

 Card Level Scaleup: 16 Chiplet Hierarchical All-to-All
Card Level Scaleup: 16 Chiplet Hierarchical All-to-All
The second machine learning presentation of the afternoon comes from d-Matrix. The company specializes in hardware for AI inference, and as of late has been tackling the matter of how to improve inference performance by using in-memory computing. Along those lines, the company is presenting its Corsair in-memory computing chiplet architecture at Hot Chips. As a quick note: we covered d-Matrix Pavehawk Brings 3DIMC to Challenge HBM for AI Inference a few days ago.
Not to be confused with that Corsair, d-Matrix claims that Corsair is the most efficient inference platform on the market, thanks to its combination of in-memory computing and low-latency interconnects.
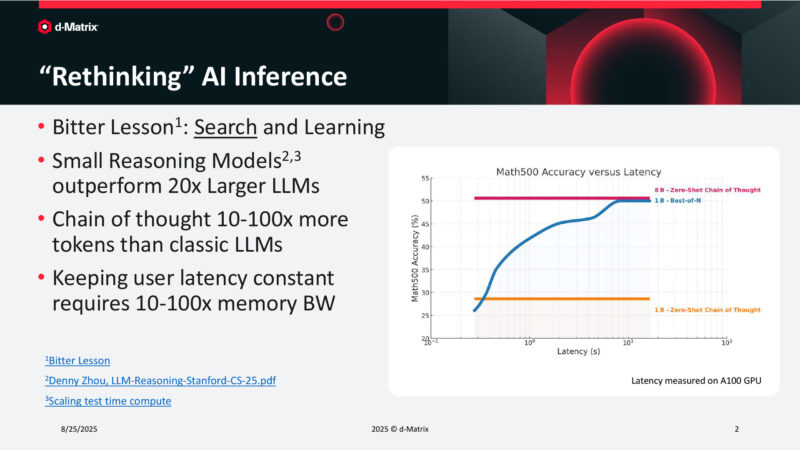 “Rethinking” AI Inference
“Rethinking” AI Inference
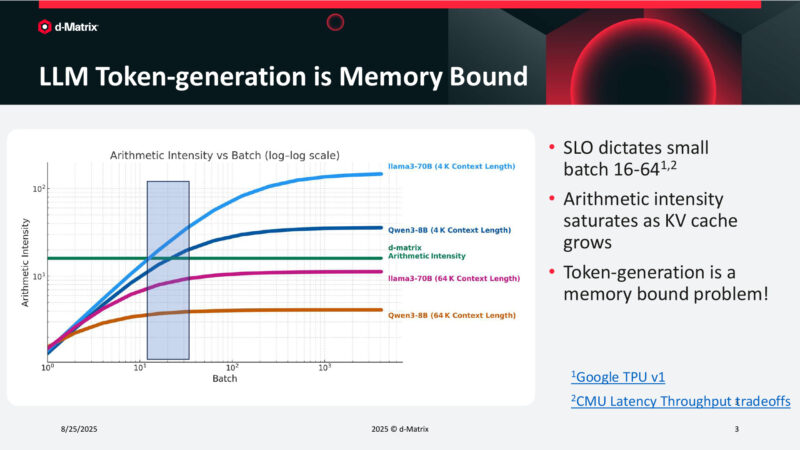 LLM Token-generation is Memory Bound
LLM Token-generation is Memory Bound
Each token in an LLM is memory bound. All the weights need to be read. Batching allows for these weight fetches to be amortized.
d-Matrix’s goal is to reach saturation at moderate batch sizes in order to hit specific latency targets.
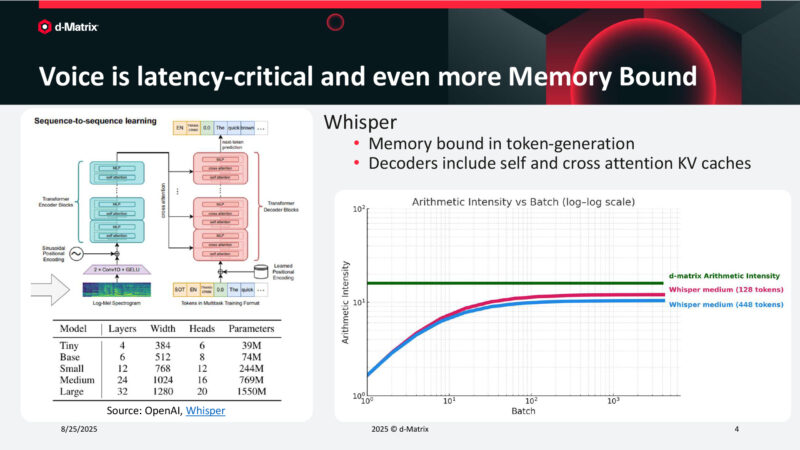 Voice is latency-critical and even more Memory Bound
Voice is latency-critical and even more Memory Bound
Real-time voice requires very low latency. Making it a good target for d-Matrix’s technology.
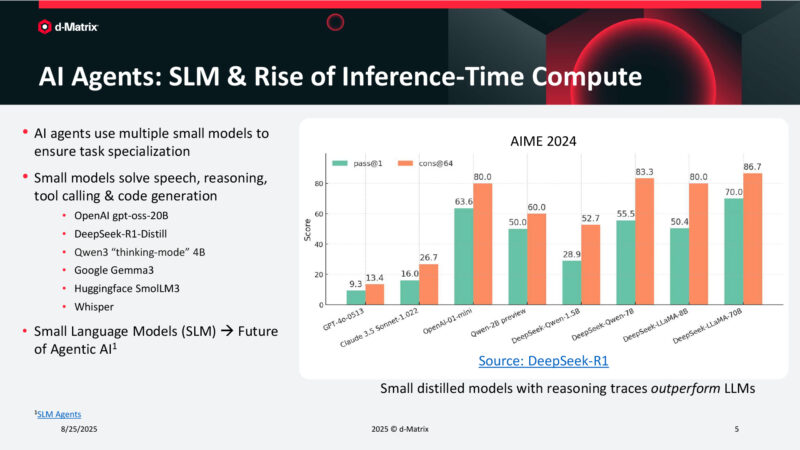 AI Agents: SLM & Rise of Inference-Time Compute
AI Agents: SLM & Rise of Inference-Time Compute
AI agents fall into the same boat. Multiple small models being executed to accomplish the desired task.
 d-Matrix Corsair: Chiplet-based Inference Acceleration Platform
d-Matrix Corsair: Chiplet-based Inference Acceleration Platform
And here is Corair, d-Matrix’s accelerator. Two chips, each with 4 chiplets. Built on TSMC 6nm. 2GB of SRAM between all of the chiplets. This is a PCIe 5.0 x16 card, so it can be easily added to standard servers.
Meanwhile at the top of the card are bridge connectors to tie together multiple cards.
Each chiplet interfaces with LPDDR5X, with 256GB of L5X per card.
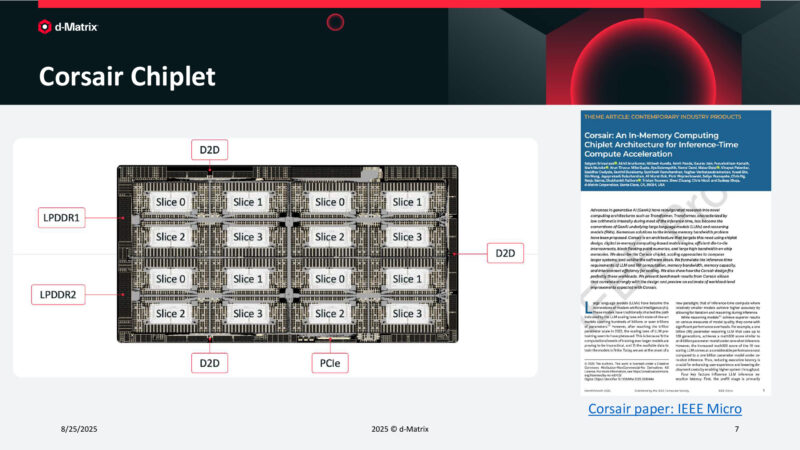 Corsair Chiplet
Corsair Chiplet
And here is how the chiplets are organized into slices. Around the edge are LPDDR and D2D connections. As well as 16 lanes of PCIe.
 Card Level Scaleup: 16 Chiplet Hierarchical All-to-All
Card Level Scaleup: 16 Chiplet Hierarchical All-to-All
Two cards can be passively bridged together, making for a 16 chiplet cluster, with all-to-all connectivity.
 System and Scaleup Architecture
System and Scaleup Architecture
8 cards in turn can go into a standard server, such as a Supermicro X14. In this example there are also 4 NIC cards to offer scale-up capabilities.
 Corsair Key Pillars – Low Latency, Batched Throughput
Corsair Key Pillars – Low Latency, Batched Throughput
Corsair was built for low-latency batch throughput inference.
They support block floating point number formats. Energy efficiency is 38 TOPS per Watt.
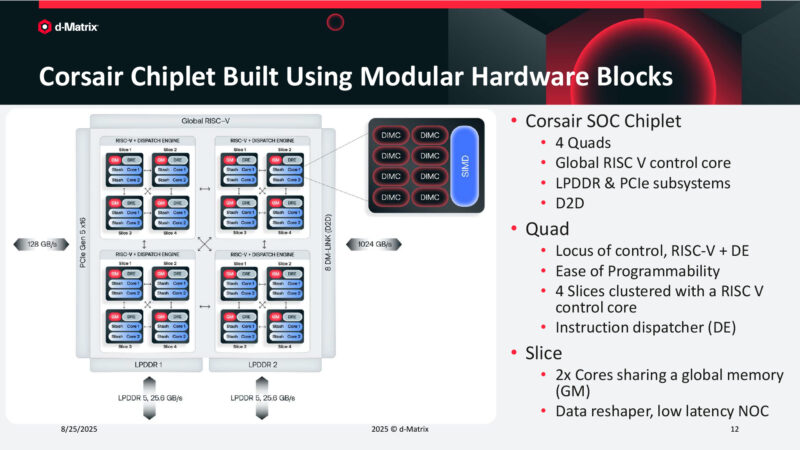 Corsair Chiplet Built Using Modular Hardware Blocks
Corsair Chiplet Built Using Modular Hardware Blocks
The dispatch engine within each chiplet is based on RISC-V. 1 chiplet is split up into 4 quads. About 1TB/sec of D2D bandwidth.
 Energy Efficient DIMC Architecture
Energy Efficient DIMC Architecture
Diving deeper, the matrix multiplier inside Corsair can perform a 64×64 matmul with INT8. Or 64×128 with INT4.
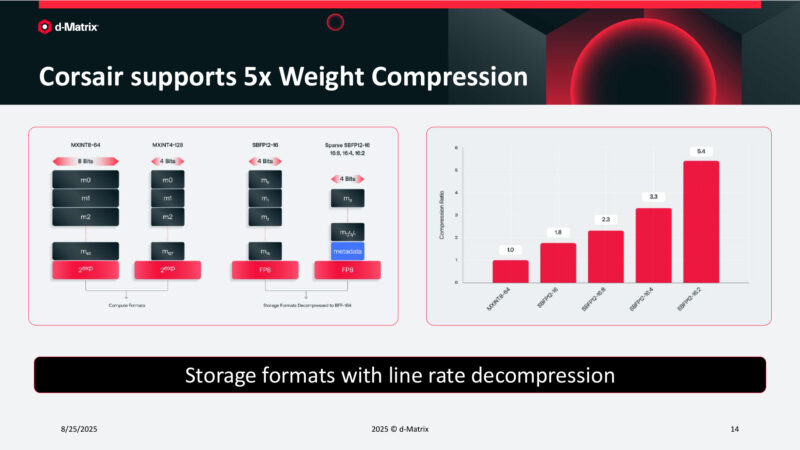 Corsair supports 5x Weight Compression
Corsair supports 5x Weight Compression
Corsair also supports FP formats with scale factors. As well as structured sparsity – though it’s only used for compression. Overall, it gets d-Matrix to 5x compression.
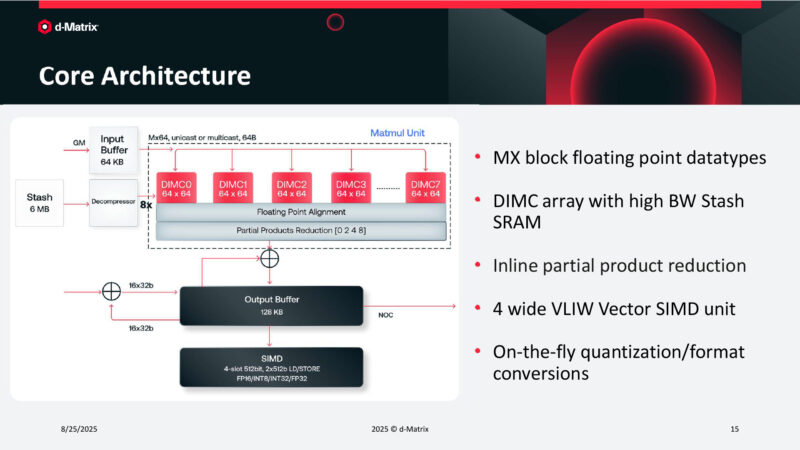 Core Architecture
Core Architecture
All 8 matrix units can be tied together.
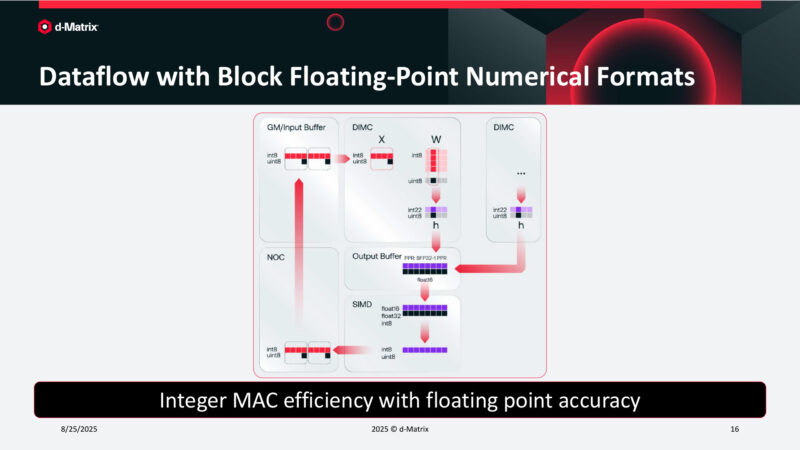 Dataflow with Block Floating-Point Numerical Formats
Dataflow with Block Floating-Point Numerical Formats
Dataflow. Accumulated on the fly and then converted to the desired output format.
 Memory System: Global Memory, Stash, and LPDDR
Memory System: Global Memory, Stash, and LPDDR
As for memory, there is a stash memory that feeds the cores. Each stash is 6MB. There are 2 LPDDR channels per chiplet.
 Scaling Challenges for Large-Model Inference
Scaling Challenges for Large-Model Inference
When you have high memory bandwidth, the collective latency becomes increasingly critical.
 Corsair Scaleup – Hardware-Software Codesign
Corsair Scaleup – Hardware-Software Codesign
So in order to do a 16 chiplet all-to-all connection, d-Matrix got latency down to 115ns D2D. Even going through PCIe switches, they can still hold latency to 650ns.
 Package Level Scaleup: 4 Chiplet All-to-All
Package Level Scaleup: 4 Chiplet All-to-All
Another shot of Corsair chiplets on an organic package.
 Transparent NIC – Ethernet Scale-Out
Transparent NIC – Ethernet Scale-Out
And here is the NIC that d-Matrix uses for scale-out fabrics. 2us of latency.
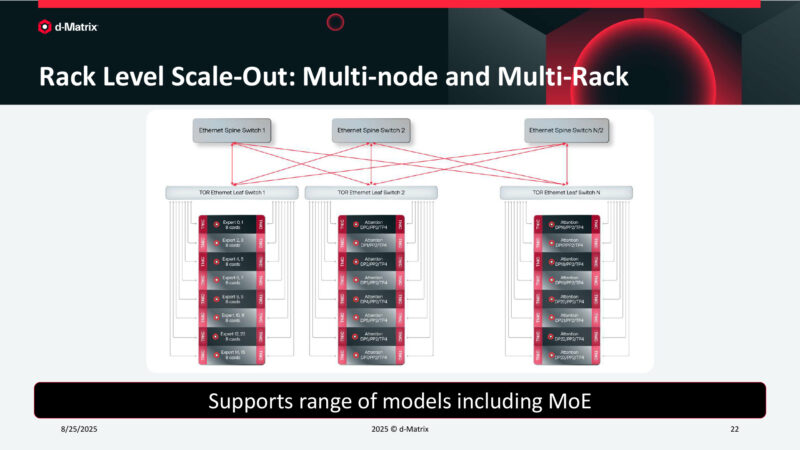 Rack Level Scale-Out: Multi-node and Multi-Rack
Rack Level Scale-Out: Multi-node and Multi-Rack
Using this, d-Matrix can rack and stack many servers.
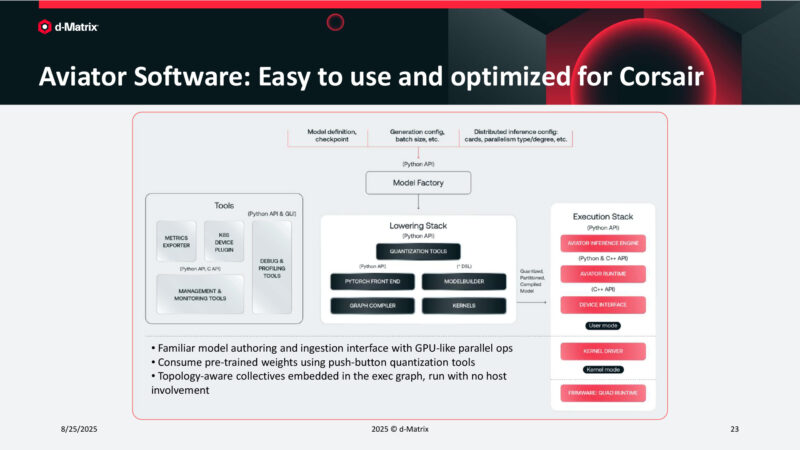 Aviator Software: Easy to use and optimized for Corsair
Aviator Software: Easy to use and optimized for Corsair
 Aviator Software: Codesigned for LLM Acceleration
Aviator Software: Codesigned for LLM Acceleration
And no inference accelerator would be complete without a matching software stack to enable the hardware and its features.
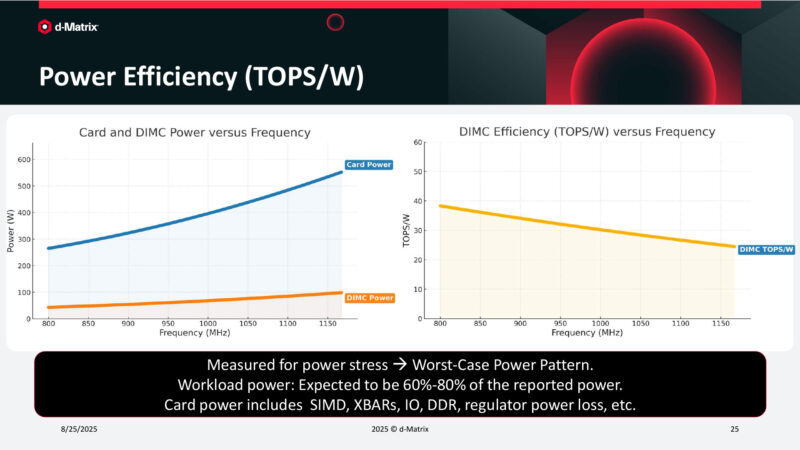 Power Efficiency (TOPS/W)
Power Efficiency (TOPS/W)
And here’s a look at power consumption. 275W @ 800MHz. Meanwhile 1.2GHz chugs 550W. Higher clockspeeds are worse for overall efficiency, but not immensely so.
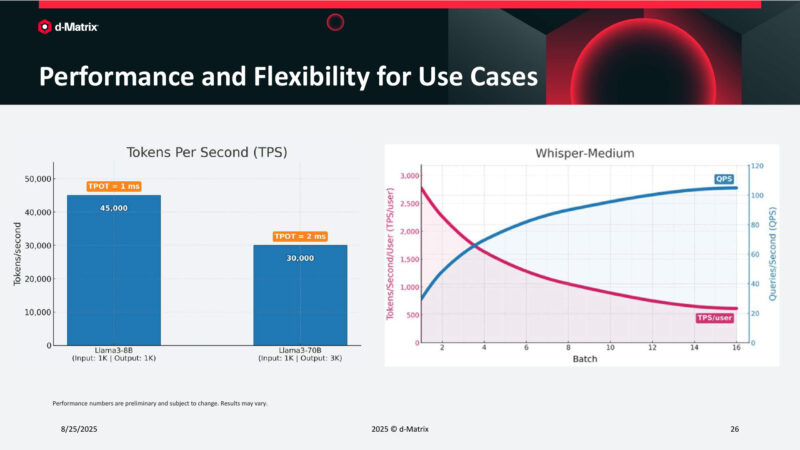 Performance and Flexibility for Use Cases
Performance and Flexibility for Use Cases
And here are some Llama3 performance figures. The time per output token is just 2ms even for the larger Llama3-70B.
 Stacking of logic on DRAM interposer in 3D
Stacking of logic on DRAM interposer in 3D
Underneath the chip, d-Matrix uses a silicon interposer with capacitor for power reliabiltiy reasons. d-Matrix goes one further and 3D stacks DRAM beneath their Corsair chiplets, keeping the local memory very, very close.
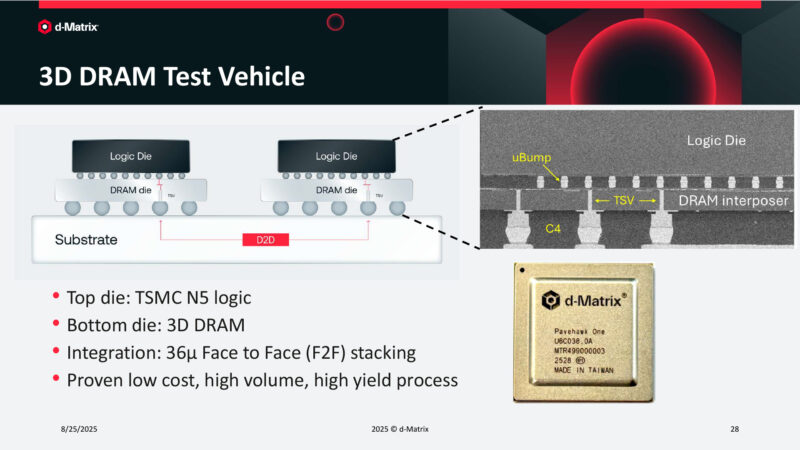 3D DRAM Test Vehicle
3D DRAM Test Vehicle
And they have a prototype 3D DRAM test vehicle that’s been built. 36 micron D2D stacking. The logic die sits on top, while the DRAM sits underneath.
How does d-Matrix make stacked DRAM + logic work? Keep the heat density to under 0.3W/mm2, which keeps from heating up the DRAM too much.