

Key Takeaways
AI/ML and agentic tools are getting better at helping design and compile FPGAs, but downstream programming is slower to benefit.
FPGAs historically have been designed using Verilog or VHDL, but higher-level languages could push more intelligence into compilers.
ML tools can also help with mixed-signal co-design by automatically tuning DSP algorithms based on analog simulation data.
AI is beginning to make inroads into designing and managing programmable logic, where it can be used to simplify and speed up portions of the design process.
FPGAs and DSPs are still not as efficient as hard-wired chips, but they remain extremely useful in such markets as life sciences, AI processing, automotive, and 5G/6G chips, where change is almost constant. Field programmability provides future-proofing for new protocols and standards, as well as for modifications to architectures, and it serves as a sort of blank canvas into which any workload can be inserted.
“There is a programmable I/O ring that sits around the chip, and you can take any type of I/O that can come in and translate it into something that can be made into post-processing and workload-specific engines within that fabric,” said Venkat Yadavalli, head of the Business Management Group at Altera.
But designing FPGAs, eFGPAs, and DSPs is both complex and time-consuming. “There’s a case for FPGAs to be used more widely than just in prototyping, in a particular function,” said Andy Nightingale, vice president of product management and marketing at Arteris. “In reducing memory and I/O bottlenecks, they’re ideal. But it’s still quite a complex job to program FPGAs. You need RTL skills to program an FPGA versus programming software to run on the GPU to do a similar task.”
While FPGA engineers have optimized the way the bit streams go in and out, it requires a different software stack to manage it. “Companies such as Xilinx (now part of AMD) and Altera have built their core CPU clusters that bring them some more programmability, along with their FPGA fabric,” observed Nandan Nayampally, chief commercial officer at Baya Systems. “They’re trying to solve some of those programming problems, but it’s very difficult to do a generic thing that goes across GPU, CPU, and FPGA. The more different software stacks you have, the more difficult it is to move faster.”
Today, all of that is managed by a software abstraction. “The programmability is controlled by the software layer that sits on top of it,” said Yadavalli. “For FPGAs, we have a state-of-the-art tool that can take a workload, synthesize the workload, place the workload, and pack it in a way that you get the most power, area, and the best FPGA target that you can put in to get there. That tooling becomes the biggest competitive moat, and that’s why there are not many people who can break through that, to really go and implement it. Chips can be built by anybody, but having a sophisticated software that gets it in [is hard], and that sophistication depends on how wide you want it to be and the different types of programmability that you want to bring in.”
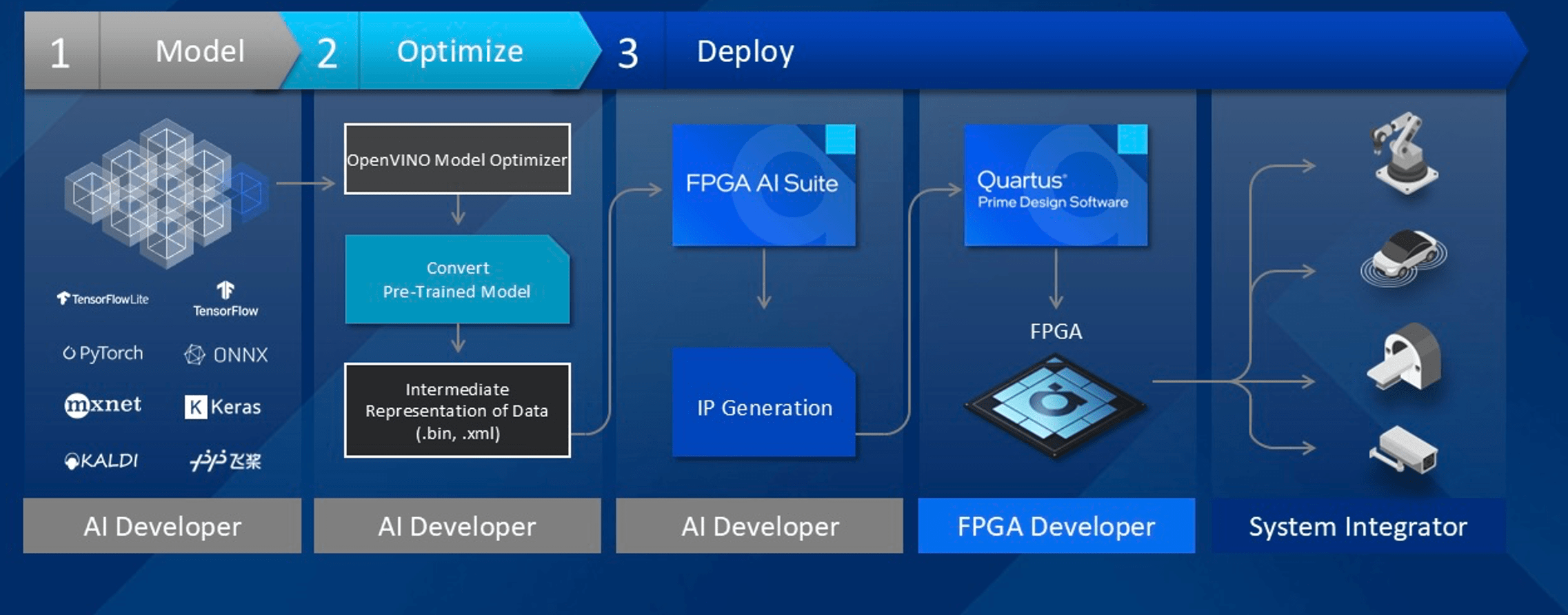
Fig. 1: FPGA AI development flow. Source: Altera
Looking ahead, agentic AI is expected to help speed up FPGA design, although it won’t necessarily help users program the FPGAs for their products. “We are excited about AI opportunities that are ahead of us, which allows us to not be a ninja FPGA designer or a ninja ASIC designer,” said Yadavalli. “There are agents that can convert my coding into vibe coding, where I can go in and input this information through either voice or with diagrams or schematics, you name it, and it goes through multiple rounds to spit out something that is final code. That’s the Nirvana state. We are not here with agentic AI yet, but I’m seeing that as an opportunity that encourages more people to come in and innovate on these platforms.”
AI adds complications
At the same time, there are challenges for first-time FPGA users, as well as for users who are familiar with FPGAs and are adding AI into the mix. “Programming FPGAs has gotten easier over time with things like high-level synthesis,” said Rob Bauer, senior manager of the product marketing, adaptive, and embedded group, at AMD. “There are certain tools that engineering teams are using for algorithmic or C code down into RTL. From a tool flow perspective, we have capabilities such as Vitis AI that help bridge the gap between, say, a PyTorch model into the AI engine. That’s critical so users can quickly deploy AI into the silicon. That has certainly got easier.”
Bauer has not yet seen a lot of AI-based RTL-generation code assistance. “But in terms of taking an AI workload and putting it in the chip, that’s gotten a lot easier as we figure out what models we need to support and then work on compiler optimizations, quantizer, etc., to get down into the chip,” he said.
Others are seeing agents generating RTL. “For programmable components like FPGAs, AI-native compilers and agents infer intent from high-level code or natural language, generate RTL or HLS, and automatically optimize mapping, pipelining, and timing closure,” said William Wang, founder and CEO of ChipAgents. “Compilers are shifting to adaptive pipelines that optimize kernels, memory layout, parallelism, and scheduling in real-time as model architectures and operators change.”
Adding a discrete or embedded FPGA to an SoC is not necessarily difficult, but expertise is needed to make it all work — and with AI. “Your downstream customer has a challenge of, ‘What used to be purely a software job now involves designing some hardware that’s going to go in that FPGA,’ and that’s a bit daunting,” said Russell Klein, program director at Siemens EDA. “Suddenly we’ve got this interest in, ‘We’ve got this algorithm, it needs to go into that FPGA, and we might not have seasoned hardware designers to do it. Can we start looking at taking these algorithms and using the tooling that can take a C function?’ This is instead of speeding up the design work, which is traditionally where high-level synthesis has played a role, so we’re starting to look at some limited Python and being able to take that and compile it into the FPGA fabric. While traditionally you design an FPGA using Verilog or VHDL, there are higher-level approaches that are going to be a lot closer to what software developers need to be able to do to move things into the FPGA fabric and take advantage of that power/performance capability.”
Another approach is to make the compiler smarter, putting more intelligence into it. “That way we can remove as much of that hardware design knowledge that’s necessary to be able to program those FPGA devices,” said Klein. “But we’re not at that point yet. [AMD] isn’t. Nobody in this space has an offering where a software guy can naively turn the crank on the compiler and get output. It requires some understanding of hardware design and data flow. It’s not that software people can’t learn these things. They absolutely can. It is possible for software people to start to look at this technology, start to understand it, and with some training be able to move these algorithms off the CPUs into the programmable logic. In the long term, this just becomes an extension of programming. ‘I’m going to write a program. Do I compile this to run on the CPU? Do I compile it to run on the GPU? Or do I compile it to run on the FPGA fabric?’ That’s the very long-term vision. Everybody who’s playing in this space is making progress in that direction.”
One challenge is optimizing the FPGA for a specific workload, with the optimal power versus performance versus latency. “That is still a balance, because in the embedded space you want to optimize for cost as much as possible,” said Bauer. “You could take these models and run them on your laptop, but it’s not going to deliver the performance that you need in an edge system.”
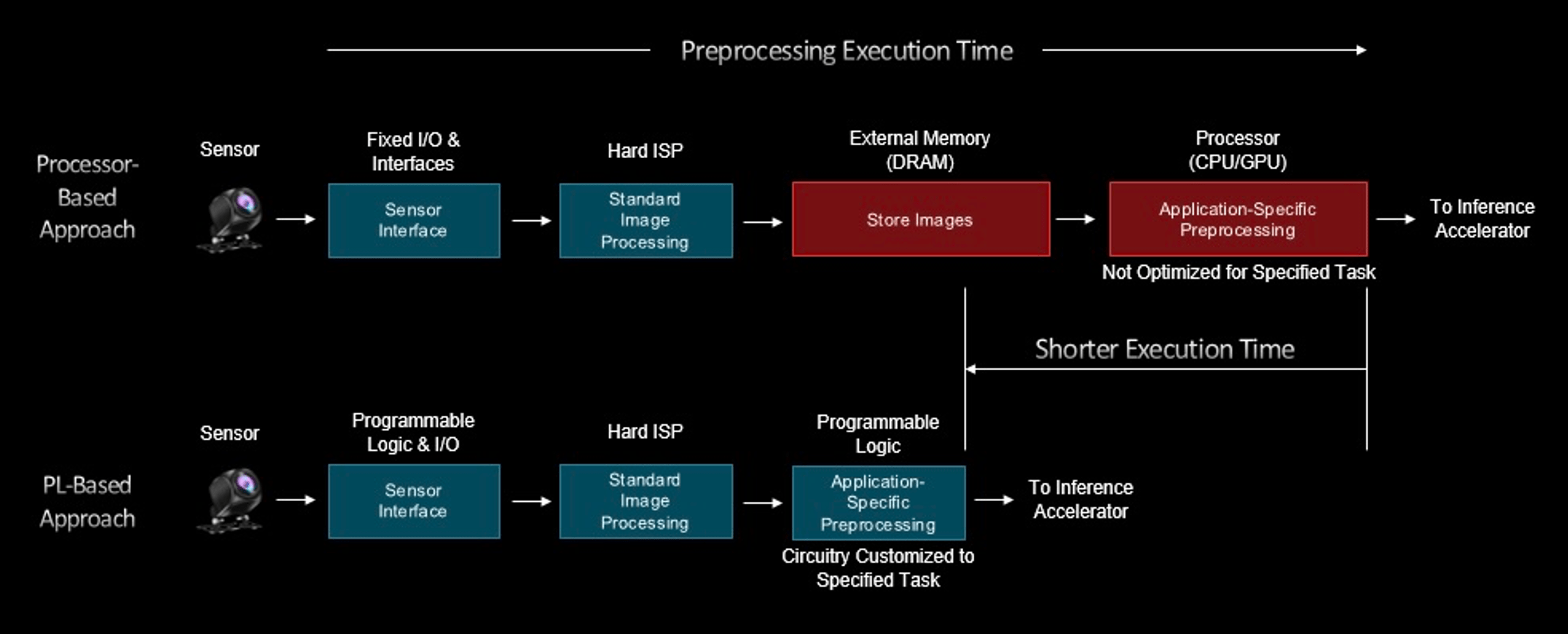
Fig. 2: Pre-processing time in programmable logic vs. processors, where green is low latency, deterministic, and red is high latency, non-deterministic. Source: AMD
There’s a learning curve to deploy the AI, test it, and make sure everything’s working correctly. “Things are moving so quickly that the model you use today and evaluate today could be obsolete,” said Bauer. “There could be a better model a year down the road, so you need something you can quickly adapt with. Different people are going to struggle with different things depending on the problem they’re trying to solve.”
Shifting workloads and the role of programmability in AI models
If a designer knows exactly what model they are running, they design a very efficient AI accelerator to solve that problem, Baya’s Nayampally said. “Models change, so you need some programmability. Then, depending on the architecture of the accelerator, you have to add the software stack that abstracts it so enough that people don’t have to relearn every time.”
Because the future remains unknown, some level of programmability is essential. “If you look at what Nvidia has done, it’s still a GPU with acceleration,” said Nayampally. “There is a lot of programmability. CUDA is what made them successful. How fast you can make that programmability in an optimization is what’s driving success.”
As the landscape continues to evolve, these considerations highlight the dynamic interplay between programmability, efficiency, and adaptability in FPGA and AI system design. Still, while optimization is a key concern, the speed at which AI models are changing is starting to level off.
“Four or five years ago, when people were developing compilers for machine learning or AI workloads, they were fascinated by the possibility of a good compiler that could take any AI model architecture and convert it to an intermediate representation that is very efficient,” said Kexun Zhang, head of research at ChipAgents. “But the effort going in that direction for smart compilers for AI models has become much less today, because the most important workload, or the largest amount of work for AI, is no longer people developing different model architectures and trying them out one by one. That was when people needed the compilers, because they needed to speed up all these different, strange, random architectures that people came up with.”
One of the most important workloads today is matrix multiplication performed by transformers, or the architecture underlying language models. “At least for language models, we don’t really need the hardware to be that programmable, because they only need to deal with one type of workload,” said Zhang.
A designer’s choice of programming language can impact efficiency, as well. “This is a problem in general, if you write your code with high-level languages like Python, you always will lose power,” said Andy Heinig, head of the Department for Efficient Electronics at Fraunhofer IIS’ Engineering of Adaptive Systems Division. “The power efficiency of these languages isn’t as good as if you write in embedded or in C, C++.”
So while high-level languages can make programming easier, they may mean you lose power efficiency. “From that perspective, we are quite sure that hardware-software co-design is the way to save most of the energy, but we are not seeing that happen because we need more abstraction to solve these issues,” Heinig noted.
FPGA design developments
In FPGA design, one challenge lies in creating tools flexible enough to serve vastly different applications. This has been partly solved by accessible and integrated software flows that enable AI developers, FPGA engineers, and embedded or SoC developers to collaborate within a unified design environment, Altera’s Yadavalli noted.
Analysis is getting easier, too. “New power and thermal analysis tools have become far more precise, providing intelligent recommendations to help designers better manage energy use and thermal constraints throughout the design and board layout process,” Yadavalli said.
While nominally digital, FPGAs are analyzed at a very analog level, similar to memory, CMOS, and image sensors. “FPGA is only digital, but the analysis of how those fuses work and how the resistance and the components are analyzed, because it’s a repetitive structure, can be done on a very deep level on each unit, and then that gets repeated,” said Marc Swinnen, director of product marketing at Synopsys. “That analysis has a lot of analog aspects to it. The power delivery, the signal integrity, all of that has analog components to it, especially at high speed. The problem with all these components that have analog aspects of their analysis is that they are very large. But analog designs are traditionally small, and the tools are traditionally designed for small designs.”
New cloud-based tools and better infrastructure have enabled FPGA designers to analyze their full designs in full detail like never before, Swinnen said.
Designing and deploying DSPs
FPGAs aren’t the only programmable hardware option, or the only option challenged by AI. While AI makes it easier to design DSPs, there are rising complexities due to the increase in analog information from real-world sensors.
“Machine learning can help with mixed-signal co-design by automatically tuning DSP algorithms based on analog simulation data,” said Amol Borkar, senior director of product management and marketing, head of computer vision/AI products at Cadence. “This reduces design cycles and helps engineers find the right balance between analog precision and DSP complexity.”
This complexity is leading to changes in how design teams approach analog and digital. “In the past, these worlds were separate, but now they need to work together,” Borkar noted.
Power and area tradeoffs are also front and center. “Analog blocks are efficient but hard to scale, while DSP-based fixes can improve performance but cost more in power and silicon,” Borkar explained. “Designers need to strike a balance. Do you go with a high-resolution ADC to simplify DSP work, or a lower-resolution ADC and let the DSP do more heavy lifting?”
In edge AI deployment, developers must know what workloads to run on a traditional DSP versus a vector extension, such as Arm’s Helium, optimized for ML on low-power embedded devices. On a fitness watch, for example, a high percentage of the audio processing is done on traditional DSP while a significant portion of pre-processing is done on a DSP Helium extension on an Arm Cortex M55 MCU, explained Steven Tateosian, senior vice president of the IoT, Compute & Wireless Business Unit at Infineon Technologies. “The use case for that DSP is different than the audio processing. It becomes more of a pre- and post- filtering use case.”
The same questions apply to vehicles. “AI does not solve your segmentation problem or your system architecture problem,” said Thomas Rosteck, division president and CEO of connected secure systems at Infineon. “It provides you with a different way to analyze the data and then provide the feedback.”
Memory compilers
As AI models become more sophisticated and the industry shifts toward a software-first design methodology, advanced memory compilers are increasingly needed.
“Chip architects now prioritize software algorithm requirements, especially those for machine learning and data analytics, before finalizing hardware specifications,” said Daryl Seitzer, principal product manager for embedded memory IP at Synopsys. “The ability to quickly adapt memory architectures to support unique AI algorithms has become a key differentiator for chip designers. This shift drives the need for memory compilers that deliver flexible and scalable embedded memory solutions. As AI applications grow in complexity, there is an increasing reliance on specialized data structures resulting in more frequent and parallel access to large datasets, and memory compilers must now support features to accommodate these new software-driven demands.”
The latest generation of memory compilers offers highly flexible configurations, ultra-low voltage support, and a wide range of multi-port options, which gives chip designers confidence that their memory IP can quickly adapt to changes in algorithm requirements. “AI-targeted memory features include transposed dataflows, power optimized designs for applications with data sparsity, and MAC unit pitch-matching,” Seitzer added.
Conclusion
FPGAs, DSPs, and other programmable chips play an increasingly important part in the chip landscape, where applications demand a complex mix of processors to achieve specific goals. New tools are making it easier for designers and customers to take advantage of programmability as AI models and applications continue to evolve.
“FPGAs are driven by the technical architects deciding which portions are something that is applicable to FPGA technology and which portions are applicable to GPUs, an ASIC, or another chip,” said Altera’s Yadavalli. “That upfront discussion is what we call an architectural phase. People will look into it and partition the design to say, Which part of the data plane needs to be organized through FPGAs? Which part of the control plane needs to be set up the way it needs to be? Most importantly, does the total cost of ownership of this implementation make sense while balancing the needs of the market and the market evolution that is about to happen?”
The main parameters that go in favor of FPGAs are I/O flexibility, deterministic latency or low latency, security flexibility, and the ability to consolidate different workloads that you don’t necessarily have control over. “You can architect your risk profile in a way that it makes sense from a platform level on how the workload can be easily orchestrated and arbitrated,” said Yadavalli. “Then, eventually, it has to make sense to the software layer that comes on top of it. It’s a good software-hardware co-design.”
Related Reading
Programmable Chips Evolve For Shifting Needs
Designers are utilizing an array of programmable or configurable ICs to keep pace with rapidly changing technology and AI. DSPs remain key.
FPGAs Find New Workloads In The High-Speed AI Era
Growing use cases include life science AI, reducing memory and I/O bottlenecks, data prepping, wireless networking, and as insurance for evolving protocols.