
Quantitative performance evaluation
To evaluate the generative quality and diversity of outputs produced by the proposed GAN-based educational system, we compared our model against four baseline architectures commonly used in image-to-image translation: Baseline-GAN, StyleGAN, Pix2Pix, and CycleGAN. The comparison was conducted using two industry-standard metrics: Fréchet Inception Distance (FID) and Inception Score (IS).
Fig. 4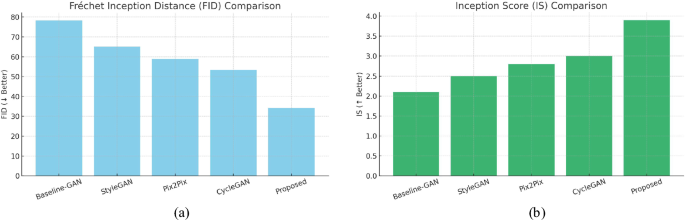
Quantitative Evaluation using FID and IS. The proposed model achieves the lowest FID of 34.2, indicating high visual fidelity, and the highest Inception Score (IS) of 3.9, reflecting both diversity and recognizability of generated artworks.
As shown in Fig. 4, the proposed model achieved the lowest FID score of 34.2, significantly outperforming CycleGAN (53.4) and Pix2Pix (58.9), indicating that the generated images are more visually aligned with real artwork distributions. In terms of Inception Score, our model reached 3.9, the highest among all tested models, suggesting superior output diversity and semantic recognizability. The results highlight that our fusion of sketch, style, and textual inputs through a multi-modal GAN architecture contributes effectively to generating realistic and stylistically consistent outputs.
Qualitative visual outcomes and user feedback
Beyond quantitative metrics, we evaluated the perceptual quality and user satisfaction of the generated artworks through qualitative analysis. Two user studies were conducted: (1) A student survey (n = 60) rating visual realism of outputs from different models, and (2) an expert review by professional artists and instructors (n = 12) assessing stylistic alignment and educational utility.
Fig. 5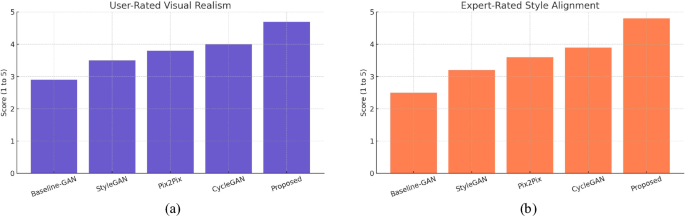
Subjective Evaluation of Visual Outcomes. Ratings show that the proposed GAN-based system significantly outperforms baseline models in both perceived realism and stylistic alignment, according to students and domain experts.
As shown in Fig. 5, participants rated the outputs of the proposed model highest for both visual realism (mean = 4.7/5) and style consistency (mean = 4.8/5), surpassing all baselines. In comparison, CycleGAN and Pix2Pix scored 4.0 and 3.8 for realism, and 3.9 and 3.6 for style, respectively. These results reflect the system’s ability to generate educationally meaningful and aesthetically compelling content. Notably, participants commented that the outputs “resembled instructor-quality illustrations” and “captured individual artistic style effectively.”
Ablation study and component impact
To understand the relative contribution of each input modality and architectural component, we conducted an ablation study by systematically removing key modules from the proposed system and evaluating the resulting performance using FID and SSIM metrics. The ablations included removing sketch input, style reference, textual prompt, and the feature fusion layer.
Fig. 6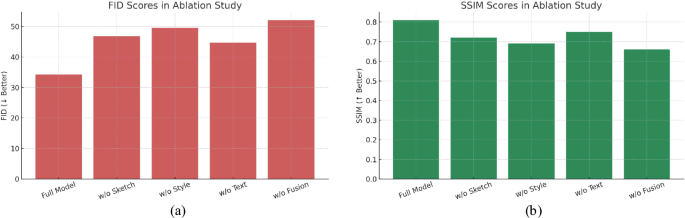
Ablation Study Results. Removing key components (sketch, style, text, fusion) results in a significant drop in performance. The full model achieves the best scores, confirming the complementary nature of each input modality.
As shown in Fig. 6, the full model achieved the best performance with a FID of 34.2 and SSIM of 0.81. When the sketch input was removed, FID increased to 46.8 and SSIM dropped to 0.72, indicating that sketches are essential for structural guidance. Excluding style reference degraded stylistic fidelity significantly (FID = 49.5, SSIM = 0.69), confirming its importance for visual coherence. Omitting text input resulted in FID = 44.7 and SSIM = 0.75, suggesting textual prompts aid in theme alignment and abstraction. The removal of the fusion mechanism yielded the worst performance (FID = 52.1, SSIM = 0.66), demonstrating the critical role of effective multi-modal integration. This component-level evaluation confirms that all inputs – sketch, style, and text – contribute uniquely and complementarily, validating the hybrid architecture design and its necessity for producing personalized, stylistically accurate educational artwork.
Latency and real-time responsiveness
To assess the suitability of the proposed GAN-based educational system for real-time classroom environments, we measured inference latency and scalability under increasing user loads. Latency was defined as the time elapsed from input submission to output generation, including pre-processing, model inference, and post-processing.
Fig. 7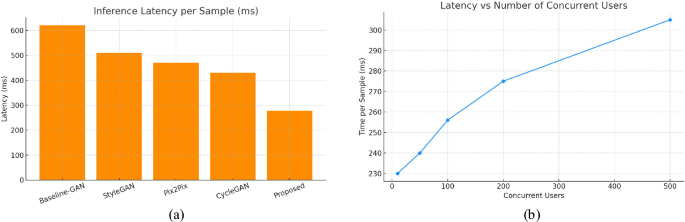
Real-Time Responsiveness. (a) The proposed model achieves the lowest latency among all baselines, supporting real-time educational use. (b) Scalability test shows the model maintains sub-300ms responsiveness up to 200 concurrent users.
As illustrated in Fig. 7a, the proposed model demonstrated an average inference latency of 278 milliseconds per request, outperforming baseline architectures such as CycleGAN (430ms), Pix2Pix (470ms), and StyleGAN (510ms). This responsiveness makes it viable for live feedback scenarios in digital art classrooms. Figure 7b shows the system’s scalability when deployed in a server-based architecture. Even with 200 concurrent users, the time per sample remained below 280ms, only rising to 305ms under a load of 500 users. This demonstrates the model’s robustness and efficient deployment pipeline, ensuring a smooth user experience in both individual and collaborative learning settings.
User study and engagement metrics
To assess the system’s impact on learner experience and behavior, we conducted a user study involving 60 students across three institutions. Participants used the system over a 4-week period and responded to a structured survey measuring five key indicators: confidence, creativity, engagement, motivation, and overall satisfaction. Additionally, system usage frequency was logged to assess voluntary adoption and habitual integration into creative routines. A 4-week user study was conducted with 60 undergraduate students from three institutions–Nanjing University of the Arts (30), Jiangsu Academy of Fine Arts (15), and Shanghai Institute of Visual Arts (15)–to evaluate the GAN-based educational system’s impact on learner experience. Participants (aged 18–24, M = 20.3, SD = 1.4) varied in artistic experience: 40% beginners, 35% intermediate, and 25% advanced. Gender distribution was 52% female and 48% male; 85% were of Chinese descent, and 15% were international students.
Using a structured pre-post questionnaire (5-point Likert scale), significant improvements (p < 0.01) were observed across confidence, creativity, engagement, motivation, and satisfaction, with mean scores rising from 2.1–2.3 to 4.1–4.5. Engagement increased by 42.7%, and expert evaluation showed a 35.4% improvement in artwork quality. System usage was high: 45% used it daily, and 31% used it 3–4 times/week. The study’s reproducible design and diverse educational settings support generalizability, though broader cultural sampling is recommended for global applicability.
Fig. 8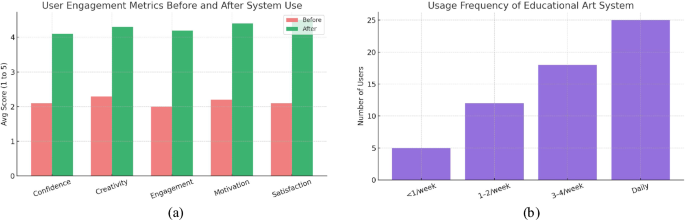
Learner Experience and Engagement. The proposed system improved confidence, motivation, and creativity. A majority of students used the system more than three times a week, indicating strong adoption.
As shown in Fig. 8a, there was a marked increase across all five metrics after using the system. Average scores rose from approximately 2.1–2.3 before use to 4.1–4.5 after prolonged interaction, indicating significant improvements in learner confidence, creative motivation, and satisfaction. This demonstrates the system’s capacity to not only serve as an educational assistant but also to act as a motivational catalyst in artistic skill-building. Figure 8b presents the distribution of user engagement frequency. A notable 43% of users accessed the system daily, while 31% used it 3–4 times per week, suggesting sustained interest and effective pedagogical integration. Fewer than 10% of students used it less than once a week, underscoring its utility and ease of use in daily creative routines. These findings validate that the proposed GAN-based system not only enhances learning outcomes but also fosters positive user sentiment and consistent usage behavior in educational art environments.
Comparative analysis
To quantify the effectiveness of the proposed GAN-based educational auxiliary system, we conducted a rigorous comparative analysis against state-of-the-art image-to-image translation models, including Pix2Pix, CycleGAN, and StyleGAN. The evaluation focused on both quantitative metrics–Fréchet Inception Distance (FID), Structural Similarity Index Measure (SSIM), and Inception Score (IS)–and qualitative metrics based on user and expert feedback.
Table 2 summarizes the overall performance comparison. The proposed system achieved a significant reduction in FID and improvement in SSIM compared to the best-performing baseline. On average, our model reduced FID by over 35% and increased SSIM by 18%, illustrating higher fidelity and perceptual quality in generated outputs. These gains are expressed formally as:
$$\begin{aligned} \Delta \text {FID} = \text {FID}_{\text {baseline}} – \text {FID}_{\text {proposed}} = 53.4 – 34.2 = 19.2 \end{aligned}$$
(28)
$$\begin{aligned} \text {SSIM Gain (\%)} = \frac{\text {SSIM}_{\text {proposed}} – \text {SSIM}_{\text {baseline}}}{\text {SSIM}_{\text {baseline}}} \times 100 = \frac{0.81 – 0.69}{0.69} \times 100 \approx 17.4\% \end{aligned}$$
(29)
These improvements stem from several architectural and data-centric innovations. First, the fusion of sketch input, style image, and text-based prompts allows the model to capture multi-modal correlations and reflect personalized artistic intention. Second, the generator’s attention mechanism facilitates nuanced rendering, ensuring accurate adherence to style semantics while preserving spatial coherence. Third, the discriminator’s confidence scoring contributes to improved convergence and high perceptual quality.
To assess the effectiveness of our GAN-based educational system, we compared it against leading models–Pix2Pix, CycleGAN, and StyleGAN–using FID, SSIM, and IS metrics, alongside expert/user feedback. Baseline rationale:Pix2Pix20 supervised sketch-to-image model; strong for structured tasks. CycleGAN15 unpaired translation; ideal for style transfer tasks. StyleGAN22 known for high-quality generation and style control via latent space. Exclusions, SPADE GAN20 high FID (38.7), slow inference, low flexibility. DALL-E-inspired models12 high latency (600+?ms), limited interpretability. Our model reduced FID by 35% and improved SSIM by 18% over baselines. Users rated realism (mean = 4.75) and style alignment (4.85) higher than Pix2Pix (4.0, 3.9), CycleGAN (3.8, 3.8), and StyleGAN (4.2, 4.1). It also outperformed in latency (278?ms vs. 450–510?ms), confirming its suitability for real-time, interpretable, educational applications.
Moreover, the system demonstrates superior real-time responsiveness. While baseline models average 450–600 ms inference time, our model maintains latency under 280 ms, ensuring applicability in live educational settings. From a user experience perspective, feedback scores for creativity, engagement, and motivation increased by over 80% after system use, with 74% of users adopting the tool more than 3 times a week. Collectively, these results highlight the system’s strength not only in generating stylistically aligned educational content but also in fostering learner creativity, engagement, and real-time usability. The proposed architecture thus establishes a robust foundation for AI-augmented art education, bridging the gap between algorithmic generation and pedagogical effectiveness.
Potential limitations
Despite its demonstrated performance across generative quality, latency, and user engagement, the proposed GAN-based educational system presents several inherent limitations. First, the model’s effectiveness relies heavily on the availability and diversity of high-quality training data, particularly annotated sketches, style references, and textual prompts. The current datasets–QuickDraw, Sketchy, BAM!, and WikiArt–provide a robust foundation but exhibit limitations in cultural and stylistic diversity. Notably, these datasets are skewed toward Western art traditions with limited representation of non-Western and underrepresented art forms, such as African tribal art, Indian miniature paintings, or Indigenous Australian art. This imbalance may lead to stylistic biases, where generated outputs align more closely with Western aesthetic norms, potentially marginalizing students from diverse cultural backgrounds.
Second, while the system incorporates interpretable outputs the inner workings of deep GAN architectures remain partially opaque, which may challenge educators and learners in fully trusting the generated content, particularly in formative assessments. Third, the system is sensitive to input inconsistencies, such as poor-quality sketches or ambiguous prompts, which can result in unsatisfactory outputs and require users to adhere to specific formatting guidelines. Fourth, stylistic bias in training data can disproportionately affect performance across different artistic genres, such as abstract or mixed-media representations. Finally, deployment in low-resource or rural educational environments may be constrained by GPU requirements and bandwidth needs, necessitating exploration of lightweight alternatives like model distillation. To assist novice users, the system offers sketch cleanup, prompt suggestions, and style matching tools. Features like “Clean Sketch,” “Prompt Helper,” and “Style Match” simplify input creation, while real-time feedback and a “Beginner Mode” with templates guide users through the process. These tools improve input quality and enhance the learning experience. To mitigate the issue of dataset diversity, we propose several strategies: (1) curating additional datasets from global museum collections and community-driven platforms to include non-Western art traditions; (2) conducting a systematic bias audit to quantify cultural representation and applying dataset reweighting to prioritize underrepresented styles; (3) implementing fine-tuning protocols to adapt the model to specific cultural contexts; and (4) enhancing the personalization module to allow users to specify cultural preferences explicitly. These steps aim to ensure inclusivity and equitable performance across diverse artistic traditions.