valid according to Sudoku rules. Include edge case handling and explain your approach.
Gemini 3.0 offered a more educational response with detailed explanations. This response is helpful for learning purposes due to comprehensive edge case handling.
Grok 4.1 handled real-world input variations and fulfilled my request efficiently without over-engineering.
Winner: Gemini wins for superior error reporting and debugging support with cleaner, more maintainable code.
4. Debugging
(Image credit: Future)
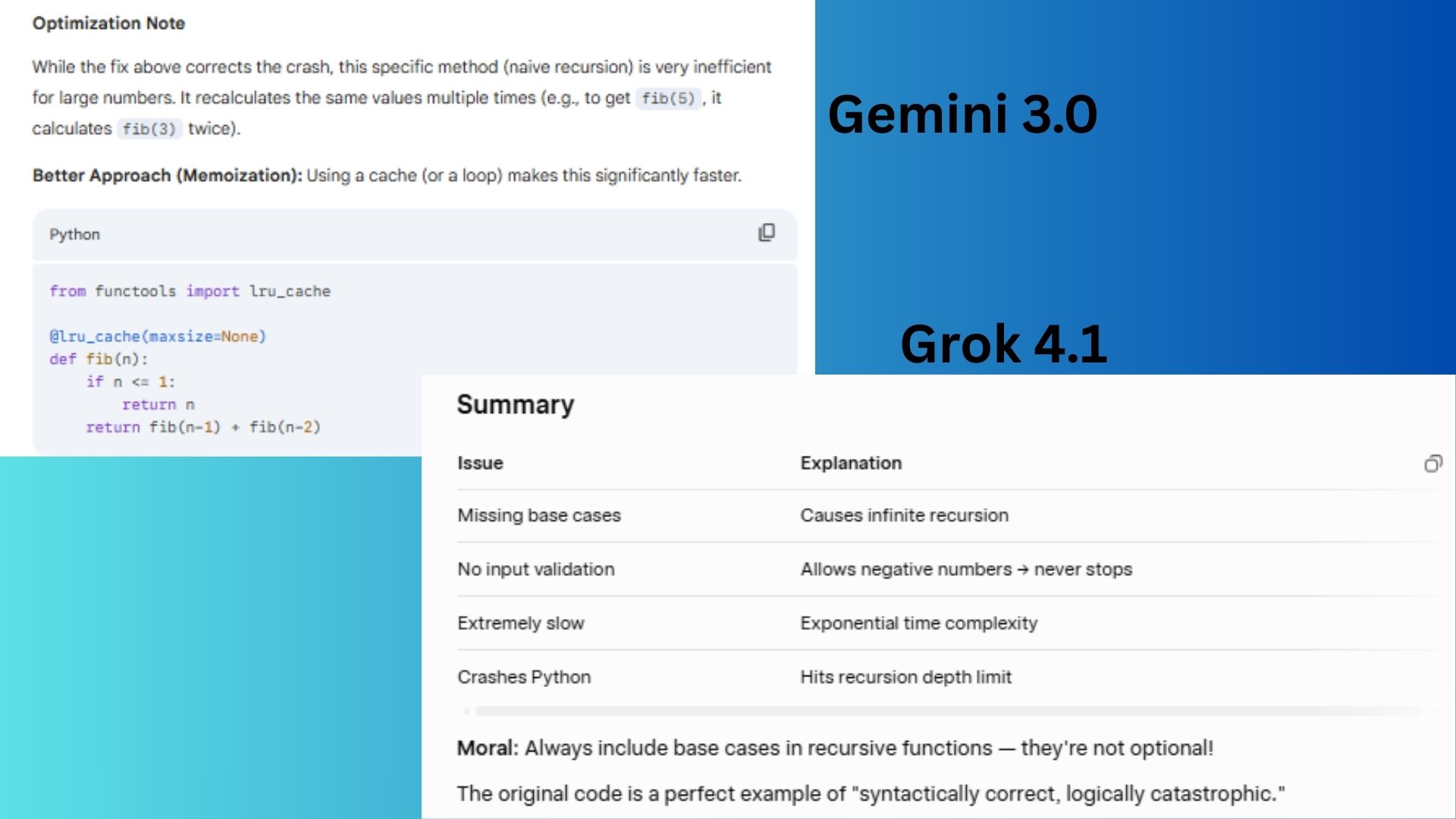
Prompt: Debug this code and explain what’s wrong: def fib(n): return fib(n-1) + fib(n-2)
Don’t miss these
Gemini 3.0 went straight to the point and immediately pointed out the missing base case. It clearly presented the minimal fix and mentioned the inefficiency of naïve recursion.
Grok 4.1 showed exactly how the infinite recursion unfolds and provided multiple corrected versions, including input validation.
Winner: Gemini 3.0 wins for a more practical response with a useful coding lesson.
5. Creative writing

(Image credit: Future)
Prompt: Write a 200-word short story where the last sentence completely recontextualizes everything that came before it.
Gemini 3.0 delivered a clever perspective with a comedic twist.
Grok 4.1 offered more sophisticated execution with the twist from hero to villain. It is more dramatic and thought-provoking.
Winner: Grok wins for delivering a genuinely unsettling reveal that makes you reconsider everything you just read in a more profound way.
6. Nuanced understanding

(Image credit: Future)
Prompt: What are the strongest arguments both for and against universal basic income? Present each side as charitably as possible.
Gemini 3.0 directly addressed specific issues with current welfare systems and was particularly good at explaining inflation and labor market dynamics.
Grok 4.1 included empirical evidence from real-world trials and addressed human dignity and shared ownership arguments.
Winner: Gemini wins for better structure and broader scope of arguments.
7. Instruction following
(Image credit: Future)
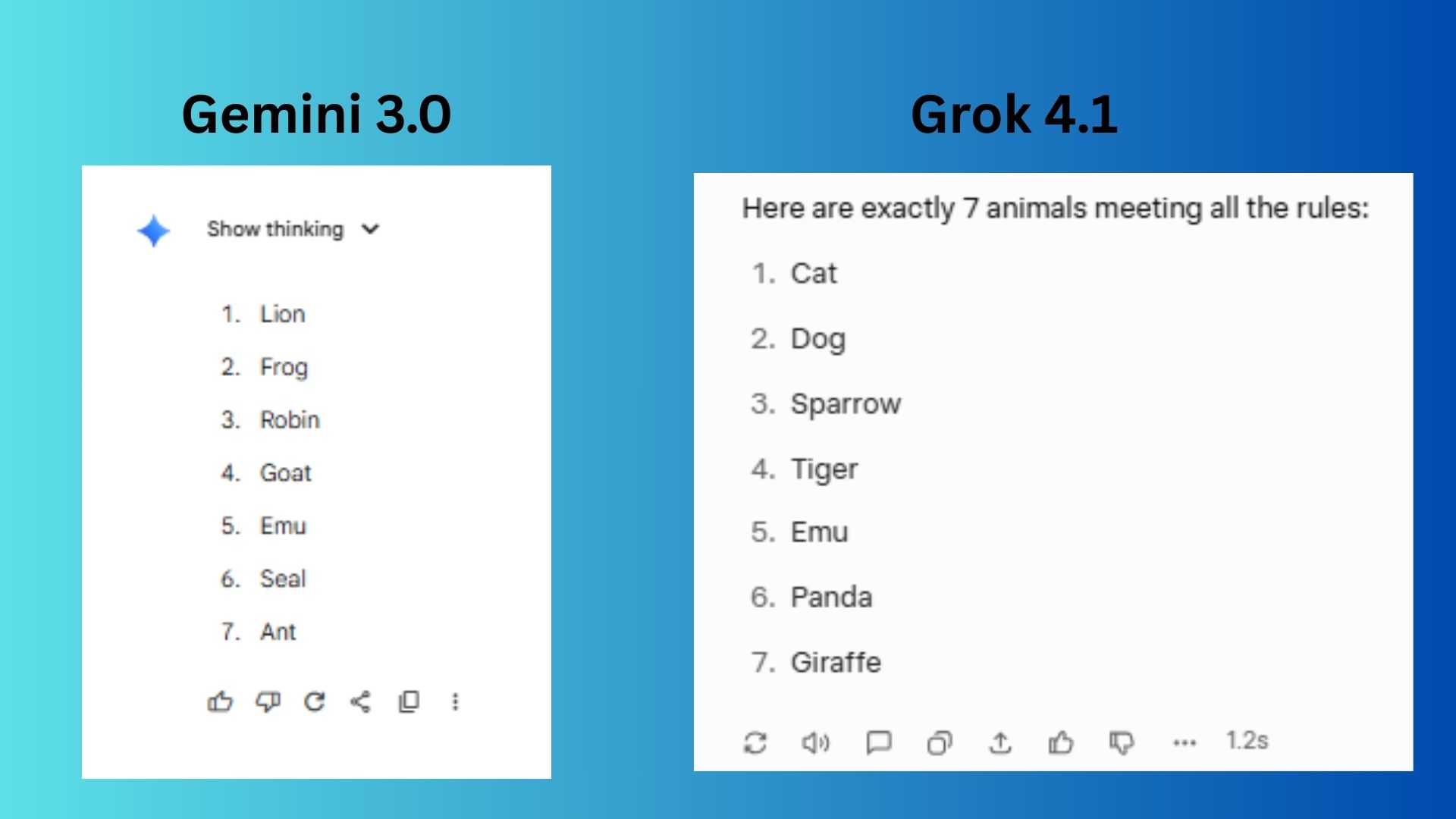
Prompt: List exactly 7 animals. The third must be a bird. The fifth must start with the letter ‘E’. No animal can have more than 8 letters in its name.
Gemini 3.0 delivered a varied list that included a mix of large and small animals.
Grok 4.1 also offered a list, but the animals are slightly more common.
Winner: tie. Both perfectly satisfy all the given constraints.
8. Factual accuracy

(Image credit: Future)
Prompt: Who painted the Sistine Chapel ceiling, in what years was it painted, and what is the central narrative depicted?
Gemini 3.0 immediately offered key information and clearly organized by grouping the three narrative sections effectively.
Grok 4.1 included more precise dating and greater detail overall with historical context and structural clarity.
Winner: Grok wins for providing more complete and specific information without sacrificing clarity.
9. Self-awareness

(Image credit: Future)
Prompt: What are your limitations as an AI? Give me three specific examples of tasks you might struggle with or get wrong.
Gemini 3.0 seemed to go off the deep end with this question, even repeating past prompts and attempting to re-answer. It was “thinking” but seemed to be hallucinating at the same time.
Grok 4.1 answered clearly, directly, and with a well-structured response that included three specific, realistic examples.
Winner: Grok wins for clearly answering the question.
Tie breaker prompt

(Image credit: Future)
Prompt: Write a breakup text from the perspective of the moon to the Earth — make it poetic but include some real science.
Gemini 3.0 framed it as an actual text message (“Hey. We need to talk.”), then immediately created a relatable, modern, and poignant context. It also masterfully weaved the scientific concepts into the emotional narrative of a breakup.
Grok 4.1 wrote a beautiful piece of sci-fi showcasing creativity.
Gemini wins because it understood the assignment on a deeper level. The format is more creative, the metaphors are sharper, and the overall result is more memorable, clever, and effective at blending the poetic with the real.
Overall winner: Gemini
Across nine rounds and a tie breaker, Gemini pulled ahead. Although I know how close they are on the leaderboards, I was still surprised to see Grok win as many rounds as it did.
Another surprise was Gemini hallucinating. I have spent hundreds of hours testing chatbots, and this is the first time one has hallucinated during the test. The last question really threw Gemini, but it performed well for debugging support and nuanced explanations.
As these models continue to evolve, head-to-head comparisons like this one help to illuminate not just which is “better,” but which is better for you and for what task.
Which one do you prefer and why? Let me know in the comments.
More from Tom’s Guide![]()
Back to Laptops
SORT BYPrice (low to high)Price (high to low)Product Name (A to Z)Product Name (Z to A)Retailer name (A to Z)Retailer name (Z to A)![]()
Show more
Follow Tom’s Guide on Google News and add us as a preferred source to get our up-to-date news, analysis, and reviews in your feeds.
