
Study design and data sources
The data used in this study are collected and used in line with NHS England’s purposes, as required under the statutory duties outlined in the NHS Act 2006 and the Health and Social Care Act 2012. The Segmentation Dataset is processed under a data processing agreement between NHS England and Outcomes Based Healthcare, Ltd. (OBH), which produces the Segmentation Dataset on behalf of NHS England. This ensures controlled access by appropriate approved individuals to anonymized/pseudonymized data held on secure data environments entirely within the NHS England infrastructure. Data are processed for specific preregistered purposes only, including operational functions, service evaluation and service improvement. The present study supported these purposes, so ethics committee approval was not required. Where OBH had processed data, this was agreed and detailed in a data processing agreement. The data used to produce this analysis were disseminated to NHS England under directions issued under Section 254 of the Health and Social Care Act 2012.
This was a retrospective observational cohort study that aimed to assess the association between completion of the NHS DPP (as measured through attendance at more than 60% of sessions) and subsequent incidence of LTCs recorded, including T2D, between April 2016 and February 2020. After exclusion of four LTCs usually diagnosed at birth or in early childhood, 31 LTCs were divided into two groups: LTCs considered etiologically linked to program interventional goals of body weight reduction, increased physical activity or improved diet quality (LTC-L) and LTCs considered to be possibly linked to body weight reduction, increased physical activity or improved diet quality (LTC-PL). This categorization was based on a search strategy detailed in Supplementary Table 1 and Supplementary Information (‘Search strategy for linked and possibly linked conditions’). The full list of conditions can be found in Table 1.
The NDA was used to identify all individuals diagnosed with NDH and was also used to measure incidence of T2D. The NDA has collated data on people with diabetes registered with a general practice in England since 2003 and with NDH since 2017, with almost complete practice participation in recent years (99% in 2019/2020). However, there is a degree of under-coding of NDH in general practice27. The NHS DPP Minimum Dataset was used to identify all individuals with NDH who had been referred to the NHS DPP.
The Bridges to Health Segmentation Dataset was used to measure the incidence of the 30 other LTCs. The dataset covers individuals registered with a general practice in England since 2014 and includes sociodemographic, geographic as well as clinical diagnostic data. The Segmentation Dataset has been derived from numerous national, predominately secondary care, patient-level datasets held in the National Commissioning Data Repository, each of which is linked by pseudonymized NHS numbers. The dataset now includes more than 15 years of data from the SUS dataset, which collects data from all hospitals in England, including admitted patient care, outpatient and emergency care data, in addition to mental health data, community data and the NDA. The full list of source datasets used to derive the Segmentation Dataset, including the time over which data have been longitudinally accrued, can be found in Supplementary Table 17. The Segmentation Dataset includes 35 LTCs, including diabetes, which align reasonably well with the conditions suggested for inclusion in the entity ‘multiple long-term conditions’ through a recent Delphi consensus study28. The 35 conditions included in the Segmentation Dataset were derived using data definitions based on logic and clinical codes (for example, International Classification of Diseases, 10th revision, diagnostic codes; OPCS Classification of Interventions and Procedures codes; and Systematized Nomenclature of Medicine–Clinical Terms codes) and were developed for each condition after extensive clinical review and evaluation29. Further details on the process of selection of LTCs and the prevalence of MLTCs were published previously30.
The NDA dataset was used to measure incidence of T2D because the Segmentation Dataset is derived through linkage of numerous datasets, not all of which identify type of diabetes. Further information on the accuracy of the coding in the Segmentation Dataset is outlined in Supplementary Information (‘Further infomation on the National Segmentation Dataset’).
SUS data were used to estimate the frequency with which individuals attended accident & emergency (A&E) departments, were admitted to hospital as inpatients or had an appointment as outpatients. Publicly available data sources were used to provide information on the Index of Multiple Deprivation (IMD)31; workforce characteristics32; pay for performance, also known as Quality and Outcomes Framework (QOF) scores33; and the Rural–Urban Classification34 of each individual’s general practice.
Outcomes
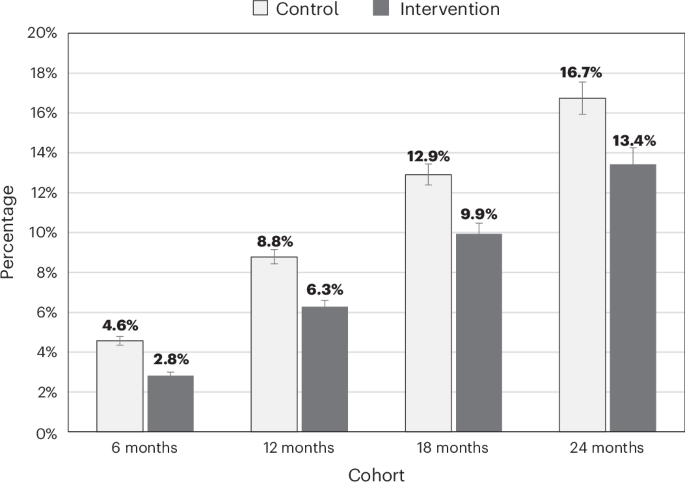
The outcome assessed was the incidence of T2D and 30 other LTCs between 1 April 2016 and 28 February 2020 at timepoints of 6 months, 12 months, 18 months and 24 months after each participant’s start of the NHS DPP, using separate cohorts for each time period. In primary analyses, individuals who had been referred to the NHS DPP and completed the program, defined as attending more than 60% of intervention sessions (the intervention group), were compared to a matched control group of individuals who were referred to the NHS DPP but did not attend any program sessions. In secondary analyses, analyses were repeated, with the matched control group consisting of individuals with NDH who were not referred to the NHS DPP. Individuals who were referred to the program and attended less than 60% of the program were not included. We also assessed MLTC incidence by comparing the proportions of individuals who transitioned from a non-MLTC state (that is, fewer than two LTCs at baseline) to an MLTC state (that is, two or more LTCs at follow-up), in both the primary and secondary analyses.
Covariates
Each individual in the study was assigned a date of NDH diagnosis and a start date for the follow-up period. The start date of the follow-up period refers to the date of the first intervention session attended or is estimated for those who did not attend the NHS DPP. NDH diagnosis dates that were missing, either by not being recorded in the NDA or recorded incorrectly as occurring after their start of the follow-up period, were estimated by randomly sampling from the distribution of the lags (in days) between valid NDH diagnosis dates and valid start dates and subtracting this number of days from the start date. Of those in the primary analyses in the 6-month cohort (n = 113,255), 37.0% (n = 41,932) of individuals had estimated NDH diagnosis dates, of which 26.2% (n = 29,745) were missing from the NDA and 10.8% (n = 12,187) had NDH diagnosis dates that occurred after NHS DPP start dates. In the 6-month cohort, the median (interquartile range) number of days between the NDH diagnosis date and the start date of the NHS DPP was 169 days (84–361) for those in the intervention group and 162 days (81–347) for those in the control group. Results were similar in the 12-month, 18-month and 24-month cohorts.
Demographic factors age, sex, ethnicity and socioeconomic status were identified as potential confounding factors. Sex was recorded as male or female. Age in years was calculated as at the date of NDH diagnosis. Socioeconomic status was measured using IMD quintiles associated with the Lower Layer Super Output Area of residence, which was derived from individual postcode. For ethnicity, each individual was assigned their most frequently recorded ethnicity across source datasets and then allocated to one of the conventional high-level groupings: Asian, Black, Mixed, Other, White and unknown.
The sex variable in this study is derived from the ‘administrative gender’ field of the Master Patient Index/Personal Demographics Service source dataset. Among a small proportion of people, estimated by the UK census to be 0.5%, for whom gender identity and biological sex at birth are not the same, a further unquantifiable proportion may have an ‘administrative gender’ code that differs from their biological sex. This proportion depends on how this field is used, which is likely to be inconsistent between providers, and is not currently possible to establish based on the available data. We understand that this is symptomatic of wider challenges with confusion around sex and gender data collection in NHS datasets, as recently highlighted in the March 2025 independent review of data, statistics and research on sex and gender35. This review also made recommendations for improved clarity in future data collection.
We also included clinical factors: the presence of preexisting LTCs and the frequency of emergency admissions to hospital, outpatient appointments and A&E attendances in the year before NDH diagnosis. The following general practice–level factors were also included to capture the sociodemographic context and quality of primary care: IMD quintile of general practice, rural–urban classification of general practice, overall clinical QOF score, clinical commissioning group of practice, size of practice list and full-time equivalent (FTE) general practice ratio. To account for the selection bias likely stemming from clinical judgment subjectively informing referral decisions across different general practices, we also derived a variable that estimated the probability of program completion for individuals referred to the program.
Matching
We used the nearest neighbor matching algorithm without replacement36 on the demographic, clinical, general practice and probability of completion factors listed above, determined at the date of NDH diagnosis, with a 1:1 ratio of control to intervention units. To account for varying lags between date of NDH diagnosis and start of the program, matching also incorporated the quarter of date of NDH diagnosis.
Matching was conducted in four separate waves, corresponding to the four cohorts, starting with 24 months and moving on to 18 months, 12 months and 6 months, at each stage retaining only the individuals who were eligible for the program and had enough follow-up time in the study period (that is, had started the NHS DPP intervention before March 2018 for the 24-month follow-up period, before September 2018 for the 18-month follow-up period, before March 2019 for the 12-month follow-up period and before September 2019 for the 6-month follow-up period). Balance was assessed using SMD scores37. The full selection process and the list of exclusion criteria are outlined in Supplementary Fig. 1.
Statistical analysis
Logistic regression models were used to estimate the association between completion of the NHS DPP and incidence of T2D in all four cohorts. For example, in the 6-month cohort, the incidence of T2D up to 6 months after starting the program for individuals in the intervention group was compared to the incidence of T2D for individuals in the control group over the same time period. The first model included only the group identifier (intervention or control) as an independent variable to calculate unadjusted odds ratios for the incidence of T2D. The second model additionally included the demographic, clinical, general practice and probability of completion factors as independent variables to calculate adjusted odds ratios. Preexisting LTCs were determined at the start of the follow-up period, whereas other factors were determined at the NDH diagnosis date. Together, these are referred to as the baseline characteristics. Corresponding analyses at 12 months, 18 months and 24 months were similarly carried out. We also ran separate logistic regression models for each LTC, with the incidence of each condition (zero or one) as the outcome.
Separate negative binomial regression models were used to estimate the association between completion of the NHS DPP and the number of new LTC-L and LTC-PL in all four cohorts. For example, in the 6-month cohorts, negative binomial regressions were fitted with the number of new conditions acquired up to 6 months after starting the program as the outcome. The first set of models included only the group identifier (intervention or control) as an independent variable to calculate unadjusted rate ratios for the incidence of LTC-L conditions and LTC-PL conditions. The second model additionally included the demographic, clinical, general practice and probability of completion factors as independent variables to calculate adjusted rate ratios. Corresponding analyses at 12 months, 18 months and 24 months were similarly carried out. As above, preexisting LTCs were determined at the start of the follow-up period, whereas other factors were determined at the NDH diagnosis date.
Separate models were run by sex and age group (<70 years and ≥70 years). Overlapping confidence intervals were used to assess any differences between the models. Model fit was verified using standard diagnostic statistics (Akaike information criterion, root mean square deviation, overdispersion and percentage observed versus predicted zeros). Chi-square tests for categorical data and t-tests for continuous data were used to assess any differences between the intervention and control groups.
Statistical significance was defined as P < 0.05, and confidence intervals were set at 95%. All data were analyzed with RStudio version 4.4.1.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.