
Automatic differentiation, a technique for calculating the gradients of functions, is experiencing a surge in importance, fuelled by advances in both machine learning and scientific computing. Afif Boudaoud, Alexandru Calotoiu, Marcin Copik, and Torsten Hoefler, all from ETH Zurich, present a new system, DaCe AD, that addresses key limitations of existing approaches to this crucial calculation. Current automatic differentiation frameworks often demand code modifications, struggle with the performance demands of scientific computing, and require excessive memory storage, forcing scientists to manually derive gradients for complex problems. DaCe AD overcomes these challenges with a novel optimisation algorithm, achieving significantly improved performance, over 92 times faster on average, on standard benchmarks without any code alterations, and promises to accelerate progress across a wide range of computational disciplines.
Automatic Differentiation for Large Scientific Models
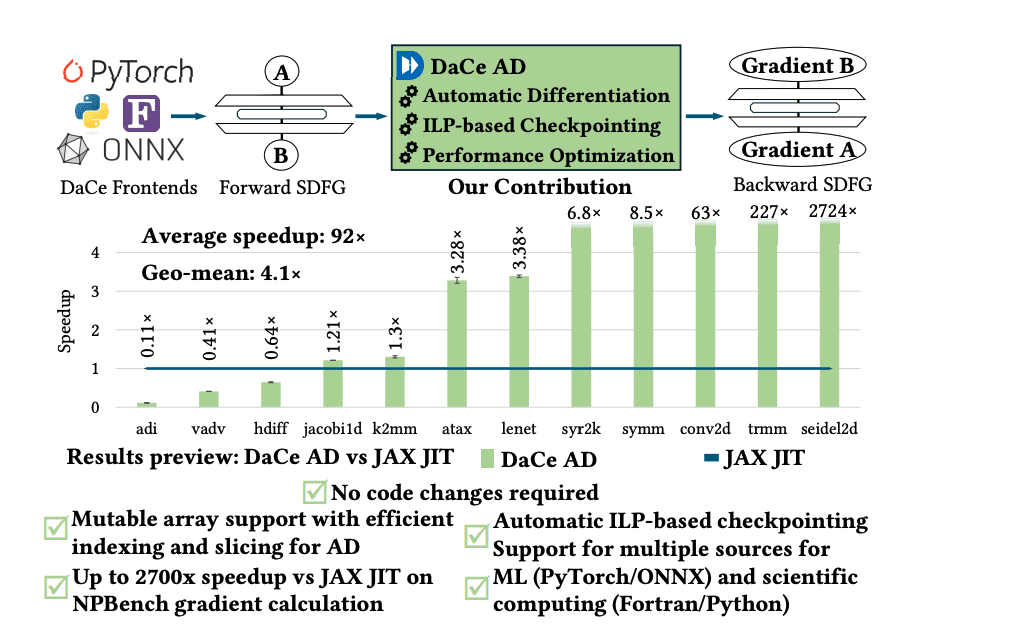
This paper explores techniques for enabling and optimizing automatic differentiation (AD) in large-scale scientific computing applications, making it practical and efficient for complex models and simulations used in fields like weather forecasting, climate modeling, and potentially machine learning. The research investigates techniques like checkpointing and rematerialization to reduce memory footprint, and explores memory-efficient algorithms to reduce overall memory requirements. The research addresses how to parallelize AD computations to take advantage of modern hardware, including GPUs and multi-core CPUs, and emphasizes the use of compiler technology to automate and optimize AD through source-to-source transformation and expression optimization. Unlike current systems requiring substantial code modification or limited to specific programming languages, DaCe AD operates without code rewrites and supports programs written in Python, PyTorch, ONNX, and Fortran. The core innovation lies in a new method for balancing the trade-off between storing data and recomputing it during gradient calculation. Scientists implemented this balance using an Integer Linear Programming (ILP)-based checkpointing technique, automatically determining which intermediate values to store and which to recalculate to maximize performance within given memory constraints.
This approach leverages DaCe’s Stateful DataFlow multiGraph (SDFG) intermediate representation, facilitating tracking data movement and dataflow analysis crucial for efficient gradient computation. Researchers integrated Critical Computation Subgraphs into the SDFGs, enabling the creation of backward passes and the application of automatic differentiation to both sequential and parallel loops. Experiments demonstrate that DaCe AD significantly outperforms the state-of-the-art JAX framework on the NPBench suite of high-performance computing benchmarks, achieving an average speedup of 92 times with a geometric mean of 4. 1 times faster performance. This system overcomes limitations found in existing tools, which typically support only a limited range of programming languages and often require substantial code modifications. DaCe AD uniquely requires zero code rewrites, streamlining the integration of diverse computational models, and achieves this through a novel approach to balancing memory usage and recomputation. Experiments demonstrate that DaCe AD outperforms the state-of-the-art JAX system by an average factor of 92x on the NPBench benchmark suite, with a remarkable 2700x speedup on certain benchmarks.
This breakthrough is enabled by an innovative Integer Linear Programming (ILP)-based technique that automatically optimizes checkpointing, intelligently deciding which intermediate values to store and which to recompute. DaCe AD’s architecture leverages a data-centric intermediate representation called the Stateful DataFlow multiGraph (SDFG), which facilitates tracking data movement and enables efficient dataflow analysis. This allows the system to effectively manage data overwrites, propagate gradients through loops, and optimize the storage and recomputation of intermediate values. The geometric mean speedup across the NPBench suite is 4. 1x, confirming the consistent performance gains achieved by this new framework.
DaCe AD Outperforms JAX for Scientific Computing
DaCe AD presents a new approach to automatic differentiation, a technique crucial for efficiently calculating gradients in machine learning and scientific computing applications. This work addresses limitations found in existing frameworks, such as limited programming language support and performance issues with complex scientific codes, by introducing a system that requires no code modifications. The core innovation lies in an algorithm optimising the balance between storing and recomputing data, achieving significant performance gains. Demonstrating its effectiveness, DaCe AD outperforms the state-of-the-art JAX framework by an average factor of 4.
1 across a suite of high-performance computing problems, and by as much as 92 times in some cases. This improvement is achieved through a novel automatic checkpointing strategy, which automatically manages data storage based on user-defined memory limits, enabling the application of automatic differentiation to more complex programs. Future work could explore applications in hybrid AI4Science scenarios, leveraging these advancements for new computational possibilities.
👉 More information
🗞 DaCe AD: Unifying High-Performance Automatic Differentiation for Machine Learning and Scientific Computing
🧠 ArXiv: https://arxiv.org/abs/2509.02197