
A total of 276 clinicians participated in the study, including 178 physicians, 28 fellows/residents, 60 advanced practice providers (physician assistants and nurse practitioners), and 10 individuals in other clinical roles. An additional 123 individuals started the survey but did not complete it and thus were not included in the analysis. In the total cohort, most participants were aged 35–54 years; 60.1% were female, 19.2% Asian, 4.7% Black, and 62.3% White. As shown in Table 1, participants were balanced across years of practice experience and practice setting (inpatient and outpatient). Baseline demographic and workforce characteristics did not differ significantly across the three conditions. For clarity, the “GenAI-primary” condition refers to a physician using GenAI as the primary decision-making aid, whereas in the “GenAI-verify” condition, the physician uses GenAI only to verify their decision. A summary of participants’ responses is provided in Table 2.
Table 1 Characteristics of study participants by experimental conditionTable 2 Summary of participants’ ratings by experimental conditionClinical Skills
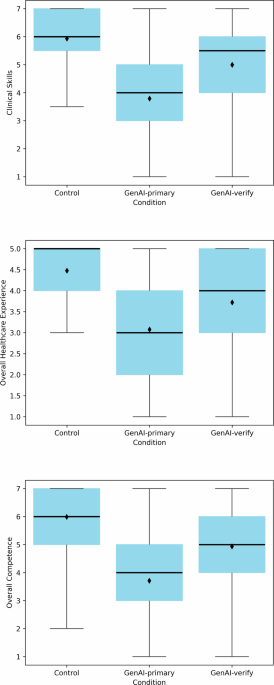
Ratings of clinical skills differed significantly across the three conditions (F(2, 273) = 45.45, p < 0.001, ηp² = 0.25; Fig. 1, first panel). The mean (SD) clinical skills score for the Control condition was 5.93 (1.24), for GenAI-primary was 3.79 (1.62), and for GenAI-verify was 4.99 (1.67). The difference between the GenAI-primary and Control conditions was statistically significant (F(1, 273) = 90.30, p < 0.001, ηp² = 0.25), as was the difference between GenAI-verify and Control conditions (F(1, 273) = 17.33, p < 0.001, ηp² = 0.06). Presenting GenAI as a verification tool partially mitigated this effect, though the clinical skills rating remained lower than in the Control condition (F(1, 273) = 28.99, p < 0.001, ηp² = 0.10).
Fig. 1: Clinicians’ evaluations of clinical skill, overall healthcare experience, and overall competence across conditions.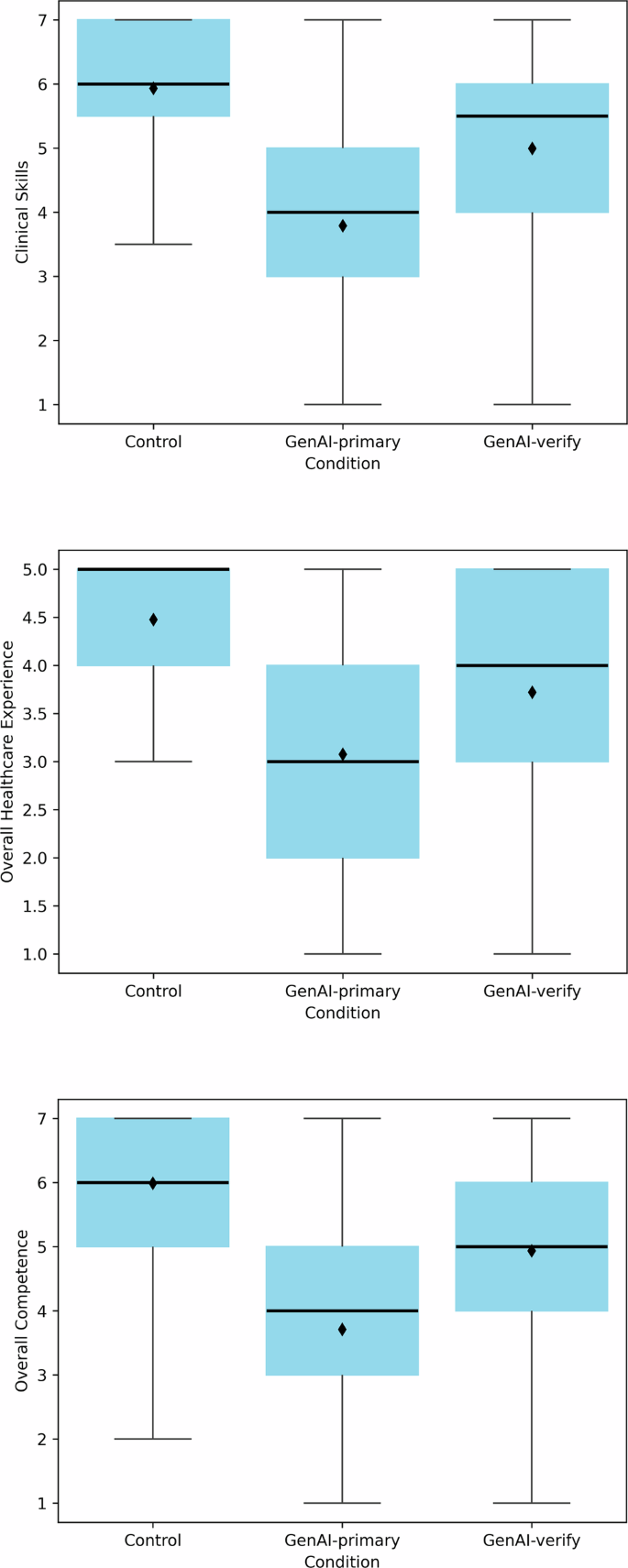
Clinicians (n = 276) rated the physician of their assigned condition: Control (no GenAI), GenAI-primary (using GenAI as a primary decision-making tool), or GenAI-verify (using GenAI as a verification tool). Boxes represent the interquartile range (IQR), with horizontal lines indicating medians and diamonds indicating means. Whiskers extend to responses within 1.5 IQRs of the lower and upper quartiles.
Overall Healthcare Experience
Evaluations of overall healthcare experience differed significantly across the three conditions (F(2, 273) = 34.38, p < 0.001, ηp² = 0.20; Fig. 1, second panel). The mean (SD) evaluations were 4.48 (0.82) in the Control condition, 3.08 (1.30) in the GenAI-primary condition, and 3.72 (1.24) in the GenAI-verify condition. Compared with those in the Control condition, evaluations in the GenAI-primary condition (F(1, 273) = 68.67, p < 0.001, ηp² = 0.20) and GenAI-verify condition (F(1, 273) = 20.02, p < 0.001, ηp² = 0.07) were significantly lower. The healthcare experience was rated significantly lower in the GenAI-primary condition than in the GenAI-verify condition (F(1, 273) = 14.77, p < 0.001, ηp² = 0.05). That is, while presenting GenAI as a verification tool improved healthcare experience evaluations, they remained lower than those in the Control condition.
Mediation analysis revealed that clinical skills ratings mediated the relationship between study conditions and healthcare experience evaluations. This analysis showed the relative indirect effect of DGenAI-primary through clinical skill ratings was significant (β = −1.30, SE = 0.15, 95% CI: [−1.59, −1.01]), and the relative indirect effect of DGenAI-verify was also significant (β = −0.57, SE = 0.13, 95% CI: [−0.83, −0.31]). In other words, generative AI usage reduced the ratings of the physician’s clinical skills, which in turn negatively impacted the evaluations of the overall healthcare experience provided by the physician.
Overall Competence
Overall competence evaluations differed significantly across the three conditions (F(2, 273) = 49.60, p < 0.001, ηp² = 0.27; Fig. 1, third panel). The mean (SD) ratings were 5.99 (1.25) in the Control condition, 3.71 (1.61) in the GenAI-primary condition, and 4.94 (1.74) in the GenAI-verify condition. Compared with those in the Control condition, competence evaluations were significantly lower in the GenAI-primary condition (F(1, 273) = 98.91, p < 0.001, ηp² = 0.27) and GenAI-verify condition (F(1, 273) = 21.13, p < 0.001, ηp² = 0.07) conditions. Competence evaluations in the GenAI-primary condition were significantly lower than those in the GenAI-verify condition (F(1, 273) = 29.09, p < 0.001, ηp² = 0.10). That is, presenting GenAI as a verification tool improved competence evaluations, but they remained significantly lower than in the Control condition.
Mediation analysis revealed that clinical skills ratings mediated the relationship between study conditions and competence evaluations. The relative indirect effect of DGenAI-primary through clinical skill ratings was significant (β = −1.93, SE = 0.20, 95% CI: [−2.33, −1.55]), and the relative indirect effect of DGenAI-verify was also significant (β = −0.85, SE = 0.20, 95% CI: [−1.24, −0.46]). The use of GenAI decreased ratings of the physician’s clinical skills, which in turn led to lower competence evaluations.
Perceived Usefulness of GenAI
The perceived usefulness of GenAI technologies did not differ across the three conditions. Participants rated GenAI technologies as useful for ensuring clinical assessment accuracy (mean [SD], 4.30 [1.65]; t = 3.06, p < 0.002, Cohen’s d = 0.18), and they rated customized GenAI as even more useful (mean [SD], 4.96 [1.65]; t = 9.64, p < 0.001, Cohen’s d = 0.58). That is, participants perceived GenAI as a useful tool for clinical assessment.