
Ethics approval
The Chinese Academy of Medical Sciences and Peking Union Medical College and the local medical ethics committee of the First Affiliated Hospital of Guilin Medical University approved the study. The institutional review boards of the Affiliated Hospital of Gansu Medical College approved the study protocol based on their review and the approval from the medical ethics committee of the First Affiliated Hospital of Guilin Medical University. The trial followed the Declaration of Helsinki and the International Conference of Harmonization Guidelines for Good Clinical Practice. We obtained informed consent from all participants in this study. All participants were informed that this was an exploratory experiment, and the results should not be interpreted as direct guidance for clinical interventions at this stage. This study implemented stringent data protection measures, ensuring that all data were anonymized and encrypted to protect privacy. This trial is registered at the Chinese Clinical Trial Registry (identifier ChiCTR2400094159).
Co-designed architecture and clinical integration
PreA’s architecture, derived from the co-design with local stakeholders, integrates a patient-facing chatbot and a clinician interface (Extended Data Fig. 1a). The patient interface collects medical history via voice or text, while the clinical interface generates structured referral reports. Within the consultation workflow, patients or their designated caregivers interacted with PreA first; it then generated a referral (Supplementary Table 4) for specialists to review before their standard consultation.
Co-design workshops revealed that standard clinical documentation for common conditions often lacks the granularity for personalized care and omits critical patient-specific details like pre-existing comorbidities. As such, PreA referral reports were intentionally designed to bridge this gap by synthesizing comprehensive, patient-specific information to facilitate rapid documentation and diagnostic decision-making. The architecture was also engineered to support both multidisciplinary consultation (prioritized by primary care physicians) and evidence-based diagnostic reasoning (emphasized by specialist physicians).
PreA’s consultation logic underwent a two-cycle co-refinement process to achieve broader utility across diverse socioeconomic patient populations and adherence to World Health Organization (WHO) guidelines for equitable AI deployment (Extended Data Fig. 1b). The first cycle involved adversarial testing with 120 patients and caregivers, 36 community health workers, 15 physicians and 38 nurses from urban and rural areas across 11 provinces (Beijing, Chongqing, Gansu, Hubei, Shaanxi, Shandong, Shanxi, Sichuan, Guangxi, Inner Mongolia and Xinjiang). This participatory refinement enhanced real-world contextualization and mitigated potential disparities in health literacy and workflow integration49. The second cycle employed a virtual patient simulation, specifically modeling low-health-literacy interactions to further optimize the model against co-designed evaluation metrics. Subsequent sections provide further methodological details.
Model developmentPatient-facing chatbot
The patient-facing chatbot employs a two-stage clinical reasoning model: inquiry and conclusion. During the inquiry stage, the model was trained to conduct active, multiturn dialogues to gather comprehensive health-related information, adhering to standard guidelines on general medical consultation. In the conclusion stage, the model generated 1–3 differential relevant diagnostic possibilities, each with supporting and refuting evidence to enhance diagnostic transparency and mitigate cognitive anchoring risks50,51.
Specialist physician interface
PreA was configured to generate a referral report for primary-to-care transitions. The report included patient demographics, medical history, chief complaints, symptoms, family history, suggested investigations, preliminary diagnoses, treatment recommendations and a brief summary aligned with clinical reasoning documentation assessment tools (Supplementary Table 4).
Accessibility and clinical utility
To ensure accessibility, the platform supports shared access for patients and their caregivers52. An LLM-driven agent performs real-time intention analysis to facilitate empathetic communication and simplify language for low-literacy users, with outputs formatted as JSON for streamlined processing.
To improve clinical utility under time constraints, the model was optimized to balance comprehensive data gathering with clinical time constraints, targeting 8–10 conversational turns based on local stakeholder feedback. Primary care physician input drove the incorporation of high-yield inquiry strategies, which in pilot testing reduced consultation times by approximately half (within 4 min).
Human interaction refinement
In the adversarial stakeholder testing cycle, we employed prompt augmentation and agent techniques to refine the model, aligning the chatbot with WHO guidelines for ethical AI in primary care while preserving clinical validity53. An evaluation panel consisting of community and clinical stakeholders and one AI-ethics-trained graduate student, conducted iterative feedback cycles, focusing on mitigating harmful, biased or noncompliant outputs via adversarial testing.
Virtual patient interaction refinement
In the simulation-based refinement cycle, we used bidirectional exchanges between PreA and a synthetic patient agent to enhance consultation quality. We synthesized 600 virtual patient profiles using LLMs grounded in real-world cases; 50% (n = 300) required interdisciplinary consultation to reflect complex care needs. Five board-certified clinicians validated all profiles for medical plausibility and completeness (achieving 5 of 5 consensus).
The patient agent was built on a knowledge graph architecture54, formalizing patient attributes (demographics, medical history and disease states) as interconnected nodes. The agent was further instructed to emulate common consultation challenges identified by community stakeholders in the first cycle. Interactions concluded automatically upon patient acknowledgment or after ten unresolved inquiry cycles. We randomly chose 300 profiles for refinement and reserved the remainder for comparative simulation studies.
Evaluation metrics
The co-design process identified five consultation quality domains for refinement: efficiency (meeting the patient’s demanding time lengths), needs identification (accurate recognition of patient concerns), clarity (concise and clear inquiries and responses), comprehensiveness (thoroughness of information) and friendliness (a respectful and empathetic tone).
PreA’s performance was rated across these metrics by a panel of five experts (two primary care physicians, two specialists (one in internal medicine and the other in surgical medicine) and one AI-ethics-trained graduate student). Separately, two primary care physicians assessed referral reports for completeness, appropriateness and clinical relevance using a co-designed, five-point Likert scale (Supplementary Table 5). Scores below 3 triggered further iterative refinement.
Comparative simulation study with virtual patients
We collected audio recordings of primary care consultations from rural clinics and urban community health centers across the 11 Chinese provinces. Provinces were categorized as low-income and high-income based on whether per capita disposable income was below or above the national average (National Bureau of Statistics of China). Local co-design team members who live in these areas manually calibrated the transcripts to ensure validity, as the raw data contained noisy, ambiguous language, interruptions, ungrammatical utterances, nonclinical discourse and implicit references to physical examinations. All conversational data collected was rigorously de-identified in compliance with relevant regulatory standards (HIPAA) before data analysis.
We conducted a comparative simulation study to evaluate the incremental utility of integrating these localized dialogues. Two model variants were compared: the co-designed PreA model and a local data-tuned counterpart, created by fine-tuning the PreA model (OpenAI; ChatGPT-4.0 mini) on the processed primary care dialogues. Notably, the data fine-tuning, applied directly to the base LLM, inherently exerted a higher behavioral priority than the agent techniques and prompting strategies co-designed to instruct the model. Consequently, when behavioral cues conflicted, the model would preferentially adhere to patterns learned from the fine-tuning data.
The virtual patient experiment utilized 300 unused patient profiles to evaluate clinical decision impacts (history-taking, diagnosis and test ordering). Referral reports from both variants were blindly evaluated by the same expert panels as in the PreA development, using validated five-point Likert scales for completeness, appropriateness, and clinical relevance (Supplementary Table 5). Inter-rater reliability for these assessments was high (κ > 0.80), and group comparisons were conducted using the two-tailed nonparametric Mann–Whitney U-tests.
Randomized controlled trial
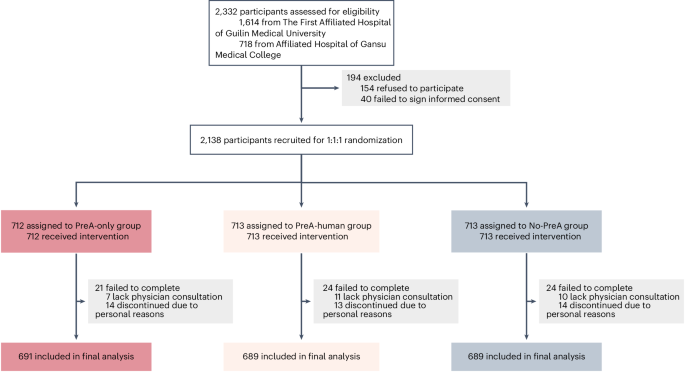
In this pragmatic, multicenter RCT, patients were randomized to use PreA independently (PreA-only), with staff support (PreA-human) or not use it (No-PreA) before specialist consultation. The PreA-human arm was included to assess PreA’s autonomous capacity. The primary comparison was between the PreA-only and No-PreA arms, with a secondary comparison between PreA-only and PreA-human arms. The trial’s primary end points were to evaluate the effectiveness of the PreA in enhancing operational efficiency and patient-centered care delivery in high-volume hospital settings, as measured by consultation duration, care coordination, and ease of communication. The PreA chatbot used in the RCT was frozen before patient enrolment. Examples of patient interaction with PreA are provided in Supplementary Tables 6–8.
Participants
Participants must demonstrate a need for health consultation or express a willingness to engage in PreA health consultations. Other inclusion criteria were (1) aged between 20 years and 80 years; (2) visit the participating physicians at the study medical centers; (3) eligible for communicative interaction via mobile phone; (4) eligible to complete the post-consultation questionnaires; and (5) have signed informed consent. Exclusion criteria were (1) the presence of psychological disorders; (2) any other medical events that are determined ineligible for LLM-based conversation; and (3) refusal to sign informed consent. No co-design stakeholders participated in the RCT.
Intervention and comparators
Participants were randomly assigned to one of three study arms: (1) the PreA-only group, independently interacting with the PreA via mobile phone before their physician consultation; (2) the PreA-human group, interacting with the PreA under the guidance of a medical assistant; and (3) the control group, receiving standard physician-only care (No-PreA). In the PreA-human group, participants were informed that PreA’s interface was similar to WeChat, which has been used by hospitals for patient portal registries and hospital visit payments, and were offered technical support. Participants in the PreA-only arm used the tool independently without assistance.
For both PreA-assisted arms, a PreA-generated referral report was provided to specialist physicians for review via the patient’s mobile phone before any face-to-face interaction. This design was implemented to prevent direct copying of content into clinical notes. Physicians were requested to rate the report’s value for facilitating care. In the No-PreA control arm, physicians reviewed routine reports containing only patient sex and age.
Following consultations, patient and care partner experiences were captured via a post-consultation questionnaire (Supplementary Table 1). Physicians provided feedback at the end of their shifts (Supplementary Table 2).
Outcomes
The primary outcomes were consultation duration, physician-rated care coordination, and patient-rated ease of communication. These metrics were selected based on co-design feedback, which identified time efficiency and care coordination as critical for adoption in high-workload settings, and are established proxies for clinical effectiveness and patient-centered care38.
Secondary outcomes included physician workload (measured as patients seen per shift and compared between participating and matched nonparticipating physicians); patient-reported experiences of physician attentiveness, satisfaction, interpersonal regard and future acceptability; physician-reported assessments of PreA’s utility, ease of communication, and workload relief; and clinical decision-making patterns, derived from a quantitative analysis of clinical notes.
Consultation duration, patient volume and clinical notes were extracted from the PreA platform and hospital electronic records. Physician-perceived care coordination was measured via a five-point Likert scale rating the helpfulness of the PreA report in facilitating care. Patient-reported and other physician-reported outcomes were collected using prespecified, five-point Likert scale questionnaires (Supplementary Tables 1 and 2). These instruments demonstrated robust internal consistency (Cronbach’s α > 0.80 for all domains) and face validity, established through iterative feedback from 20 laypersons and five clinicians to ensure relevance to outpatient contexts. Clinical notes were extracted from all three trial arms and included five core clinical reasoning domains: history-taking (chief complaint, history of present illness and past medical history), physical examination, diagnosis, test ordering and treatment plans.
Sample size
The sample size was calculated for the primary comparison between the PreA-only and No-PreA arms. The target minimum sample size of 2,010 participants (670 per study arm) was prespecified based on a power analysis using preliminary data from the pilot study of 90 patients. This minimum target sample size ensured sufficient power (>80%) for the primary outcome at a significance level of 0.05.
Recruitment
The clinical research team approached adult patients from waiting rooms who were scheduled to see the participating physicians. For pediatric patients or adults without a mobile device, their caregivers were contacted. Interested individuals received a comprehensive study description, which emphasized the exploratory nature of the research and clarified that any advice rendered by PreA serves solely as a reference and should not be utilized as a definitive basis for disease therapy. After providing informed consent and having their questions addressed, eligible individuals who met the inclusion and exclusion criteria were formally enrolled. Recruitment was conducted from 8 Feb to 30 April 2025.
Randomization and blinding
Participants were allocated to one of the three groups using an individual-level, computer-generated randomization sequence without stratification. Allocation was concealed to prevent selection bias. This trial was single-blinded: while the patients knew their group assignments (PreA-only, PreA-human, or No-PreA), the physicians were uninformed about the PreA-intervention groups (PreA-only or PreA-human). Furthermore, research staff involved in data analysis remained blinded to group assignments throughout the study.
Statistical analysis
Analysis of healthcare delivery
We assessed baseline covariate balance across the three groups using an ANOVA for continuous variables and a chi-squared test for categorical variables. For intergroup comparisons, we evaluated the distribution of scale values; two-sample Student’s t-tests with unequal variances were used for approximately normal data, while a nonparametric Mann–Whitney U-test was applied to skewed distributions. All tests were two-tailed with a significance threshold of P < 0.05. The Benjamini–Hochberg procedure was applied to correct for multiple comparisons. The relative treatment effect for the primary comparison (PreA-only versus No-PreA) was calculated as the difference in means divided by the mean of the No-PreA group. Secondary analyses evaluated the consistency of findings across demographic and socioeconomic subgroups. Python v.3.7 and R v.4.3.0 were used to perform the statistical analyses and present the results.
We conducted a matched-pairs analysis to assess the impact of PreA on physician workload. Matching criteria included medical specialty, working shift, age group (≤45 years and >45 years), sex, and professional title (chief, associate chief and attending). The outcome is the number of patients seen per clinical shift. A second matched-pairs analysis was conducted to assess the effect on patient waiting times. For this analysis, we matched participating physicians to a distinct control group on the same covariates (replacing working shift with working week to accommodate the matching on patient volume) and the number of patients seen per shift. For both analyses, statistical significance between participating physicians and their matched controls was assessed using two-sided Wilcoxon signed-rank tests to account for matched data.
Analysis of clinical notes
We performed a prespecified classification analysis to detect systematic differences between clinical notes from PreA-assisted arms (PreA-only and PreA-human groups) and the No-PreA arm. A randomly selected subset of notes (PreA-only, n = 291; PreA-human, n = 285; No-PreA, n = 300) was retrieved in compliance with hospital data privacy rules. Notes were partitioned into training and test sets (2:1 ratio). A binary classifier was trained to distinguish PreA-assisted from No-PreA notes, with classification performance evaluated using the F1 score, defined as the harmonic mean of precision and recall F1 Score=TP/(2TP + FP + FN), where TP, FP and FN denote true positives, false positives and false negatives, respectively. Under the null hypothesis of no intergroup differences, classifier performance would be random. A statistically significant F1 score exceeding this baseline (ΔF1 > 0.02) would indicate distinguishable clinical decision-making patterns attributable to PreA-assisted notes.
The classifier was trained in two stages. First, a Med-BERT encoder generated contextualized embeddings of the clinical notes55. Second, a binary classification layer was trained on these embeddings using supervised SimCSE56, a contrastive learning approach that minimized embedding distance within the PreA-assisted group while maximizing the distance to the No-PreA group. Statistical significance was assessed with one-sided bootstrap tests (1,000 samples).
A prespecified domain-specific analysis further compared clinical decision-making across five domains. For unstructured text (history-taking and physical examination), Med-BERT embeddings were generated and projected into a two-dimensional latent space (UMAP1 and UMAP2) via Uniform Manifold Approximation and Projection for comparative distribution analysis. For structured non-normal count data (number of diagnoses, number of tests ordered and number of treatments), documented counts were compared between groups using nonparametric Mann–Whitney U-tests.
Comparison of referral report with clinical notes
A post hoc analysis evaluated the concordance and quality of PreA-generated referral reports versus physician-authored clinical notes. Agreement was defined as substantial alignment (exact match, near-identical content or inclusion of accepted differential diagnoses). The same expert panel from the comparative simulation studies (two board-certified primary care physicians and two senior residents) performed blinded ratings of report and note quality on a five-point Likert scale for completeness, appropriateness and clinical relevance (Supplementary Table 3). They assessed three domains relevant to primary care referrals: history-taking, diagnosis and test ordering; physical examination and treatment plans were excluded. Each case was evaluated by two experts. The analysis used the same subset of patient cases as the classification analysis. Inter-rater reliability was high (κ > 0.80). Group comparisons were performed using a nonparametric Mann–Whitney U-test.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.