
Microsoft has disclosed details of a novel side-channel attack targeting remote language models that could enable a passive adversary with capabilities to observe network traffic to glean details about model conversation topics despite encryption protections under certain circumstances.
This leakage of data exchanged between humans and streaming-mode language models could pose serious risks to the privacy of user and enterprise communications, the company noted. The attack has been codenamed Whisper Leak.
“Cyber attackers in a position to observe the encrypted traffic (for example, a nation-state actor at the internet service provider layer, someone on the local network, or someone connected to the same Wi-Fi router) could use this cyber attack to infer if the user’s prompt is on a specific topic,” security researchers Jonathan Bar Or and Geoff McDonald, along with the Microsoft Defender Security Research Team, said.
Put differently, the attack allows an attacker to observe encrypted TLS traffic between a user and LLM service, extract packet size and timing sequences, and use trained classifiers to infer whether the conversation topic matches a sensitive target category.
Model streaming in large language models (LLMs) is a technique that allows for incremental data reception as the model generates responses, instead of having to wait for the entire output to be computed. It’s a critical feedback mechanism as certain responses can take time, depending on the complexity of the prompt or task.

The latest technique demonstrated by Microsoft is significant, not least because it works despite the fact that the communications with artificial intelligence (AI) chatbots are encrypted with HTTPS, which ensures that the contents of the exchange stay secure and cannot be tampered with.
Many a side-channel attack has been devised against LLMs in recent years, including the ability to infer the length of individual plaintext tokens from the size of encrypted packets in streaming model responses or by exploiting timing differences caused by caching LLM inferences to execute input theft (aka InputSnatch).
Whisper Leak builds upon these findings to explore the possibility that “the sequence of encrypted packet sizes and inter-arrival times during a streaming language model response contains enough information to classify the topic of the initial prompt, even in the cases where responses are streamed in groupings of tokens,” per Microsoft.
To test this hypothesis, the Windows maker said it trained a binary classifier as a proof-of-concept that’s capable of differentiating between a specific topic prompt and the rest (i.e., noise) using three different machine learning models: LightGBM, Bi-LSTM, and BERT.
The result is that many models from Mistral, xAI, DeepSeek, and OpenAI have been found to achieve scores above 98%, thereby making it possible for an attacker monitoring random conversations with the chatbots to reliably flag that specific topic.
“If a government agency or internet service provider were monitoring traffic to a popular AI chatbot, they could reliably identify users asking questions about specific sensitive topics – whether that’s money laundering, political dissent, or other monitored subjects – even though all the traffic is encrypted,” Microsoft said.
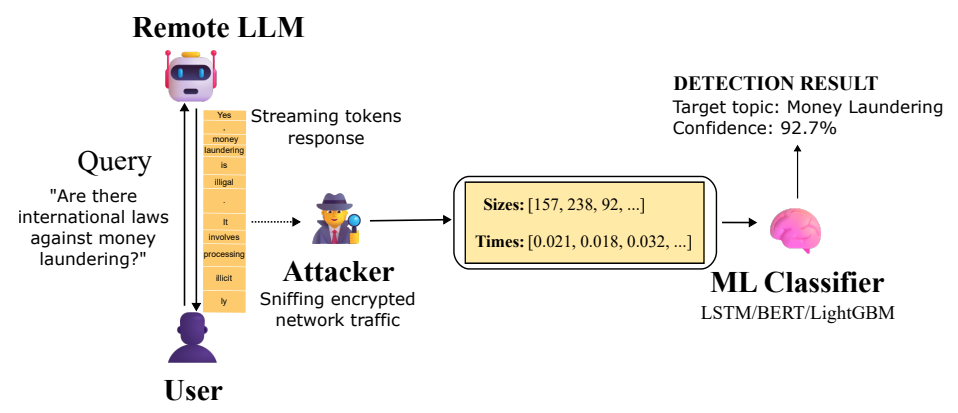 Whisper Leak attack pipeline
Whisper Leak attack pipeline
To make matters worse, the researchers found that the effectiveness of Whisper Leak can improve as the attacker collects more training samples over time, turning it into a practical threat. Following responsible disclosure, OpenAI, Mistral, Microsoft, and xAI have all deployed mitigations to counter the risk.
“Combined with more sophisticated attack models and the richer patterns available in multi-turn conversations or multiple conversations from the same user, this means a cyberattacker with patience and resources could achieve higher success rates than our initial results suggest,” it added.
One effective countermeasure devised by OpenAI, Microsoft, and Mistral involves adding a “random sequence of text of variable length” to each response, which, in turn, masks the length of each token to render the side-channel moot.

Microsoft is also recommending that users concerned about their privacy when talking to AI providers can avoid discussing highly sensitive topics when using untrusted networks, utilize a VPN for an extra layer of protection, use non-streaming models of LLMs, and switch to providers that have implemented mitigations.
The disclosure comes as a new evaluation of eight open-weight LLMs from Alibaba (Qwen3-32B), DeepSeek (v3.1), Google (Gemma 3-1B-IT), Meta (Llama 3.3-70B-Instruct), Microsoft (Phi-4), Mistral (Large-2 aka Large-Instruct-2047), OpenAI (GPT-OSS-20b), and Zhipu AI (GLM 4.5-Air) has found them to be highly susceptible to adversarial manipulation, specifically when it comes to multi-turn attacks.
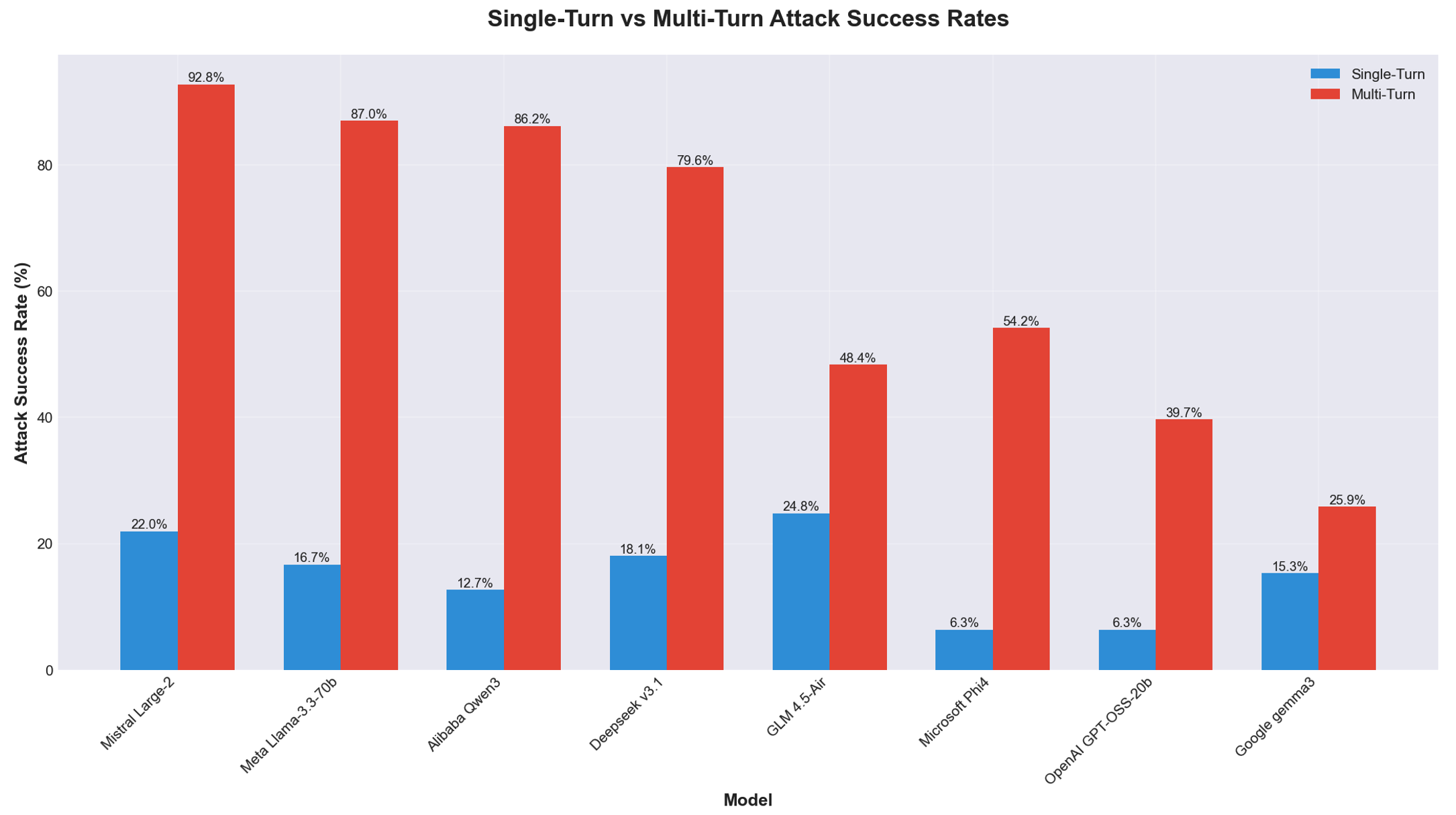 Comparative vulnerability analysis showing attack success rates across tested models for both single-turn and multi-turn scenarios
Comparative vulnerability analysis showing attack success rates across tested models for both single-turn and multi-turn scenarios
“These results underscore a systemic inability of current open-weight models to maintain safety guardrails across extended interactions,” Cisco AI Defense researchers Amy Chang, Nicholas Conley, Harish Santhanalakshmi Ganesan, and Adam Swanda said in an accompanying paper.
“We assess that alignment strategies and lab priorities significantly influence resilience: capability-focused models such as Llama 3.3 and Qwen 3 demonstrate higher multi-turn susceptibility, whereas safety-oriented designs such as Google Gemma 3 exhibit more balanced performance.”
These discoveries show that organizations adopting open-source models can face operational risks in the absence of additional security guardrails, adding to a growing body of research exposing fundamental security weaknesses in LLMs and AI chatbots ever since OpenAI ChatGPT’s public debut in November 2022.
This makes it crucial that developers enforce adequate security controls when integrating such capabilities into their workflows, fine-tune open-weight models to be more robust to jailbreaks and other attacks, conduct periodic AI red-teaming assessments, and implement strict system prompts that are aligned with defined use cases.