

Introduction
a data company really grow?
This week what would have been news a year ago was no longer news. Snowflake invested in AtScale, a provider of semantic layer services in a strategic investment in the waning company’s history. An odd move, given the commitment to the open semantic interchange or “OSI” (yet another acronym or .yaa) which appears to be metricflow masquerading as something else.
Meanwhile, Databricks, the AI and Data company, invested in AI-winner and all-round VC paramore Loveable — the rapidly growing vibe-coding company from Sweden.
Starting a venture arm is a tried-and-tested route for enterprises. Everybody from Walmart and Hitachi to banks like JPMorgan and Goldman Sachs, and of course the hyperscalers — MSFT, GOOG — themselves have venture arms (though strangely not AWS).
The benefits are clear. An investment into a round can give the right of first refusal. It offers both parties influence around complementary roadmap features as well as clear distribution advantages. “Synergy” is the word used in boardrooms, though it is the less insidious and friendly younger brother of central cost cutting so prevalent in PE rather than venture-backed businesses.
It should therefore come as no surprise to see that Databricks are branching out outside of Data. After all (and Ali has been very open about this), the team understands the way to grow the company is through new use cases, most notably AI. While Dolly was a flop, the jury is out on the partnership with OpenAI. AI/BI, as well as Databricks Applications, are promising initiatives designed to bring more friends into the tent — outside of the core SYSADMIN cluster administrators.
Snowflake meanwhile may be trying a similar tack but with differing levels of success. Aside from Streamlit, it is not clear what value its acquisitions are truly bringing. Openflow, Neolithic Nifi under-the-hood, is not well received. Rather, it is the internal developments such as the embedding of dbt core into the Snowflake platform that appear to be gaining more traction.
In this article, we’ll dive into the different factors at play and make some predictions for 2026. Let’s get stuck in!
Growth through use cases
Databricks has a problem. A big problem. And that is equity.
As the fourth-largest privately held company in the world, at the tender age of 12 its employees require liquidity. And liquidity is expensive (see this excellent article).
To make good on its internal commitments, Databricks needed perhaps $5bn+ when it did this raise. The amount it needs per year is significant. It is therefore simply not an option to cease raising money without firing employees and cutting costs.
The growth is staggering. In the latest series L (!) the company cites 55% yearly period-on-period growth leading to a valuation of over $130bn. The company must continue to raise money to pay its opex and equity, but there is another constraint which is valuation. At this point Databricks’ ability to raise money is practically a bellwether for the industry, and so there is a vested interest for everyone involved (the list is enormous) to keep things up.
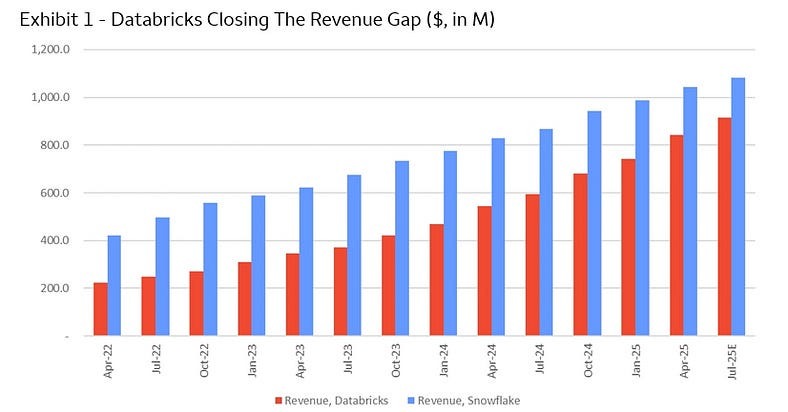 Source: previous article
Source: previous article
The dream is to continue growing the company as this will sustain the valuation — valuations are tied to revenue growth. Which brings us back to use cases.
The clear use cases, as shown here, are roughly:
Big data processing and spark
Within this, Machine Learning workloads
AI workloads
Data warehousing
Ingestion or Lakeflow (Arcion we suspect was perhaps a bit early)
Business Intelligence
Applications
It’s worth noting these sectors are all forecasted to grow at around 15–30% all in, per the vast majority of market reports (an example here). This reflects the underlying demand for more data, more automation, and more efficiency which I believe is ultimately justified, especially in the age of AI.
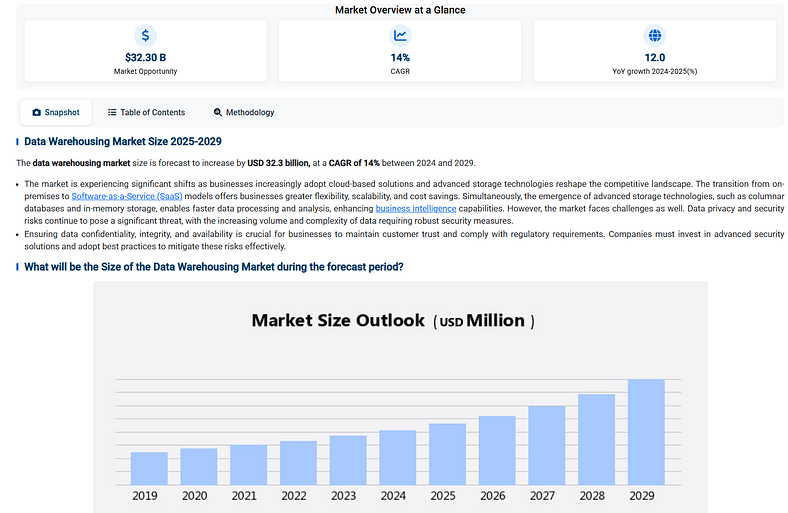 Sources like Technavio, Mordor Intelligence, and often just plain old Commercial Due Diligence Reports rarely disagree with each other, with almost all of the them putting the safe 15–30% range in sectors people think should be invested in. The point is; this is not a stagnant or a rocketing market, and they all agree. In contrast to, for example, AI
Sources like Technavio, Mordor Intelligence, and often just plain old Commercial Due Diligence Reports rarely disagree with each other, with almost all of the them putting the safe 15–30% range in sectors people think should be invested in. The point is; this is not a stagnant or a rocketing market, and they all agree. In contrast to, for example, AI
It would appear to indicate, therefore, that the bottom or “floor” for Databricks would be about a growth of 15–30%, and with it perhaps a 40% haircut to valuation multiples (assuming linear correlation; yes, yes, assumptions, assumptions — some more info here), barring of course any exogenous shocks to the system such as OpenAI going out of business or war.
This is hardly concerning as a bear-case, which makes me wonder — what is the bull?
The bull lies in the two A’s: AI use cases and Applications.
AI as a way out
If Databricks can successfully partner with the model providers and become the de-facto engine for hosting models and running the associated workflows, it could be massive.
Handkerchief maths — the revenue is $4.8bn RR growing at 55%. Say we’re growing at 30% in steady state, we’re missing 25%. 25% of $4.8 is $1.2bn. Where can this come from? Supposedly existing AI products and existing warehousing is already over $2bn (see here). What happens next year when Databricks is at $6bn and we need to grow 50% and therefore need $3bn? Is the business going to double the AI part?
Confluent is a benchmark. It is the largest Kafka/stream processing company, with a revenue of about $1.1bn annualised. It grows about 25% y-o-y but traded at about 8x revenue and sold to IBM for $11bn, so about 11x revenue. Even with its loyal fanbase and strong adoptions for AI use cases (see for example marketecture from Sean Falconer.), it would still struggle to put another $250m of annual growth on every year.
Applications are another story. Those that build data-intensive applications are not those that generally build internal-facing products, a task often borne by in-house teams of software engineers or consultants. These are teams that already know how to do this, and know how to do it well, with existing technology specifically designed for its purpose, namely core engineering primitives like React, Postgres (self-hosted) and Fast API.
 Dashboards with a twist? Source
Dashboards with a twist? Source
A data engineer could log in to Loveable, spin up Neon-Postgres, a declarative spark ETL pipeline, and front-end in Databricks. They could. But will they want to add this to their ever-increasing backlog? I am not sure.
The point is the core business is not growing fast enough to sustain the current valuation so additional lines of business are required. Databricks is like a golden goose at the craps table, who continues to avoid rolling the unutterable number. They can now continue making more and more bets, while all those around the table continue to benefit.
Databricks is topped out as a data-only company.
We’ve written before about ways they could have moved out of this. Spark-structured streaming was an obvious choice, but the ship has sailed, and it is companies like Aiven and Veverica that are now in pole position for the Flink race.
📚 Read: What not to miss in Real-time Data and AI in 2025 📚
To become a model-serving company or an ‘AI Cloud’ seems also a tall order. Coreweave, Lambda, and of course Nebius are all on track to really challenge the hyperscalers here.
An AI cloud is fundamentally driven by a high availability of GPU-optimised compute. This doesn’t just mean leasing EC2 instances from Jeff Bezos. It means sliding into Jensen Huang’s DMs and buying a ton of GPUs.
Nebius has about 20,000, with another 30,000 on the way — this Yahoo report thinks the numbers are higher. All the AI Clouds lease space in data centres as well as building their own. Inference, unlike spark, is not a commodity because of the immense software, hardware, and logistical challenges required.
Let us not forget that Nebius owns just over 25% of Clickhouse — both teams being very software engineering-led and Russian; the Yandex Alumni Club.
If there is one thing we have learned it is that it is easier to go up the value chain than down it. I wrote about this funnel perhaps two years ago now but it seems truer than ever.
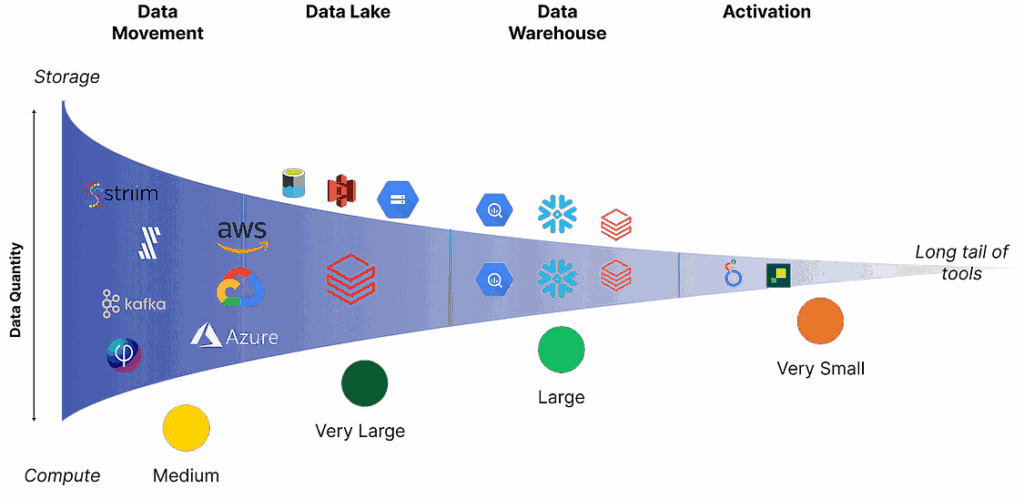 Who remembers this from my early blogging days? Read: Unstructured Data funnel
Who remembers this from my early blogging days? Read: Unstructured Data funnel
Snowflake easily eats into dbt. Databricks has easily eaten into Snowflake’s warehouse revenue. Microsoft will eat into Databricks’. And in turn, with raw data centre power, NVIDIA and Meta partnerships, and an army of the best developers in the business, Nebius can eat into the hyperscalers.
Data warehousing under attack
With every passing day proprietary data warehousing platforms seem more and more unlikely to be the technical end for AI and Data infrastructure.
Salesforce are increasing levies, databases are supporting cross-query capabilities, CDOs are running Duck DB in Snowflake itself.
Even Bill Inmon acknowledges warehousing companies missed the warehousing!
While convenient, there is a scale at which enterprises and even late stage start-ups are demanding greater openness, greater flexibility and cheaper compute.
At Orchestra we’ve seen this first-hand. The companies looking at technologies such as Iceberg are overwhelmingly massive. From the largest telecom providers to the Booking.com’s of this world (who happen to use and love Snowflake; more on this later), traditional data warehousing is unlikely to continue dominating the share of budget it has done for the last decade.
There are a few ways Snowflake has also tried to expand its core offering:
Support for managed iceberg; open compute engine
Data cataloging (Select *)
Applications (streamlit)
Spark and other forms of compute like containers
AI agents for Analysts AKA snowflake intelligence
Transformation (i.e. dbt)
Ironically for a proprietary engine provider, it would appear that Iceberg is a large growth avenue, as well as AI. See more from TT here.
Snowflake customers love it.
Data Pangea
I think the definitions of the pioneers, early adopters, late adopters, and laggards are changing.
Early Adopters now include a heavy real-time component and AI-first approach to the stack. This is likely to revert to Machine Learning as people realise AI is not a hammer for every nail.
These companies want to partner with a few large vendors, and have a high appetite for building as well as buying software. They will have at least one vendor in the streaming/AI, query engine and analytics space. A good example is booking.com, or perhaps Fresha, who uses Snowflake, Starrocks, and Kafka (I loved the article below).
📚 Read: Exploring how modern streaming tools power the next generation of analytics with StarRocks. 📚
Early Adopters will have the traditional analytics stack and then one other area. They lack the scale to fully buy-in to an enterprise-wide data and AI strategy, so focus on those use-cases they know work. Automation, Reporting.
The old “early adopters” would have had the Andreesen Horowitz data stack. That, I am afraid, is no longer cool, or in. That was the old architecture. The late adopters have the general stack.
The laggards? Who knows. They will probably go with whoever their CTO knows the most. Be it Informatica (see this incredible reddit post), Fabric, or perhaps even GCP!
The next step: chaos for smaller vendors
A lot of companies are changing tack. Secoda were acquired by Atlassian, Select Star were acquired by Snowflake. Arch.dev, the creators of Meltano, shut-down and passed the project to Matatika. From the large companies to the small, slowing revenue growth combined with massive pressure from bloated VC rounds make building a “Modern-Data Stack”-style company an untenable approach.
📚 Read: The Final Voyage of the Modern Data Stack | Can the Context Layer for AI provide catalogs with the last chopper out of Saigon? 📚
What would happen when the Databricks and Snowflake growth numbers finally start to slow, as we argue they should here?
What would happen if there was a large exogenous market shock or OpenAI ran out of money faster than expected?
What happens as Salesforce increase taxes and hence tools like Fivetran and dbt increase in price even more?
A perfect storm for migrations and re-architecturing is brewing. Data infrastructure is extremely sticky, which means in difficult times, companies raise prices. EC2 spot instances have not really changed much in price over the years, and so neither too has data infra compute — and yet even AWS are raising prices of GPUs.
The marginal cost of onboarding an additional tool is becoming very high. We used to build everything ourselves as it was the only way. But having one tool for every problem doesn’t work either.
 Image the author’s
Image the author’s
We should not forget that Parkinson’s law applies to IT budgets too. Whatever the budget is, the budget will get spent. Imagine if you had a tool that helped you automate more things with AI while reducing your wareouse bill and reducing your BI Licenses (typically a large 25–50% P&L budget line) — what do you do?
You don’t pat yourself on the back — you spend it. You spend it on more stuff, doing more stuff. You will probably push your Databricks and Snowflake bill back up. But you will have more to show for it.
Consolidation is driving funds back into centre of gravities. These are Snowflake, Databricks, GCP, AWS and Microsoft (and to a lesser extent, palantir). This spells chaos for most smaller vendors.
Conclusion — brace for simpler architecture
The Salesforce Tax is a pivotal moment in our industry. Companies like Salesforce, SAP, and ServiceNow all have an immense amount of data and enough clout to keep it there.
As Data People, anyone who has done a migration from Salesforce to Netsuite knows that migrating these tools is probably the biggest, most expensive, and most painful move anyone faces in their professional careers.
Salesforce charging infrastructure service providers fees will raise prices, which in turn, combined with the increasingly precarious house of cards we see in AI and Data, all point towards massive consolidation.
ServiceNow’s acquisition of Data.World, I think, provides some clarity into why we’ll see data teams make more use of existing tooling, simplifying architecture in the process. Data.World is a provider of knowledge graphs and ontologies. By mapping the ServiceNow data schema to an ontology, a gargantuan task, ServiceNow could end up with half-decent AI and agents running within ServiceNow.
AgentForce and Data360 is Salesforce’s attempt, and supposedly already has $1.4bn in revenue, though we suspect it includes a lot of legacy in there too.
These providers do not really want data running around as AI use cases in Snowflake or Databricks. They want the Procurement Specialists, Finance Professionals, and Marketing Gurus staying in their platforms — and they have the means to make them stay.
This is not financial advice and this is not a crazy prediction. To predict that Snowflake and Databricks will end up growing more along the analyst consensus is hardly challenging.
But the idea that the biggest data companies’ growth is on the verge of slowing is challenging. It challenges the rhetoric. It challenges the AI maximalist discourse.
We are entering the era of the Great Data Closure. While the AI maximalists dream of a borderless future, the reality is a heavy ceiling built by the incumbents’ gravity. In this new landscape, the winner isn’t the one with the best set of tools, but the people that make the most of what they have.
About Me
I’m the CEO of Orchestra. We help Data People build, run and monitor their pipelines easily.
You can find me on Linkedin here.