
The automation of acoustic analysis represents a rapidly evolving interdisciplinary domain of research, combining acoustics, signal processing, and machine learning. Two particularly important tasks in audio analysis are Sound Event Classification (SEC), which involves the classification and assignment of categorical labels to audio segments with the aim of identifying sound sources, and Sound Event Detection (SED), which determines the occurrence of sound events within the time component of a recording and includes the precise timestamp of an event’s onset and offset. The two aforementioned tasks address the two-fold problem of classifying acoustic information and specifying the respective temporal characteristics across various auditory scenes. Sound Event Detection (SED) has gained significant research attention over the past several years due to its widespread applications. It is central to many applications including urban acoustic planning1 healthcare2,3,4, bioacoustics monitoring5,6,7, surveillance in security8, multimedia event detection9, event analysis in a large scale10, industrial noise monitoring11, smart-home technology12 and wildlife monitoring13.
Although deep learning has transformed image recognition and many other fields, progress in recognising everyday sounds has not been as rapid, partly because there are no standardised, even large, audio datasets14,15,16. In fact, there are so many applications that new neural networks for SEC and SED are being developed every day, and older ones need to be updated. Both processes continuously require detailed and tuned datasets, which then become extremely valuable as they should be as specific as possible. However, the currently available datasets do not take into account the complexity of realistic environments, which include multiple sounds or mixtures of sounds with a constantly present background noise17,18. This is particularly true for outdoor applications, where the lack of high quality, large and diverse datasets is recognised as a significant challenge for SED19,20.
In recent years, several datasets have been developed to support sound event classification (SEC) and sound event detection (SED) tasks, including UrbanSound21 and UrbanSound8K21, ESC-5014, AudioSet22, and FSD50K17. Many of these datasets were partially constructed using audio clips from collaborative platforms such as Freesound.org23, which has become a widely used resource for real-world soundscape data. These datasets have significantly contributed to the advancement of the field and are commonly used for benchmarking and training. However, they also present limitations that can reduce their applicability to real-world environmental noise analysis. These include a limited number of classes14, the use of synthetic or pre-processed content18, class imbalance17, constrained clip durations19, limited contextual diversity17,18, and lack of access to original recordings18. Such limitations are particularly relevant for outdoor environments, where overlapping sounds, fluctuating background noise, and high acoustic variability make sound detection and classification especially challenging17,18,19,20. While synthetic datasets have been proposed to address some of these issues, they often fail to reflect the acoustic complexity and unpredictability of real-world soundscapes24,25,26,27,28.
The creation of an environmental sound database is a complex task that requires the collaboration of multidisciplinary expertise in different fields to make it manageable. There is a considerable amount of effort to create benchmark databases for use in environmental acoustics.
To address the main issue raised, the present work presents DataSEC.29 and DataSED30, two datasets in the form of .wav files, one specifically created for SEC and the other for SED of outdoor environmental noise. Both consist of real-world measurements covering a wide variety of sounds that can be heard outdoors in both urban and rural environments.
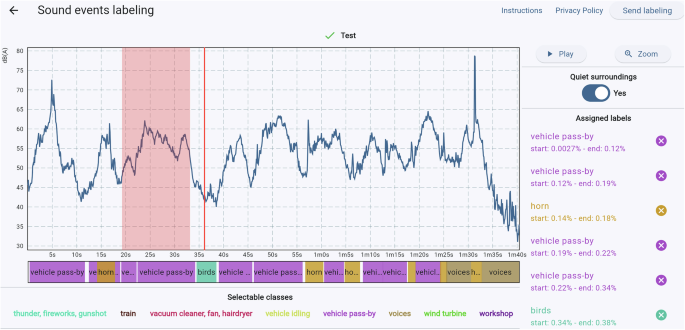
The principal task in methodological development, specifically in the developing field of machine learning applied to environmental noise analysis, is the proper definition of sound event categories (classes), which is a salient distinction of these datasets from others. The dataset has been categorised into 22 macro classes of events, some of which are further organised into sub-categories that share characteristics or can be considered the same for the purposes of the work. The subdivision of the dataset into subfolders facilitates the adaptation of the dataset to suit specific objectives of other potential users.
The main purpose of these datasets is to train, validate and test neural networks capable of recognising sound events. This can be used either to search for specific sounds in the environment, or to identify sounds to be removed from a larger track. Either purpose would avoid the need for manual identification, which is often costly and impractical. The main focus is on environmental acousticians who make long noise measurements and need to label specific sounds or remove unwanted sounds. At the same time, they may be of interest to, for example, ecologists studying bird/animal populations, who will collect thousands of hours of field recordings, but whose measurements will certainly be affected by many unwanted sounds that need to be removed15.
The work’s notable strengths lie in the rigorous methodology employed, with all samples drawn from both short and long measurements obtained from either online repositories or by the authors themselves using Class I sound level meters. Furthermore, the authors subjected all the processed audio files, amounting to around 35 hours of audio samples (around 18 from DataSEC and 17 from DataSED), to meticulous listening, review and processing, resulting in a more descriptive and refined dataset.
Each track in DataSEC may comprise a single event or multiple events of a single sound class. Conversely, DataSED consists of individual recordings or multiple sounds, either from the same class or from different classes, over a more protracted duration and accompanied by background noise. DataSED is uploaded in two versions. The first version does not contain overlapping events of different classes, such that each moment in time is assigned to a single class only. In contrast, the second version incorporates overlapping events from multiple classes, thereby providing a more realistic representation of real-world conditions. These two versions are offered to support the development and evaluation of two types of applications: monophonic sound detection and polyphonic sound detection31. To mitigate the subjectivity inherent in the labelling process, the authors have performed ground truth annotations according to the 22 class divisions on the SED dataset, ensuring consistent evaluation. While all audio files are in .wav format, the ground truth labelling is in .csv format. The SEC and SED datasets consist of 4292 and 712 .wav files, respectively. The SED dataset comprises 4034 grounds in its polyphonic version and 4309 labels in its monophonic version.