
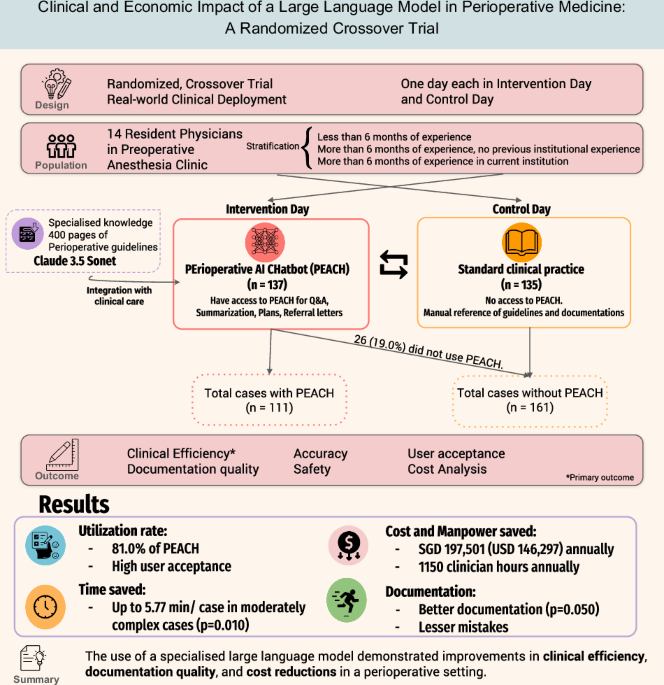
Study design
We conducted a prospective, randomized crossover trial to evaluate the real-world clinical impact of PEACH in a high-volume preoperative evaluation clinic (PEC). The trial was conducted at Singapore General Hospital, a 1900-bedded tertiary academic hospital in Singapore between January and February 202524. The institutional review board waived ethics approval as the intervention was classified as non-human-subjects research under local governance policies.
Prompt engineering
PEACH was developed within the PAIR Chat platform, a large language model optimized for extended-context inputs25,26. PAIR is hosted on the secure Government Commercial Cloud (GCC) and is designed to support healthcare AI applications managing data classified as “Restricted” or “Sensitive,” ensuring enterprise-grade data security. PAIR Chat leverages Claude 3.5 Sonnet (Anthropic, San Francisco, CA)27. Structured perioperative guidelines (Supplementary Table 4) were input directly into the model using document staffing28, which enables comprehensive reasoning across full documents without the need for retrieval modules. This approach allows the model to synthesize and apply context across extensive clinical documentation.
Prompt engineering was a critical component of chatbot design and followed best practices29. Prompts were constructed using role-based instructions, specifying the chatbot’s persona (e.g., senior perioperative clinician or health system analyst). Prompts were iteratively refined through internal testing, response evaluation, and user feedback. This process reduced hallucinations, improved clarity, and aligned outputs with domain-specific expectations. Final prompts emphasized task specificity, contextual relevance, and clinical or administrative nuance (see Supplementary Table 5). PEACH was designed to assist with specific tasks: 1) Question and Answer (Q&A), 2) Summarization and making perioperative plans, and 3) Writing referral letters.
Participants and settings
The trial employed a prospective, two-day randomized crossover design. Resident physicians rotating through the anesthesiology department and scheduled for at least two consecutive days in the preoperative evaluation clinic (PEC) during January and February 2025 were enrolled. A washout period was not implemented due to feasibility constraints in our local context: residents are typically assigned to the PEC for only 2–4 days per rotation, with their next assignment occurring 1–2 months later. Introducing a washout period would risk confounding by capturing residents at different stages of clinical experience, thereby introducing variability in documentation efficiency.
Participants varied in their prior exposure to institutional perioperative protocols and the electronic health record (EHR) system. The PEACH system had been available for informal use starting one month before study initiation. At our institution, anesthesiology residents rotate every six months, with a new cohort beginning in January. While some residents from the prior cohort had limited exposure to PEACH, no formal training was provided before the study. Upon enrollment, participants received a brief five-minute orientation covering basic access, login, and usage. No extensive onboarding was conducted, as the chatbot was designed to be intuitive and self-directed.
Each participant was randomized to complete two consecutive clinic sessions—one utilizing PEACH (Intervention) and the other following standard workflows without AI assistance (Control). Randomization was conducted using a 1:1 block design and stratified according to participants’ prior anesthesiology and institutional experience. Participants were categorized into three strata: (1) less than 6 months of anesthesiology experience (Novice); (2) physicians with at least 6 months of anesthesiology experience at other institutions but unfamiliar with the local EHR system (New to institution); and (3) experienced resident physicians who had previously completed at least six months of anesthesiology rotations within the study hospital (Experienced). The participants were given a 10-dollar gift voucher for their participation. Given the nature of the intervention, blinding of participants was not feasible, however, the reviewers were blinded.
To reduce the risk of reviewer bias, documentation samples were anonymized and selected to ensure parity across case complexity. Clinical documentation was extracted directly from the electronic health record without reformatting or alteration, preserving the original physician-authored content. While AI-generated text may exhibit subtle stylistic patterns, reviewers were not primed to expect such differences.
During the PEACH day (Intervention), participants accessed PEACH through a secure hospital interface. The extent and manner of PEACH usage were left to the discretion of each participant, who may elect to use the chatbot more frequently or selectively. All interactions with PEACH—including the number of uses and their specific purposes (e.g., summarization and planning, Q&A, or referral drafting)—were recorded and extracted from the system logs. The study team subsequently randomly selected 30 PEACH outputs for the evaluation of accuracy. In the control arm, participants conducted preoperative assessments and completed documentation using standard clinical procedures without access to AI assistance (Fig. 1).
For each patient encounter, three time metrics were recorded based on timestamps from the clinic queuing system and documentation logs within the electronic health record. “Patient time” was defined as the duration from the patient’s entry to exit from the consultation room. “Total time” refers to the entire period required for case review and documentation. “Documentation time” was calculated as the difference between total time and patient time.
Clinical documentation was extracted from the perioperative clinic records and anonymized for blinded evaluation. To account for variability in administrative burden based on case complexity, all cases were stratified into three predefined categories for analysis according to the plans outlined in the documentation. Complexity 1 included ASA I or II patients who required no further clinical interventions. Complexity 2 encompassed cases necessitating minor actions, such as brief consultations with the attending anesthesiologist. Complexity 3 referred to high-acuity cases requiring multidisciplinary coordination, including communication with multiple specialty teams, additional referrals, or changes to the surgical schedule (e.g., cancellations or rescheduling). Full inclusion and exclusion criteria for each category are detailed in Supplementary Table 6. Complexity assignments were made retrospectively by two anesthesiologists on the study team, based on the clinical documentation. The reviewers were blinded to the study arm, and discrepancies were resolved by consensus.
Outcome measures
The primary outcome was clinical efficiency, measured by differences in documentation time per patient between PEACH-assisted and standard workflows. Secondary outcomes included documentation quality, safety and accuracy, user acceptance, and economic impact.
Documentation quality was assessed using a paired-review design. Fifty-six clinical documents (28 pairs) were collected. These cases were matched by case complexity to ensure comparability. All samples were anonymized and independently reviewed by two anesthetists. Reviewers evaluated each documentation pair for the presence of a clinically relevant issues list and identified any minor and major errors in the perioperative management plan. Additionally, reviewers indicated their overall preference between the two outputs in each pair.
User acceptance was evaluated using a structured questionnaire based on the Davis’ Technology Acceptance Model (TAM)30, administered upon study completion. The survey included 5-point Likert-scale items assessing perceived usefulness, ease of use, clarity of reasoning, and intention to use PEACH in future clinical practice.
Economic analysis
An economic evaluation was conducted following the Consolidated Health Economic Evaluation Reporting Standards (CHEERS) guidelines31 to quantify the institutional value of PEACH implementation. The analysis modeled potential cost savings based on observed time reductions in documentation and consultation, extrapolated to an institutional scale, assuming an annual patient volume of 20,000 preoperative assessments. We assumed that the distribution of physician seniority mirrored that observed in the study population.
A simple costing model was used to estimate potential labor cost savings by converting clinician time saved into full-time equivalent (FTE) hours and multiplying by an estimated wage rate of SGD 140 per hour. Concurrently, the operating cost of the LLM (Claude 3.5 Sonnet, Anthropic, San Francisco, CA) was factored in based on token usage and per-token pricing at the time of analysis (SGD 0.00047 per output, assuming 133 tokens per 100 words). The model considered the average number of PEACH outputs generated per patient and projected annual usage volume. To test the robustness of the model, a sensitivity analysis was performed using ±20% variation in key input parameters, including clinician wage rates, output volume per patient, and token pricing.
Sample size calculation
As there were no prior studies evaluating the impact of a clinical decision support tool on documentation efficiency in preoperative settings, we prospectively planned an interim analysis after the enrollment of 12 participants to inform sample size estimation. Before initiating the study, we defined a clinically meaningful reduction in documentation time of 3 min, representing a 30% improvement relative to an estimated average documentation time of 10 min per patient. Assuming a standard deviation of 10 min in documentation time differences, a paired crossover design, a two-sided α of 0.05, and 80% power, an a priori sample size calculation indicated that 88 paired patient encounters would be required to detect this effect.
At interim analysis, the observed standard deviation of documentation time was consistent with this assumption. Additionally, it was found that each participant completed an average of 8 paired patient encounters per session. Based on this, the study proceeded to full enrollment, ultimately including 14 participants (111 paired patient encounters).
All statistical analyses were performed using Python 3.13.2. Paired t-tests were used to compare continuous time metrics between intervention and control arms, while categorical outcomes such as documentation preference were evaluated using Chi-square tests.
During manuscript preparation, the authors used large language models (ChatGPT-4o and DeepSeek) to assist with technical paraphrasing and grammatical refinement. All AI-assisted content was reviewed for scientific accuracy and verified against original data by the study authors.