
Researchers from Beijing University of Posts and Telecommunications and China Telecom, et al. published a research paper in the special issue “Computing and Network Convergence: Architecture, Theory and Practice” of Frontiers of Information Technology & Electronic Engineering (FITEE), Vol. 25, No. 5, 2024. To improve the communication efficiency of federated learning in complex network environments, the paper studies its communication efficiency optimization methods in 6G computing power networks, making decisions on the training process for different network conditions and computing power of participating devices.
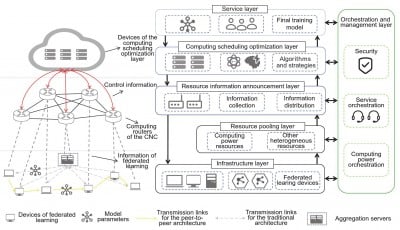
The paper introduces two architectures of federated learning. Clients in the traditional architecture receive the global model from the server; in the peer-to-peer architecture, federated learning is suitable for direct collaborative training among multiple data providers, where there is no central server, and all interactions occur directly between the participating clients. The most rudimentary scenario entails the presence of merely two client devices. Based on these two architectures, the communication efficiency optimization of 6G network computing and network convergence (CNC) is proposed, which divides CNC into an infrastructure layer, a resource pooling layer, a resource information announcement layer, a computing scheduling optimization layer, a service layer, and an orchestration and management layer. The core of the whole structure is the coordinated operation of the upper equipment in CNC, which optimizes the training process of federated learning based on the network, computing power resources, and other information.
The specific mathematical problems based on the two architectures of federated learning cover convergence, transmission, and local training related problems. In the convergence problem, the loss function and the optimization goal of the optimal global model are defined; the transmission problem discusses the uplink transmission delay, energy consumption, and resource block allocation in the traditional architecture, as well as the transmission energy consumption or delay between clients in the peer-to-peer architecture; the local training related problem focuses on the local training delay based on the computing power of devices and finds a suitable subset of clients to participate in federated learning.
Optimization methods under the two architectures of federated learning are provided. For the traditional architecture, devices are grouped according to computing power, the resource pooling layer is used to manage heterogeneous resources, and the Hungarian algorithm is adopted to optimize resource block allocation; under the peer-to-peer architecture, all clients are arranged to participate in global training, client subsets are allocated according to computing power and network conditions, the best transmission path is found, and sub-models are aggregated to obtain a new global model.
Experiments use the MNIST dataset and a simple neural network as the training model, simulating both independent and identically distributed (IID) and non-independent and identically distributed (Non-IID) client data distribution scenarios to verify the performance of the method. In the Non-IID scenario, the trained global model converges slowly, has low accuracy, and the training curve fluctuates. However, compared with classic methods such as FedAvg, the proposed CNC optimization method performs better in reducing transmission energy consumption, delay, and local training delay. Experimental results show that this method can effectively enhance the communication efficiency of federated learning in 6G networks.
The paper “Communication efficiency optimization of federated learning for computing and network convergence of 6G networks” authored by Yizhuo CAI, Bo LEI, Qianying ZHAO, Jing PENG, Min WEI, Yushun ZHANG and Xing ZHANG. Full text of the open access paper: https://doi.org/10.1631/FITEE.2300122.