
The rise in publications addressing the use of general artificial intelligence (GAI), namely large language models (LLMs), for health purposes has generated the need to guide authors on transparent reporting practices1,2. Although LLMs currently dominate, other GAI applications such as diffusion models and large multimodal models are gaining popularity3. One key distinction between GAI and conventional AI is the ability of GAI to create new information based on its training data. Varying methodology and incomplete reporting among studies applying GAI for health purposes compromise the ability of readers to accurately interpret the study findings3, which is a particularly relevant issue when evaluating the effectiveness of complex GAI platforms in a healthcare context.
GAI models are now used to address a variety of research questions across alternative study designs, which require novel reporting guidelines4. While more than 25 reporting guidelines address studies applying artificial intelligence or machine learning in a healthcare context, very few reporting standards apply to studies involving GAI applications in healthcare, while fewer adhere to contemporary methodological standards5,6,7,8. As journal editors adopt these reporting standards, investigators may be encouraged to complete and submit checklists and methodological diagrams to accompany their submissions to optimize the transparent reporting of their methods. Authors applying GAI models in healthcare must therefore carefully identify the most appropriate reporting guideline for their study, as these standards contain tailored items for studies involving GAI models5,6,7,8. The purpose of this article is to summarize current GAI reporting guidelines of contemporary rigor and highlight those that are in development.
Reporting guidelines for GAI
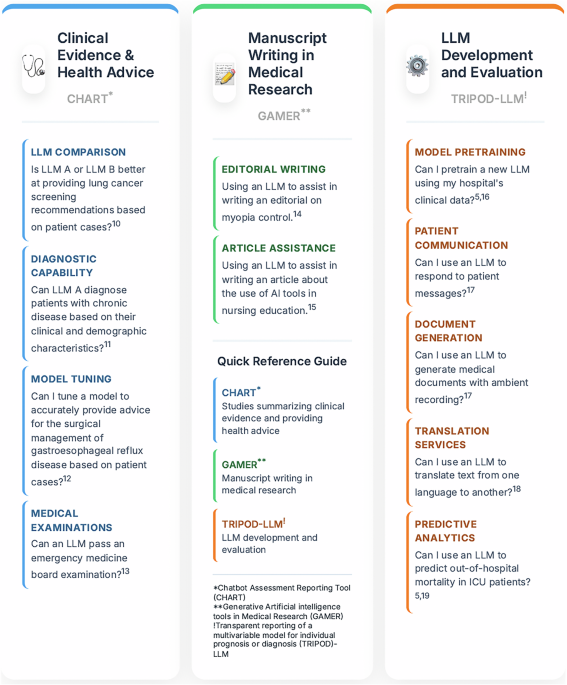
Selecting the most suitable reporting guideline will generally depend on the research aims. Figure 1 provides a list of potential research aims currently addressed by reporting guidelines. At the time of writing, LLMs are the predominant GAI model being evaluated in the healthcare context, though other popular examples include diffusion models and large multimodal models9. Studies involving LLMs are addressed by the Chatbot Assessment Reporting Tool (CHART), the Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD)-LLM, or the Generative Artificial intelligence tools in Medical Research (GAMER)5,6,7,8.
Fig. 1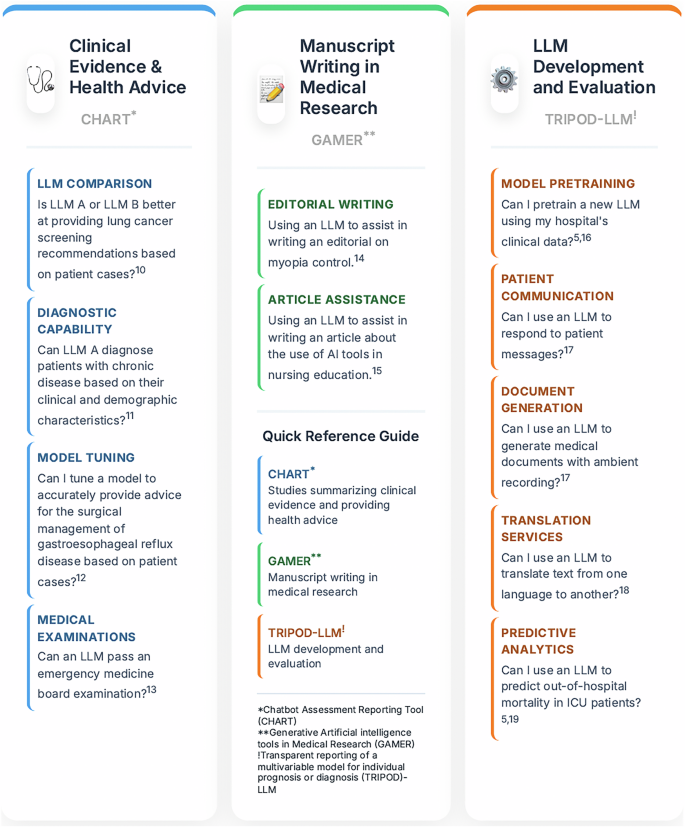
Overview of GAI reporting guidelines17,18,19,20,21,22,23,24,25.
Clinical evidence summaries and health advice
CHART provides reporting recommendations for studies evaluating any GAI model or GAI-driven chatbot that summarizes clinical evidence and provides health advice—termed Chatbot Health Advice (CHA) studies6,8. CHART can also be applied to studies of standalone GAI models, provided the model interacts with users in natural language, such as through an application programming interface. Investigators should apply CHART for CHA studies evaluating a single GAI model or GAI-driven chatbot, as well as in comparative studies between multiple GAI models or chatbots6,8. The framework is also relevant for evaluations of tuned or fine-tuned GAI models or chatbots for tailored evidence summaries or health advice. While examples are provided in Fig. 1, CHART’s scope includes clinical evidence or health advice related to health prevention, screening, diagnosis, treatment, prognosis, and general health information6,8.
Model development, document generation, and outcome prediction
Authors may apply TRIPOD-LLM across a wide range of use cases, from de novo LLM development to using LLMs for generating medical documents or predicting outcomes using patient data5. The TRIPOD-LLM authors also recommend its use for studies assessing an LLM’s capability in tasks such as:
○
Text processing (e.g., identifying predefined categories of objects in a body of data, or named entity recognition)5.
○
Classification (e.g., determining whether a clinic note uses a patient’s pronouns correctly).
○
Information retrieval (e.g., training a GAI model to respond to user queries using relevant publications)5.
○
Summarization (e.g., translating clinical documents into specific languages for patients).
Figure 1 outlines further use cases, as does the original TRIPOD-LLM publication5. The reporting recommendations are suitable for evaluations of a single LLM or comparisons among multiple LLMs.
Applying GAI for manuscript writing
Studies discussed thus far have evaluated GAI model performance for specific study objectives. However, there is growing interest in applying GAI models to assist in manuscript writing across traditional research designs7. Rather than focusing on model performance, the GAMER reporting guideline provides recommendations that address studies where all or portions of a manuscript are written by a GAI model for medical research7. For example, authors may apply GAMER if they apply a GAI model to assist in writing a case report. Figure 1 lists additional examples.
Strengths and limitations of current reporting guidelines
All reporting guidelines described above followed methodological guidance from the Enhancing the QUAlity and Transparency Of health Research Network; an international initiative to improve the transparency of health research10,11. These reporting guidelines currently apply to LLMs, while CHART and TRIPOD-LLM are designed as living documents which will be updated periodically to respond to advances in the field5,6,8. Authors applying conventional study designs such as randomized controlled trials or cohort studies should continue to adhere to relevant tools such as the CONsolidated Standards Of Reporting Trials (CONSORT) and the STrengthening the Reporting of OBservational studies in Epidemiology (STROBE) reporting guidelines in addition to those described here5,12.
One strength of the CHART reporting guideline was its input from broad representation of interdisciplinary stakeholders through 531 members during the Delphi consensus. Though it is highly applicable to CHA studies, its scope is narrow. In contrast, TRIPOD-LLM applies to a multitude of use cases involving LLMs, though the applicability of each checklist item may depend on the specific use case. While the GAMER checklist is concise and specifically relevant for medical research, it may lack important items included in other reporting guidelines.
Reporting guidelines in development
There are multiple reporting guidelines in development including the ChatGPT and Artificial Intelligence Natural Large Language Models for Accountable Reporting and Use (CANGARU) reporting guideline13. CANGARU is being developed according to robust methodological standards involving a living systematic review, Delphi consensus, and panel consensus meetings among international, multidisciplinary stakeholders14. Once published, investigators may be interested in the CANGARU guidelines when using LLMs in academic research and scientific writing. The CANGARU guidelines will apply to studies within medicine, but also to those studies using LLMs for manuscript writing in other non-medical scientific sectors14.
In health economics, investigators have initiated the ELEVATE-GenAI framework with 10 preliminary checklist items after a targeted literature review, iterative discussion, and usability testing for both systematic reviews and health economic modeling15. It currently consists of a structured framework and a checklist for practical implementation which uses a scoring system, with a maximum of 3 points awarded per domain. The authors are planning stakeholder consultation across various disciplines through a Delphi consensus to improve the validity of the tool15.
In contrast, the Consolidated Criteria for Reporting Qualitative Research (COREQ) extension for LLMs (COREQ-LLM) will address studies employing LLMs for qualitative research16. COREQ-LLM will be developed following a systematic scoping review and Delphi consensus to identify checklist items to aid in the transparent reporting of qualitative research involving LLMs. It is anticipated that this reporting guideline will address current trends in qualitative research in which LLMs are used to support research design, data processing, analysis, interpretation, and direct interaction with qualitative data16.
These represent the first iterations of reporting guidelines addressing the landscape of GAI research in healthcare. They address the development of GAI models as well as the use of GAI models for manuscript writing, summarizing clinical evidence, providing health advice, or predicting health outcomes using electronic health records. Clinicians, researchers, journal editors, and publishers should note that these reporting guidelines and apply to any studies evaluating the use of GAI models for health purposes. Future iterations, extensions, and/or new reporting guidelines will keep pace with the dynamically transforming nature of the field. Researchers must remain up-to-date with the literature and continue to apply the most applicable reporting standards to their work as we work toward the safe and responsible integration of GAI technology in healthcare. Journal editors and publishers must also be alert to updates in the GAI field and continue to encourage authors to adhere to relevant reporting standards. We will perform a living systematic survey of GAI-oriented reporting guidelines to help readers remain up-to-date with the dynamically evolving environment of GAI literature.