
Quantitative
Overall, 191 participants of the primary grantee’s projects generated 617 responses that were extracted and analysed by nine evaluators. The largest number of participants were originally from EHA Clinics project [EHA Clinics 53 (27.8%), followed by UFMG 43 (22.5%), Susastho.ai 37 (19.4%), Intelsurv 37 (19.4%), Boresha 11 (5.8%), NoHarm 10 (5.2%)] (Fig. 1). Just over one-half of the participants was from Africa (101, 52.9%). Regarding the language of participants from which data were derived, there was a relatively even distribution between Bangla, Chichewa and Portuguese [37 (19.4%), 37 (19.4%) and 32 (16.8%), respectively], followed by followed by English, Swahili and Urdu [13 (6.8%), 11 (5.8%) and 8 (4.2%), respectively] (Fig. 1 and 2). The most common source of data was healthcare assistance projects (96 participant responses, 50.3%), followed by healthcare education (85, 44.5%). Only ten (5.2%) participants evaluated the use of AI in healthcare processes (i.e., automated discharge summaries).
Fig. 1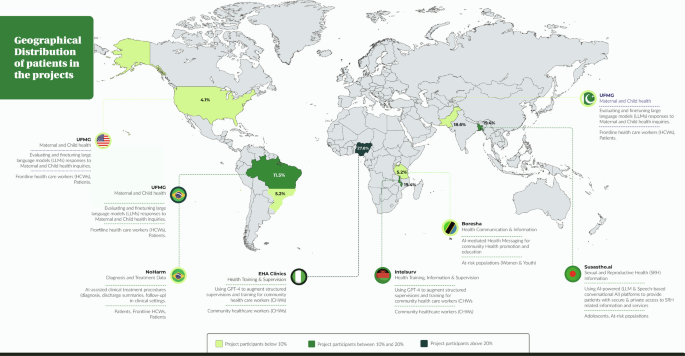
Distribution of participants across the Globe (Created with MapChart).
Fig. 2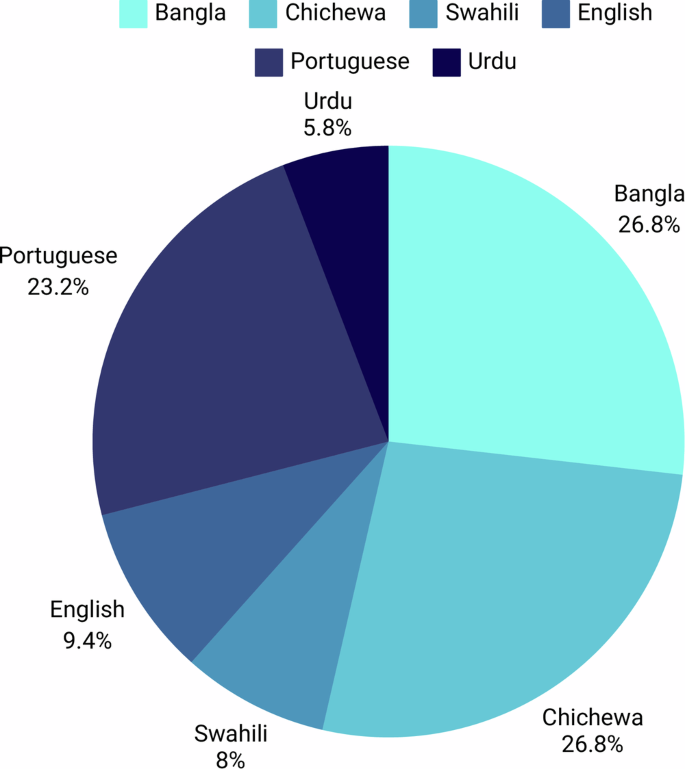
Relative distribution of participant´s languages.
Regarding the analysis performed by the nine evaluators, based on average ratings, the two-way fixed-effects consistency model demonstrated an overall ICC of 0.93 (95% CI: 0.91–0.94, with an average rating k = 9), indicating excellent inter-rater reliability.
Overall, most analysed responses came from Susatho.ai project performed in Bangladesh (296, 48.0%), which together with Pakistani responses from UFMG project (30, 4.9%), made Asia as the primary source of analysed responses (326, 52.8%). Most responses were in the context of healthcare education (403, 65.3%), followed by healthcare assistance (194, 31.4%). Notably, responses heavily leaned towards a more positive view, with 432 (75.4%) responses categorised as enthusiastic, 124 (21.6%) as taking a practical view, and only 17 (3.0%) as sceptical. In fact, in three projects (NoHarm, Intelsurv and EHA Clinics) no response was categorised as sceptical. This tendency persisted across studies, countries, regions, languages and social contexts, with a few noticeable exceptions. Although perceptions were largely enthusiastic regarding the use of AI, in NoHarm’s project, which focused on healthcare processes, most perceptions were considered practical [Perception; Practical, 11 (8.9%) vs. Enthusiast, 9 (2.1%), p = 0.000*]. Similarly, perceptions regarding responses generated in Urdu (Pakistan) were also mostly practical [Perception; Practical, 7 (5.6%) vs. Enthusiast, 6 (1.4%), p = 0.000*] (Table 1).
Table 1 Responses from grantee projects by Healthcare Worker Perceptions
Considering that each participant’s perception is derived from the combined perception scores assigned to each individual Q&A they analysed, all participants were either practical or enthusiastic regarding the use of AI in their specific setting of application, independent of study, country, region, language, and social context (Fig. 3 and Supplementary Fig. 1). Interestingly, perceptions were most enthusiastic in Africa versus other regions, and it was most heterogeneous among participants who spoke Portuguese or Urdu as their native language (Fig. 3).
Fig. 3: Boxplots depicting averaged overall evaluator perceptions by study.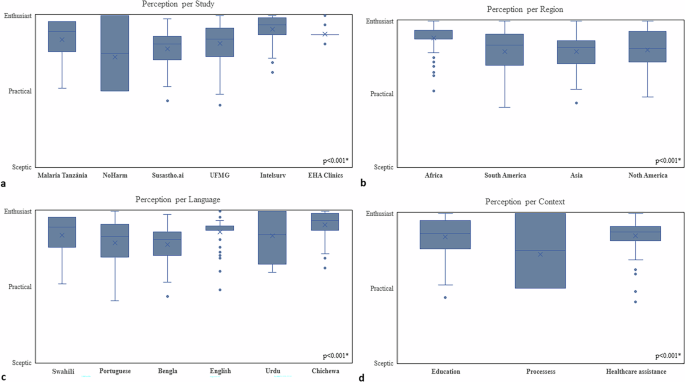
(a) region; (b) language, (c), and context (d). Perception classification ranged from sceptic, to practical, to enthusiast; * signify statistical significance (p < 0.05).
Qualitative
In general, the projects received good feedback regarding general quality of medical information and accuracy of LLMs. However, hallucinations and inaccuracies still occured. There were limitations with some languages such as translation issues in Portuguese and Urdu. Further, complex or more nuanced information such as medical abbreviations were, sometimes, inaccurate. Concerns were raised around context specific and culture specific responses, especially regarding maternal and reproductive health; this was highlighted by poor sentence construction, “politician” type responses or even “scary” language with variable empathy. There was variation in different LLMs, and improvement over the evolution of the projects as new LLMs became available.
UFMG
Overall, when analyzed by specialists from the United States, LLMs (GPT- 3.5, GPT-4, custom GPT- 3.5, and Meditron-70b) were able to produce good answers effectively to all questions pertaining to maternal health in a fairly clear manner. However, answers often lacked detailed information and sometimes presented outdated medical terms. Moreover, some answers lacked enough description to provide nuanced or site-specific discussion (for instance limited strategies for pain relief during labor). Interestingly, non-trained models outperformed custom LLMs in various scenarios. Overall, LLM responses were characterized by impressively high scores for clarity and quality of content, while readability and poor translation to LIMC languages were identified as key areas of improvement.
Brazil
When analyzing LLMs (GPT- 3.5, GPT-4, custom GPT- 3.5, and Meditron-70b) performance in responding to questions pretraining to maternal health, specialists pointed out that GPT-3.5 sometimes failed to provide complete information and even omitted potential risks. Examples included not clarifying the possibility of “uterine rupture” in vaginal birth after a caesarean section or not including epidural analgesia as a strategy for pain relief during childbirth. For GPT 4.0, besides mentioning the need for more complete answers, translation errors were often mentioned. Poor sentence construction and mistranslation diminished the authenticity and clarity of information. Answers generated by a custom GPT-3.5 were considered “generic and superficial.” Similarly, Meditron-70b responses were considered generic and incomplete; for example, responses would only address risks and not provide any information about the benefits of certain procedures. Specialists criticized the model’s apparent negative view of labor/delivery, assuming that “there will always be pain that will require some method of relief”, and the failure to address the fact that each woman may react differently according to their tolerance.
Pakistan
When analyzing LLMs (GPT- 3.5, GPT-4, custom GPT- 3.5, and Meditron-70b) performance in responding to questions pretraining maternal health, answers generated by GPT-3.5 and GPT-4 were generally considered adequate, but sometimes extra information was desired. Custom GPT-3.5 responses lacked sufficient information, overlooked details and omitted important points. In contrast, answers generated by Meditron-70b were often considered very good, containing pertinent and detailed information. However, evaluators noted that Meditron-70b struggled relative to information about the risk of mortality in certain scenarios. Specialists noted that crude information about the risk of death was generated in a “scary way”, without mentioning the available means to mitigate it, and may mislead patients eligible for vaginal birth. Importantly, throughout all LLMs, most criticism regarding responses was related to the reportedly poor Urdu translation and the desire to improve it.
NOHARM – Brazil
Most healthcare workers noted that traditional summary discharges usually do not provide sufficient information. At the same time, all participants stated that they consider discharges summaries in digital format more convenient. If an automated tool was utilized, all participants stated that they would feel comfortable receiving patient discharge summaries knowing that they were generated by AI and reviewed by a doctor. In fact, 30% reported that they would feel “very comfortable”. Results on the performance of LLMs (GPT- 3.5, GPT-4, MariTalk 1 and 2, and GeminiPro) in automating discharge summaries demonstrated that GPT-4.0 most common mistakes were redundancy (i.e. chronic kidney disease and Chronic Kidney Failure or SS Hemoglobinopathy and Sickle Cell Disease) and incomplete diagnoses [i.e. Type-2 Diabetes (T2D) being referred to as simply Diabetes mellitus; and Dermatitis in the left upper limb (LUL) as only Dermatitis]. Another overall mistake was the presence of non-specific terms when extracting data from patients’ history, such as “Diagnostic hypotheses” instead of the actual diagnoses. Moreover, when asked to work with acronyms, LLMs often misinterpreted them, such as the acronym MCP (“medicamento conforme prescrição”) [MAP (medication according to prescription)], presented by the LLM as “Microangiopatia cerebral proliferativa” [Cerebral proliferative angiopathy]. Although this type of mistake happened in all evaluated models, rates were eight times higher for MariTalk 1 and three times higher for Palm 2. Furthermore, GeminiPro and MariTalk 1 featured hallucinations, suggesting that patients suffered from chronic obstructive pulmonary disease and two of cerebrovascular accident, while no terms in their patients’ history indicated these diagnoses.
SUSASTHO.AI – Bangladesh
When analyzing LLMs performance as a chatbot in a digital healthcare platform providing secure access to sexual, reproductive, and mental health care for adolescents, most front-line health care workers had a favorable view, describing it as helpful, informative and easy to use and understand. However, some users suggested enhancing the chatbot’s ability to better understand questions and be more comprehensive. Many users felt that the chatbot adequately answered most of their questions with ease and clarity. In contrast, its performance was not consistent and an increased ability to handle complicated or nuanced questions was desired. Most participants saw the chatbot as a helpful and beneficial tool and not a threat. Nevertheless, emphasis on the need for clinically validated and accurate information, as well as minding the occurrence of culturally insensitive information was mentioned. In other words, users felt that with proper management, the chatbot poses no threat and can significantly aid users provided a continuous update and training.
Overall, users noted the Susastho.ai chatbot to be a valuable resource for information on Sexual and Reproductive Health (SRH) and Mental Health (MH). Enhancements in understanding complex questions and expanding the information database are desired. The chatbot holds significant promise for personal use, professional development, rural healthcare support, and breaking down social barriers related to sensitive health topics. Maintaining accurate and validated information is crucial for user trust and the chatbot’s effectiveness.
INTELSURV – Malawi
When utilizing LLMs (ChatGPT and MedPalm) to develop a tool to streamline the collection, analysis, and use of COVID-19 data, front-line health care workers who navigated the interface encountered no errors or difficulties and managed to ask and receive questions from IntelSurv. The respondents agreed that IntelSurv can improve access to knowledge for their work. They were excited about its ability to answer broad questions about diseases and surveillance other than those typically available in printed materials. Users appreciated the non-restrictive approach that allowed both technical and less technical questions. They remarked positively that IntelSurv was able to correct, understand, and answer questions that contained spelling or grammatical errors. Some areas of improvement noted were regarding response time when answering live questions, the wordiness and length of answers (“the tool answers like a politician”), and the need to add translation to local languages. The top five topics of most interest to participants were cholera, anthrax, how to capture demographic information, the rationale for collecting data, and information about laboratory tests. Cardiovascular diseases and abbreviations also tied in fifth place.
BORESHA – Tanzania
LLMs have also been tested to automate patient discharge summaries. GPT-4 has proven to be more reliable compared with other models like MariTalk 1 and Palm 2, as it makes fewer errors such as repeating information or simplifying diagnoses. However, LLMs do have flaws. Mistakes like categorizing “Type 2 Diabetes” as just “Diabetes” highlight limitations in providing nuanced output in medical contexts, where these distinctions make a significant difference. In rural areas, chatbots have been integrated with mobile phones or community radio programs and have reached millions with critical malaria prevention messages. These systems adapt responses based on user questions but sometimes struggle with the intricacies of local languages, like Swahili idioms, which slightly reduce their effectiveness. Despite these issues, LLMs have shown to be potentially powerful tools for scaling health education quickly.
Besides improving communication, LLMs were also utilized to help with diagnostics. For instance, predictive tools powered by models like GPT-4 analyzed climate and health data to forecast disease outbreaks, such as malaria surges during rainy seasons. These systems have achieved accuracy rates of up to 85%. However, some healthcare providers worry about over-relying on these systems without proper human validation. AI-powered mental health platforms like locally developed GPT-based systems are offering anonymous, round-the-clock support for issues like anxiety and depression. While these tools help reduce stigma and improve access to mental health resources, they sometimes fail to interpret culturally specific expressions of distress, which underscores the need for human oversight in refining these tools.
Infrastructure and data security challenges pose significant hurdles. A survey of healthcare workers noted that while many are open to using AI tools if data is secure, limited internet access in rural clinics hampers broader adoption. Misunderstandings about AI, like fears it might replace healthcare jobs, further complicate its integration.