
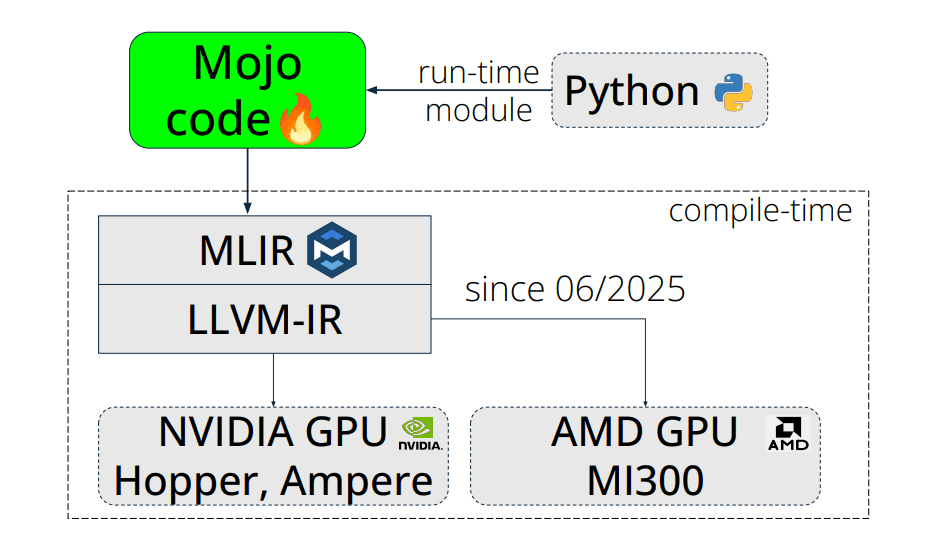
Scientific computing increasingly demands both performance and ease of use, a challenge particularly acute within the Python ecosystem, and researchers are now exploring new approaches to bridge this gap. William F Godoy, Tatiana Melnichenko, Pedro Valero-Lara, and colleagues at Oak Ridge National Laboratory and The University of Tennessee, Knoxville, investigate the potential of the Mojo programming language for accelerating scientific workloads on modern GPUs. This work demonstrates that Mojo, the first language built on the LLVM’s Multi-Level Intermediate Representation (MLIR) compiler infrastructure, achieves performance competitive with established languages like CUDA and HIP for memory-intensive tasks. While challenges remain in optimising atomic operations and fast-math computations on certain GPUs, these results suggest Mojo offers a promising path towards unifying scientific computing and artificial intelligence within a single, efficient framework.
Mojo, CUDA, HIP Benchmark Implementation and Evaluation
This document details the setup, compilation, execution, and evaluation of scientific computing benchmarks implemented in Mojo, CUDA, and HIP, providing a framework for reproducible results and comparison of performance across different platforms. The benchmarks include a seven-point stencil, BabelStream, miniBUDE, and Hartree-Fock. All code, scripts, and necessary files are hosted on GitHub at [https://github. com/tdehoff/Mojo-workloads](https://github. com/tdehoff/Mojo-workloads). The workflow involves compiling the code using Makefiles for CUDA/HIP or pixi for Mojo, running the benchmark with specified parameters, collecting comma-separated value (CSV) output, and using Python scripts to generate plots. This document serves as a comprehensive guide for researchers and developers to evaluate the performance of these benchmarks on different hardware and software platforms, providing a clear methodology for achieving reproducible results and comparing Mojo, CUDA, and HIP implementations.
Mojo GPU Performance Across Scientific Kernels
This study pioneers a performance evaluation of the novel Mojo programming language for scientific computing on graphics processing units (GPUs), focusing on its potential to improve both performance and productivity. Researchers ported four widely used scientific kernels, a seven-point stencil, BabelStream, miniBUDE, and Hartree-Fock, to leverage Mojo’s portable GPU code capabilities. These kernels represent diverse computational characteristics, including memory-bandwidth limited operations and compute-bound tasks with atomic operations, ensuring a comprehensive assessment of Mojo’s performance across different workloads. To rigorously evaluate Mojo, the team implemented each kernel in Mojo and compared its performance against established vendor baselines written in CUDA and HIP.
Experiments were conducted on both NVIDIA H100 and AMD MI300A GPUs, providing a direct comparison of Mojo’s performance portability across different hardware architectures. The study employed a performance-portability metric to summarize the comparisons across both NVIDIA and AMD GPUs, quantifying Mojo’s ability to deliver consistent performance regardless of the underlying hardware. The results demonstrate Mojo’s competitiveness with CUDA and HIP for memory-bound kernels, while identifying areas where further optimization is needed for atomic operations and fast-math compute-bound kernels on both NVIDIA and AMD GPUs.
Mojo Rivals CUDA and HIP on GPUs
This work presents a comprehensive evaluation of the Mojo programming language for scientific computing on GPUs, demonstrating its potential to bridge performance and productivity gaps. Researchers successfully ported four widely used scientific kernels, a seven-point stencil, BabelStream, miniBUDE, and Hartree-Fock, to Mojo, enabling performance-portable GPU code within the Python ecosystem. The team meticulously analyzed the performance of these kernels on both NVIDIA H100 and AMD MI300A GPUs, comparing Mojo implementations against vendor-specific CUDA and HIP baselines. Experiments revealed that Mojo achieves competitive performance with CUDA and HIP for memory-bound kernels, such as the seven-point stencil and BabelStream.
Specifically, the seven-point stencil kernel demonstrated comparable throughput on both NVIDIA and AMD GPUs when implemented in Mojo, indicating effective memory access patterns. However, performance gaps emerged on AMD GPUs for kernels utilizing atomic operations, as well as for fast-math compute-bound kernels on both AMD and NVIDIA platforms. The team introduced a performance-portability metric to summarize the results, highlighting Mojo’s ability to deliver consistent performance across different GPU architectures for certain workloads. This research establishes Mojo as a promising language for scientific computing, offering a pathway towards increased productivity and portability in the rapidly evolving landscape of GPU programming.
Mojo Achieves Competitive GPU Performance for Science
This research demonstrates the capabilities of Mojo, a new programming language built upon the MLIR compiler infrastructure, for scientific computing on both NVIDIA and AMD GPUs. The team successfully implemented and evaluated four representative scientific workloads, a stencil calculation, BabelStream, miniBUDE, and Hartree-Fock, achieving performance competitive with established languages like CUDA and HIP for memory-bound tasks. This work represents a significant step towards a unified, portable programming model for GPU acceleration, leveraging Mojo’s ability to bridge the gap between the ease of use of Python and the performance of lower-level compiled languages. The study highlights Mojo’s potential to address fragmentation within the scientific computing ecosystem, offering a single language capable of targeting multiple GPU architectures.
While the results show strong performance on NVIDIA hardware and competitive results for memory-bound kernels on AMD GPUs, the authors acknowledge existing performance gaps, particularly concerning atomic operations and fast-math compute-bound kernels on AMD platforms. Future work will likely focus on optimising these areas to fully realise Mojo’s promise of performance portability and to further integrate its capabilities with the broader Python scientific computing landscape. The provision of all software artifacts ensures reproducibility and facilitates further investigation by the wider research community.
👉 More information
🗞 Mojo: MLIR-Based Performance-Portable HPC Science Kernels on GPUs for the Python Ecosystem
🧠 ArXiv: https://arxiv.org/abs/2509.21039